What the ADHD Prompt Method Claims to Do
The ADHD prompt method for Claude is a third-party reasoning layer that runs multiple divergent thought branches in parallel, scores them under different cognitive frames, prunes weaker options, and then deepens the most promising paths to improve AI reasoning and planning on complex tasks. Solo researcher Udit Akhouri introduced ADHD as a skill for coding agents built on the Claude Agent SDK, marketing it with the bold line: “I gave Claude Code ADHD… and it thinks 2x better now.” On GitHub and Reddit’s r/ClaudeCode, the tool is explained as “tree-of-thought with cognitive-frame branching, generator-critic separation, and pruning,” aimed at brainstorming architecture and research decisions rather than faster coding output. In practice, ADHD tries to widen Claude’s reasoning search space, then narrow it again, fitting into a broader wave of Claude prompting techniques that promise structured AI reasoning improvement.

How ADHD Prompting Works Under the Hood
ADHD sits on top of Claude as a composable agent layer rather than a hidden feature. It “fans out parallel divergent thoughts under different cognitive frames, scores, prunes traps, [and] deepens the survivors,” turning a single query into a small forest of reasoning paths that are then evaluated. Akhouri positions it as a planning and reasoning substrate for agents, particularly for systems design and research workflows, where breadth and trap detection matter more than short snippets of code. While parallel sampling is not new, ADHD packages it in a way that emphasizes transparency: end users can see and adjust how many branches run, how they are scored, and how Claude benchmarks itself. Andrew Moore describes the “genuinely new idea” as finding another way to create diversity across those parallel thinkers, contrasting with more opaque agent teams or GPT Pro-style parallel evaluation patterns.
The 2x Claim: What the Current Benchmarks Really Show
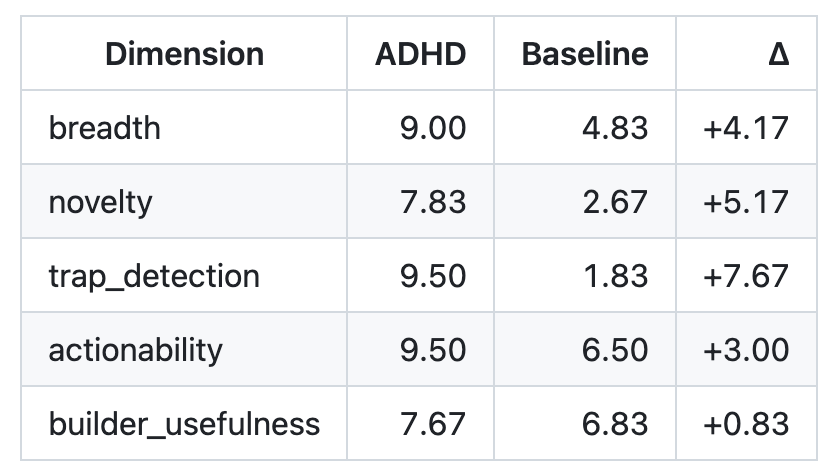
The headline promise is that this ADHD prompt method makes Claude “2x better,” based on six engineering-style eval problems. On GitHub, Akhouri reports ADHD outscoring a baseline Claude agent on five of six tasks across breadth, novelty, trap_detection, actionability, and builder_usefulness, with deltas like +4.17 for breadth and +7.67 for trap_detection. He says the average improvement across dimensions yields the “2x” framing and notes that npm run evals can reproduce the tests. Yet these Claude benchmarks are narrow: only six open-ended problems, judged within the same Claude model family. As critics point out, removing the heavily weighted trap_detection metric shrinks the average from 2.52x to 1.85x. The results hint at AI reasoning improvement, but they look more like an encouraging pilot than proof of a general, quantifiable doubling of capability.
Why Experts Are Skeptical of the Evidence
Outside experts see promise but question whether the ADHD prompt method proves a real, reliable jump in reasoning. Sean Robinson notes that ADHD resembles familiar parallel sampling and selection patterns, and argues that “a ‘2x better’ claim needs more than a few open-ended wins. It needs a validated evaluation set, multiple judges, ablations, and evidence that the method improves without just rewarding verbosity, novelty, or branch diversity.” Noe Ramos echoes this, warning that gains in novelty or trap detection are not yet stable without inter-rater reliability. There is also concern about same-stack bias: Claude judging a Claude-based method could inflate scores. Some researchers view ADHD as “yet another exploration method sitting on top of LLMs,” useful but expensive in tokens, and not yet distinguished by rigorous, model-agnostic testing or peer-reviewed validation.
What Robust Verification of Claude Prompting Techniques Would Require
For ADHD prompting—or any Claude prompting technique—to be viewed as a solid AI reasoning improvement method, experts say the field needs stronger, shared testing norms. That would mean larger, diverse benchmark suites of real engineering and planning problems; multiple independent judges, including models from other families; and ablation studies that isolate which parts of the ADHD prompt method matter. Results would have to hold up across tasks, not just six hand-picked scenarios, and avoid rewarding wordiness or branch count instead of genuine solution quality. Transparent, open-source eval harnesses like Akhouri’s npm run evals are a good start, but viral claims need reproducible, third-party audits before numbers like “2x better” can be trusted. The ADHD debate underlines the need for common Claude benchmarks and reproducible standards before social media hype turns experimental techniques into accepted practice.





