AI Infrastructure Optimization Now Starts Below the Model
As AI deployments shift from demos to production, costs are increasingly dictated by infrastructure, not just model choice. Teams scaling chatbots, copilots, and agentic systems face three compounding pressures: token bills, GPU underutilization, and brittle workflows that crash mid-run. This is pushing practitioners to rethink AI infrastructure optimization across the full stack. Instead of chasing ever-larger models, attention is turning to token cost reduction, GPU utilization improvement, and AI workflow reliability as primary levers. Open-source projects are emerging to address each layer: OpenSquilla targets token routing inefficiencies in agentic AI, MinIO’s MemKV attacks the recompute tax that keeps GPUs idle, and Temporal’s Durable Execution framework hardens workflows so long-running AI processes actually finish. Together, they represent a new tooling pattern: use smarter routing, stateful memory, and crash-proof orchestration to squeeze more value from existing models and hardware, before buying more GPUs or paying for pricier APIs.
OpenSquilla: Smarter Model Routing for Token Cost Reduction
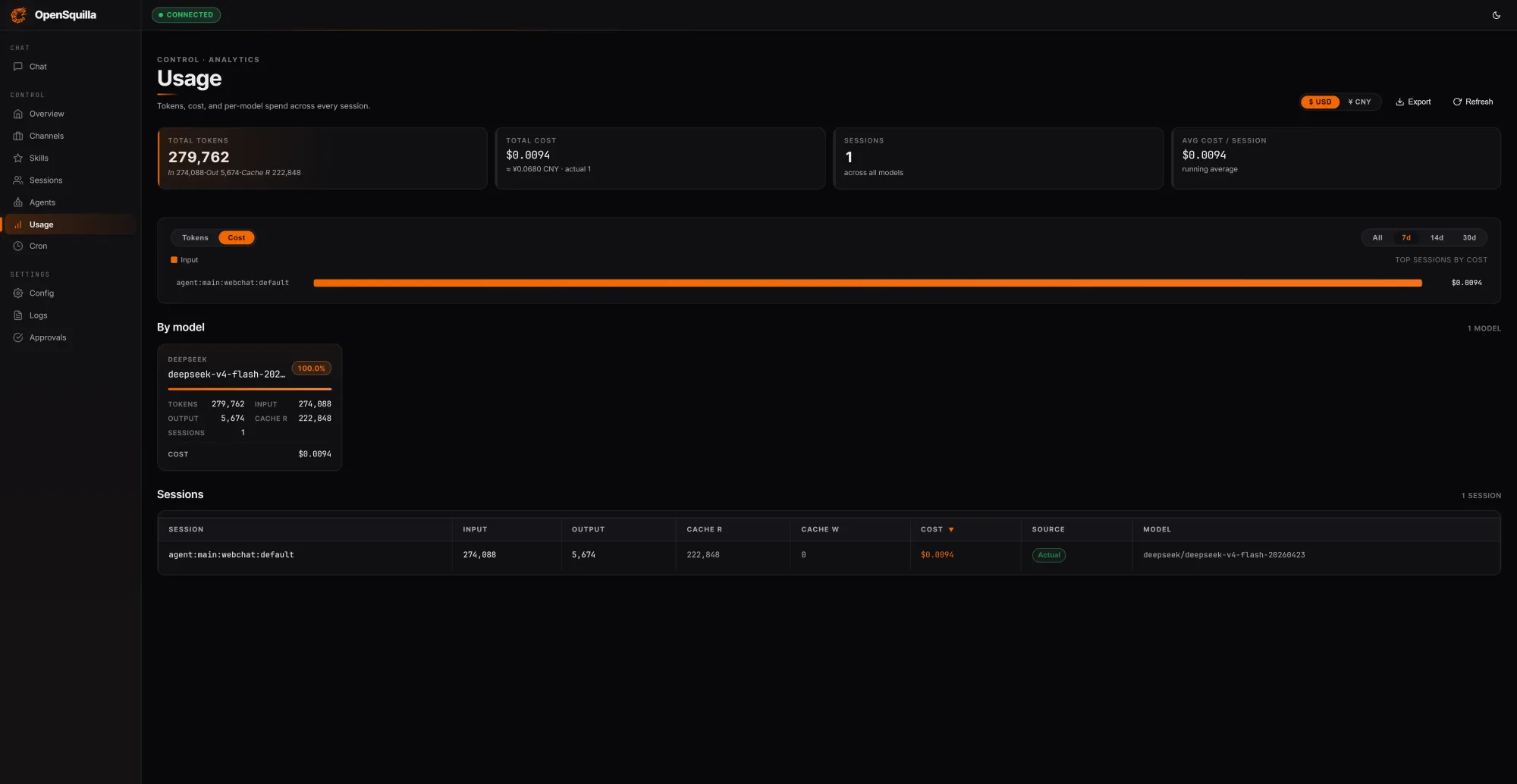
OpenSquilla positions itself as a self-hostable, open-source AI agent runtime built to stop wasteful token spending in long-horizon workflows. Its core premise is that most agent frameworks reload context and overuse expensive models, with no built-in controls to prevent runaway bills. OpenSquilla combines an ML classifier with hand-crafted signals—such as message length, presence of code blocks, and keyword patterns—and embedding-based semantics to score each request by complexity. Lightweight prompts are routed to cheaper models and deep reasoning is disabled for trivial tasks, directly improving token cost reduction. Context is cached and reused across turns, instead of being resent on every call. In one test session totaling 279,762 tokens, OpenSquilla served 222,848 tokens from cache, roughly 80% of inputs, illustrating how aggressive reuse can suppress token spend. Quota hooks and per-call cost tracking add guardrails, making token governance an integral part of AI infrastructure optimization rather than an afterthought.
MemKV: Eliminating the GPU Recomputation Tax
MinIO’s MemKV targets a different bottleneck: GPUs wasting cycles recomputing context they have already processed. As AI systems execute multi-step reasoning, context is often dropped because memory close to the GPU cannot hold enough of it. When that state disappears, the GPU redoes prior work—a phenomenon MinIO describes as recompute tax, a structural drag on time, energy, and resources. MemKV introduces a native flash-based context memory tier, accessible end-to-end