
What GLM-5.2 Is and Why Its Benchmarks Matter
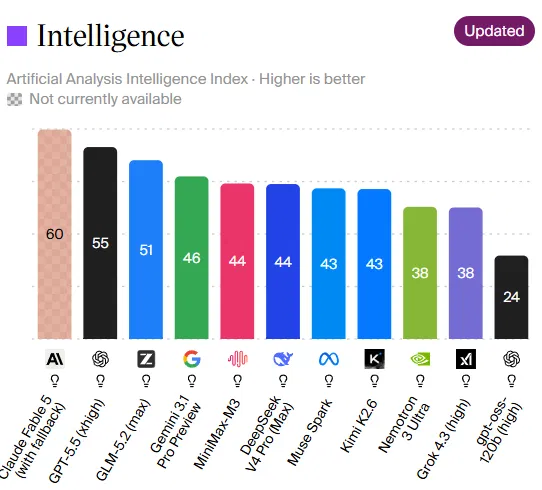
GLM-5.2 is an open-weight, Mixture-of-Experts large language model with a million-token context window that delivers frontier-level performance on real-world benchmarks, while remaining cheap enough and permissive enough for developers and enterprises to adapt, fine-tune, and deploy without being locked into proprietary AI services. Unlike many open-source AI models that trail commercial systems, GLM-5.2 sits near the top of the Artificial Analysis Intelligence Index, scoring 51 and ranking fourth overall behind only leading proprietary models. In coding AI performance tests such as SWE-bench Pro, it scores 62.1, ahead of GPT-5.5’s 58.6, and it sits within a single percentage point of Claude Opus 4.8 on FrontierSWE’s long-horizon tasks. These results position GLM-5.2 as a practical alternative to GPT, Gemini, and Claude, not a second-tier fallback.

Design Arena and the Web Design Breakthrough
GLM-5.2’s headline win came from Design Arena, a crowdsourced benchmark where human voters score HTML web designs in blind tests. In the single-round web design leaderboard, the model climbed to the #1 spot in the non-agent category, overtaking Claude Fable 5 and its Opus 4.6 and 4.7 variants and jumping five places over GLM-5.1. The platform reports an Elo score around 1360 in its Code Categories arena and a win rate gain of about six percentage points over its predecessor. GLM-5.2 tends to produce clean layouts, strong typography, clear visual hierarchy, and subtle animations while smoothly using Chart.js, Three.js, Tailwind CSS in 91% of designs, and Font Awesome in 51%. According to Design Arena, this performance reflects “millions of votes from actual creators” evaluating aesthetics and usability, not synthetic prompts.

Coding Power: From SWE-bench to Long-Form Engineering
Beyond web design, GLM-5.2’s coding AI performance is central to its appeal. The model is a 744-billion-parameter Mixture-of-Experts with 40 billion active parameters per call, the same parameter footprint as GLM-5.1, yet it scores 62.1 on SWE-bench Pro, beating GPT-5.5’s 58.6. On FrontierSWE, which stresses long-form engineering and multi-step software tasks, GLM-5.2 lands within one percentage point of Claude Opus 4.8, narrowing a gap that had previously favored proprietary systems. A training optimization called IndexShare shares a single attention index across sparse layers, cutting per-token compute by 2.9 times at one million tokens of context and helping the model sustain long sessions on large codebases. This mix of long context, improved efficiency, and high benchmark scores is what makes GLM-5.2 a credible daily driver for programmers and tool builders.
GDPval-AA: Beating GPT and Gemini on Real-World Work
GLM-5.2’s most consequential win may be on GDPval-AA v2, a benchmark that measures agentic, economically valuable work rather than isolated questions. In this test, the model scored 1524 Elo on tasks that averaged about 31 turns per match over 1,999 matches, reflecting repeated, long-horizon problem solving. It ranked third overall, behind only Claude Fable 5 at 1783 and Claude Opus 4.8 at 1615, but ahead of GPT-5.5’s 1509 and Gemini 3.5 Flash’s 1357. On AA-Briefcase, which blends rubric pass rate, analytical quality, and presentation, GLM-5.2 again leads open models with 1266 Elo and outperforms GPT-5.5 at xhigh reasoning, which scores 1159. These Artificial Analysis benchmarks suggest that open-source AI models can now meet or exceed proprietary systems on real-world research, analysis, and structured deliverables that matter to enterprises.

Enterprise Momentum and the New Open-Source Competitive Landscape
The GLM-5.2 benchmark story is amplified by who is praising it and how enterprises may respond. Vercel CEO Guillermo Rauch said he was “almost shocked” by its coding ability and summed up the impact with four words: “This changes things.” Box CEO Aaron Levie highlighted that open-weight AI achieving state-of-the-art results keeps the gap between open and closed models narrow, which increases the value that can be built at the applied layer. Jeremy Howard described GLM-5.2 as “a marvel,” placing it on par with Claude Opus 4.8 and GPT-5.5 and praising its nuance and long-context reliability. As a MIT-licensed, open-weight system with a one-million-token context window, GLM-5.2 is cheaper to deploy than many proprietary rivals and can be run locally, making enterprise AI adoption less dependent on a single vendor and signaling a more competitive future for AI model comparison.






