A New Gemini Variant Built for Sub-Second Decisions
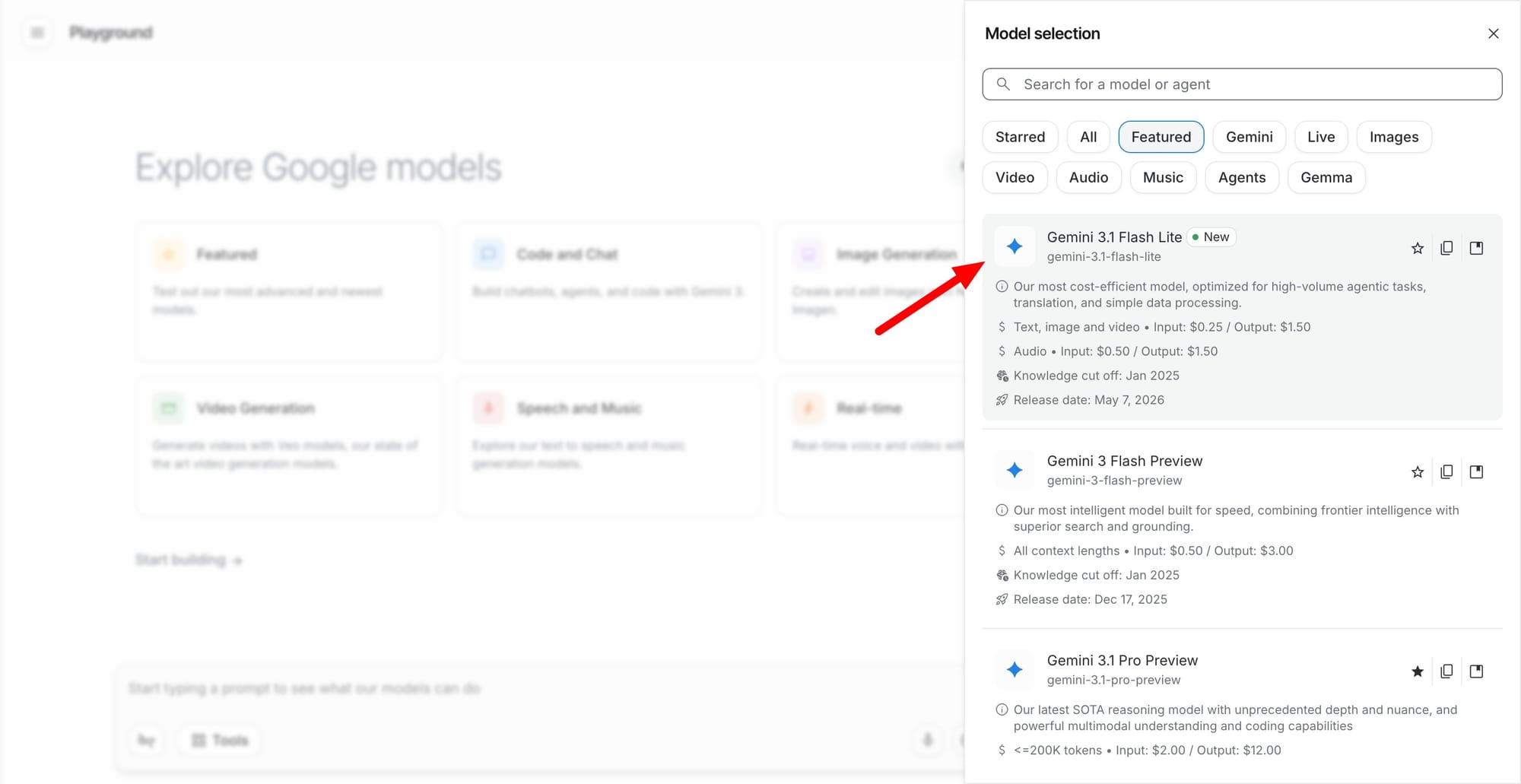
Gemini 3.1 Flash-Lite is Google’s latest entrant in the Gemini 3 series, but it’s not chasing frontier-model glory. Instead, it is tuned for ultra-low latency and high-volume processing on Google Cloud AI, targeting workloads that demand instant responses rather than maximal reasoning depth. Google positions Flash-Lite as its most cost-efficient and fastest Gemini 3 model, reporting sub-second response times for classification tasks and a p95 latency around 1.8 seconds for full reply generation under heavy concurrent loads. By moving this model into General Availability, Google is signaling that Flash-Lite is ready for production, not just experimentation. This emphasis on predictable, low latency AI models directly addresses developers who care more about throughput, stability, and SLA adherence than squeezing out marginal gains in benchmark scores, especially in systems where every extra second visibly degrades user experience.
Multimodal and Tool-Aware: Designed for Real Workflows
Beyond raw speed, Gemini 3.1 Flash-Lite supports both text and image processing, allowing teams to build multimodal AI workflows without switching models mid-pipeline. Early adopters report using Flash-Lite for agentic tasks such as tool calling and orchestration, where the model’s job is to route requests, invoke APIs, and coordinate steps rather than write essays. That combination of low latency and tool awareness makes it attractive for environments like integrated development tools, helpdesk systems, and financial automation, where models must continuously query external systems and respond in near real time. Because Flash-Lite runs on Google Cloud AI infrastructure, it slots into existing enterprise stacks alongside logging, observability, and governance tools. The result is an AI layer that behaves less like a demo model and more like a dependable service that can be wired into complex, multi-step business workflows at scale.
Why Speed-First Models Matter More Than Benchmark Bragging Rights
The broader AI race has revolved around headline-grabbing models that edge up leaderboard rankings. Yet developers rarely rebuild production systems just because a model is slightly smarter on paper. They switch when a model saves time, reduces cleanup work, and stays reliable inside messy, long-running projects. Industry commentary around Google’s Gemini efforts highlights this reality, especially in coding and agentic use cases where skepticism is high and evaluation is ruthless. In that context, Gemini 3.1 Flash-Lite represents a deliberate pivot: it trades some raw capability for predictable performance, low latency, and affordability. Google appears to be carving out a speed-focused segment where the winning metric is not maximum IQ, but minimum wait time under load. For many teams, a model that answers fast and consistently is more valuable than one that occasionally dazzles but slows down or fails at scale.

Who Benefits Most from Gemini 3.1 Flash-Lite?
Flash-Lite’s design clearly targets organizations that live and die by real-time responses. Customer service platforms can use it to power chat assistants and routing engines that must handle high-volume processing without queue buildup. Software engineering tools can integrate the model for fast code suggestions and diagnostics that feel instant inside an IDE, where latency directly affects developer flow. Financial services and creative applications gain an engine capable of rapid classification, content moderation, or lightweight generation over large streams of inputs. Early enterprise adopters show that the model’s balance of speed, cost efficiency, and adequate cognitive performance can support production-scale operations without degrading quality. With General Availability on Google Cloud AI, teams no longer need to prototype on one model and deploy on another—they can ship real-time, multimodal, tool-calling agents using a single, consistently low-latency backbone.