What Local AI Agents on RTX Spark Are and Why They Matter
Local AI agents setup on an RTX Spark Windows PC means installing and configuring AI assistants that run entirely on your own hardware, using local models and secure runtimes to automate tasks, generate content, and control applications without sending data to external cloud services. NVIDIA RTX Spark PCs are built for this role, combining up to 1 petaflop of AI power with up to 128GB of unified memory to keep agents fast and responsive. NVIDIA describes RTX Spark as a platform that can shift the PC “from tool to teammate,” handling agentic workloads alongside creative production and high-performance gaming. Because everything runs locally, you gain stronger privacy, lower latency, and no dependence on internet connectivity for core agent tasks, while still keeping the option to selectively connect to cloud services when you choose.
Prepare Your RTX Spark Windows PC for Offline AI Deployment
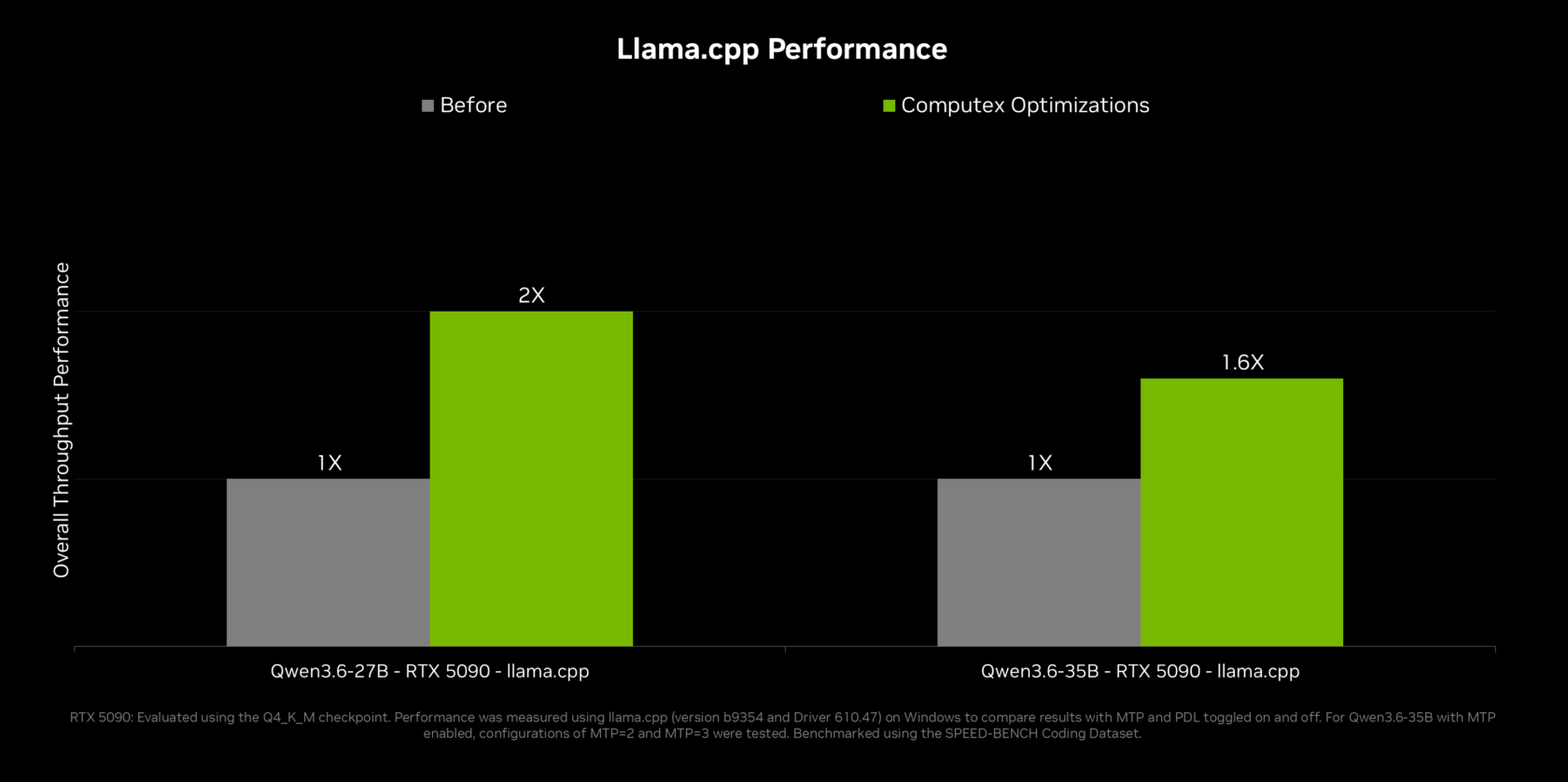
Before configuring OpenShell AI agents, confirm that your RTX Spark Windows PC is ready for offline AI deployment. Ensure Windows is fully updated so it includes Microsoft’s new security