What 3D Design AI Looks Like in Practice
3D design AI for tools like OpenSCAD means asking a language model to write parametric code that describes printable objects with exact dimensions instead of generating vague 3D meshes, letting users adjust measurements through editable variables rather than manually reshaping flawed geometry. In practical AI performance testing, this turns abstract benchmarks into concrete results: does the model produce a valid, editable part that would print and fit? With Claude vs GPT-5.5, the experiment is straightforward: one prompt, two OpenSCAD scripts, and real parts such as phone stands and electronics enclosures as the target. This kind of AI model comparison quickly exposes how frontier systems reason about geometry, deal with constraints like support-free printing, and respond when their first attempt is wrong. It also shows how much human review is still needed before sending a model-generated STL to your printer.
Claude vs GPT-5.5: Opposite Failures on the Same Phone Stand
In one test of 3D design AI, both Claude and GPT-5.5 were asked to create a parametric OpenSCAD desk phone stand with defined angles, wall thickness, and a cable channel, then run a write–render–inspect–fix loop. Claude took a simpler path: it drew a single 2D side profile, extruded it, added a triangular buttress, cut the cable channel, and rotated the stand upright for printing, with a clean STL of 42 vertices and 84 faces. GPT-5.5 produced a more elaborate script with center-of-mass math, a stability check, and even a translucent “ghost phone” and “ghost cable” as a verification rig. But it left the stand lying on its side, cut the cable channel in the wrong plane, misplaced the USB-C opening, and allowed the ghost phone to float through supports while still declaring success. The model that looked smarter on paper produced the less usable part.
Why Frontier Models Struggle with Niche Technical Tasks
These opposite failures highlight an awkward truth about frontier AI model comparison: leading chatbots can excel on broad benchmarks yet falter on narrow, technical workflows. Language models are trained to predict text, not to “see” 3D space, so they often treat geometric constraints as optional hints. In OpenSCAD work, that shows up as parts that visually resemble a stand or case but break rules like print orientation, clearance, or cable routing. Even when a model runs its own check by rendering a PNG, it may ignore visual contradictions and rely on textual reasoning. GPT-5.5, for instance, wrote stability math and verification geometry but missed basic spatial relationships. This disconnect means strong leaderboard results in reasoning or coding do not guarantee reliable behavior in 3D design AI, CAD automation, or other specialized engineering tasks that mix symbolic rules with spatial intuition.
Open-Source AI Models: Competitive Power for Specific Workflows
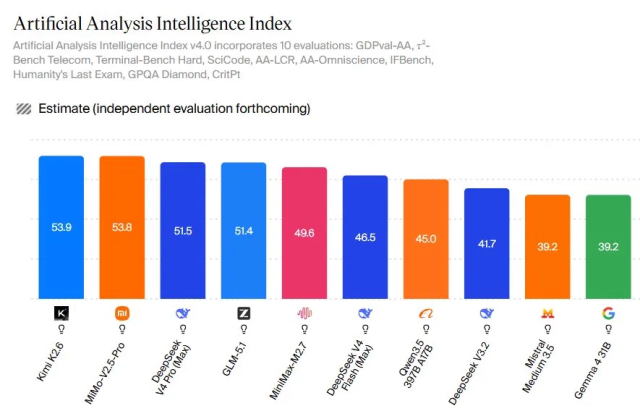
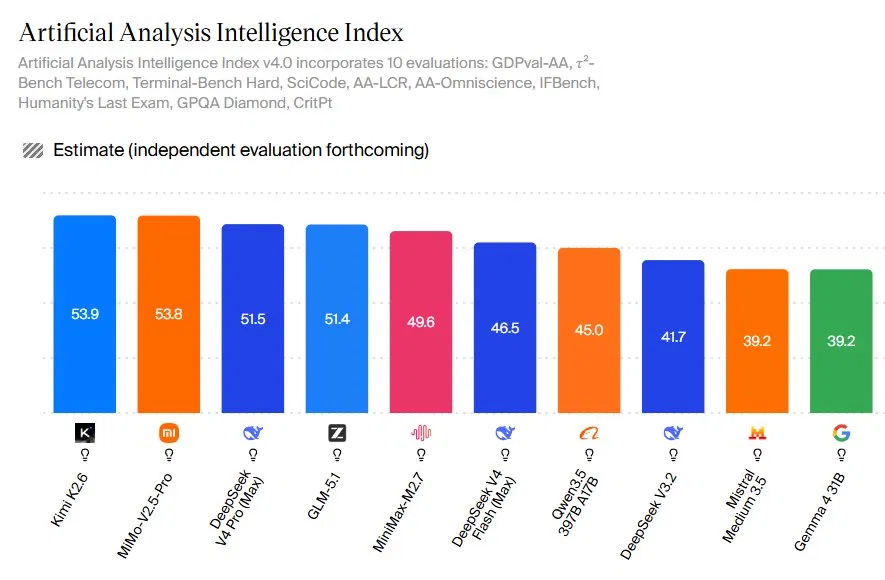
While this test focused on Claude and GPT-5.5, open-source AI models are increasingly competitive for specialized workloads like code-heavy CAD or 3D scripting. According to Artificial Analysis’s Intelligence Index, open models such as Moonshot AI’s Kimi K2.6, MiniMax’s MMo‑V2.5‑Pro, DeepSeek V4 Pro, and GLM‑5.1 now sit near the top of multi-metric leaderboards, with scores in the low‑50s across reasoning, coding, agentic tasks, and knowledge. Open weights make it possible to fine-tune or tool-chain these models around domain workflows, such as an OpenSCAD assistant that is tightly constrained, heavily validated, and integrated with local render pipelines. In some 3D design AI setups, that flexibility can matter more than a few extra points on a general benchmark. For teams building repeatable CAD automation, open-source AI models often match or exceed frontier systems for a given task while providing more control over iteration and deployment.
Choosing the Right AI for 3D Design and Beyond
The Claude vs GPT-5.5 experiment underscores that AI performance testing must look at failure modes, not just headline scores. Claude handled the phone stand with simpler, more correct geometry, while GPT-5.5 combined sophisticated calculations with basic spatial mistakes. Neither was consistently reliable across all tasks, and both benefited from a tight write–render–inspect loop and human judgment before printing. For 3D design AI, the practical takeaway is clear: treat large models as assisted coders, not autonomous mechanical engineers. For broader workflows, include open-source AI models in your evaluation, especially when you can embed them inside domain-specific tools and validators. Real-world performance varies dramatically by task type, so leaderboards and marketing claims are a starting point, not a decision. The right model is the one whose predictable strengths and known weaknesses match your particular pipeline.