over 800 GbE RDMA, designed to provide persistent, shared context across GPU clusters at petabyte scale. By keeping rich context available, GPUs can progress instead of replaying previous steps, leading to GPU utilization improvement and faster inference. Benchmarks highlighted by MinIO show MemKV delivering over 95% better GPU utilization and around 50% lower cost per token, while improving both Time to First Token and Time Per Output Token. The result is higher effective throughput from existing GPU fleets without changing the underlying models.

Temporal: Durable Execution for AI Workflow Reliability
While OpenSquilla and MemKV refine how tokens and GPUs are used, Temporal focuses on making AI workflows survive real-world failure modes. Its Durable Execution framework is an open-source-based runtime that automatically persists workflow state so long-running processes can resume exactly where they left off after crashes, network outages, or restarts. Instead of scattering manual retry logic and error handling across services, developers write straightforward code while Temporal records each step, converting fragile sequences into crash-proof workflows. This approach is increasingly used for complex AI workloads, from multi-step agent lifecycles to data pipelines, where interruptions are both common and costly. Temporal reports more than 3,000 paying customers, including Nvidia, Netflix, Snap, and Stripe, plus many thousands of open-source users, underscoring its growing role in AI workflow reliability. By ensuring processes run to completion without manual intervention, it reduces the hidden operational costs of failed runs and partial results.

Combining Token, Compute, and Workflow Layers for End-to-End Savings
Taken together, OpenSquilla, MemKV, and Temporal illustrate an emerging blueprint for AI infrastructure optimization that operates across three distinct layers. At the top, OpenSquilla curbs token waste through intelligent model routing, context reuse, and built-in budget controls. In the middle, MemKV increases effective GPU capacity by minimizing recompute tax and maintaining persistent, shared context near the accelerator. At the base, Temporal’s Durable Execution engine hardens the orchestration fabric, so complex AI workflows can reliably run to completion, even under failure. Organizations looking to rein in AI costs can stack these approaches: route prompts to the right models, keep GPUs fed with the right context, and ensure every long-running workflow is resilient. Instead of scaling infrastructure reactively, teams gain a systematic way to drive token cost reduction, GPU utilization improvement, and AI workflow reliability—with open-source tools that can be adopted incrementally as their AI footprint grows.