primitives for agents, which add identity, containment, policy, and end-to-end security for on-device workloads. Install the latest NVIDIA drivers and RTX utilities so CUDA, TensorRT, and other AI features are available. These underpin the performance gains that make agentic models usable day to day. For users who want open models, install tools such as llama.cpp or LM Studio, which already integrate NVIDIA optimizations. NVIDIA reports that its work with llama.cpp, including multi-token prediction and programmatic dependent launch, delivers up to 2x performance on Qwen 3.6 and 3.5 27B models on GeForce RTX GPUs. This foundation lets your local agents respond quickly even with large models.
Install OpenShell and Configure Secure On-Device AI Agents
With the system prepared, the next step in local AI agents setup is to install the NVIDIA OpenShell runtime for Windows. OpenShell is built on Microsoft’s agent security primitives and gives you an easy-to-deploy package for secure, on-device agents. It adds policy controls that let you define what OpenShell AI agents can and cannot do, such as which folders they may read, which apps they can control, and when they may access the network. OpenShell can also route queries to local models when privacy is critical, and disguise personal information in any requests that must go to cloud models. Popular Windows agent apps like Hermes Agent and OpenClaw are integrating OpenShell, so you can install them and immediately benefit from these protections. Together, the Windows primitives and OpenShell runtime keep powerful agents under strict user control on your RTX Spark Windows PC.
Optimize Local Models and Multi-GPU Performance for Faster Agents
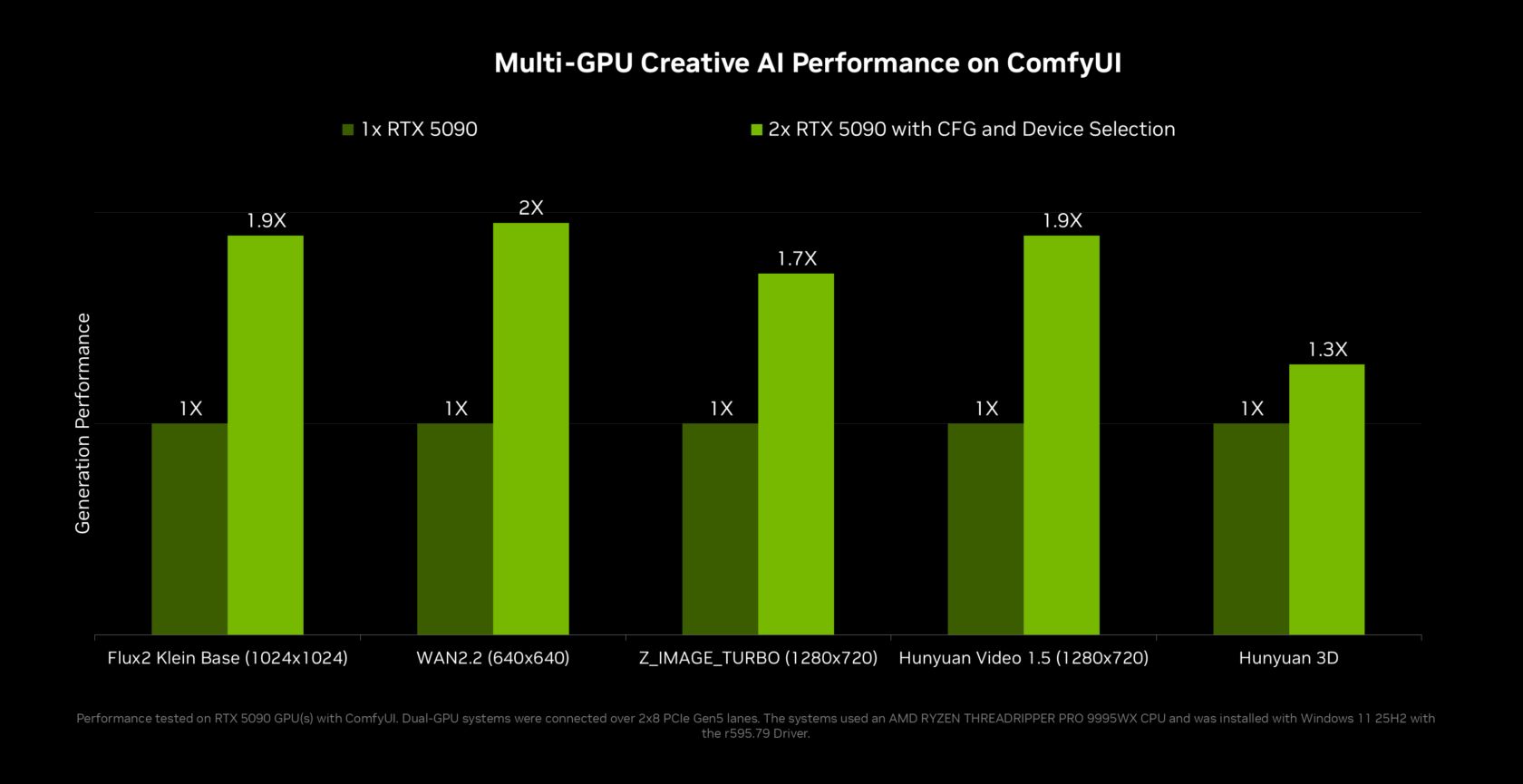
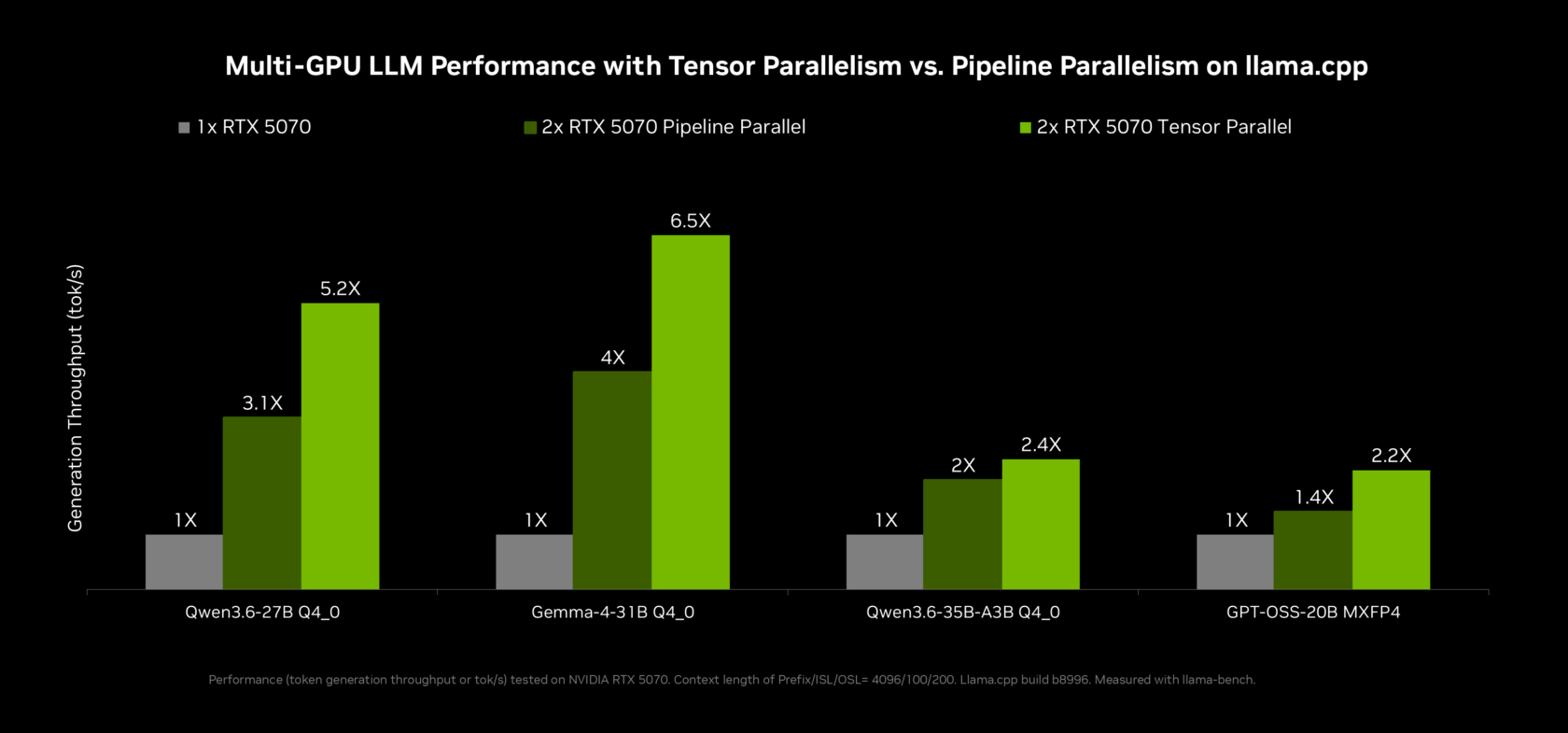
Once OpenShell AI agents are running, you can tune performance so they feel instant. On a single RTX Spark GPU, NVIDIA’s optimizations for llama.cpp and vLLM focus on multi-token prediction, where a smaller draft model proposes several tokens for the main model to verify at once. NVIDIA states that these features deliver up to 2x throughput on Qwen 3.6 and 3.5 27B, and around 1.6x on Qwen 3.6 and 3.5 35B. If your RTX Spark Windows PC or a nearby RTX system uses multiple GPUs, llama.cpp now supports tensor parallelism, which can double effective memory and increase compute throughput by up to 1.8x on two equivalent GPUs. For image workflows, ComfyUI gains new multi-GPU capabilities as well. These improvements keep offline AI deployment responsive even with larger agentic models and complex pipelines.
Bring Local AI Agents into Creative and Everyday Workflows
With performance and security in place, integrate local agents into your daily workflows on RTX Spark Windows PCs. Adobe is rearchitecting Photoshop and Premiere so they can tie into NVIDIA’s local AI stack, allowing agents to help with editing, compositing, and video timelines without sending media to the cloud. Blender is adding NVIDIA DLSS 4.5 Ray Reconstruction, while RTX Video Frame Generation and updates to NVIDIA Broadcast and Project G-Assist round out content creation and streaming scenarios. Using OpenShell, agents can coordinate across these tools: generating assets, editing clips, or searching local files while respecting your privacy policies. Because your RTX Spark system offers up to 128GB of unified memory and high AI compute, you can keep multiple agentic tasks running locally at once, maintaining full control over your data and avoiding reliance on external services for core creative work.





