A Strategic Comeback in the AI Coding Assistant Race
Cursor’s Composer 2.5 release marks a deliberate attempt to regain ground in the AI coding assistant market, where Anthropic’s Claude and other frontier models have recently dominated. Once seen as the default environment for AI-assisted development, Cursor has faced pressure as Claude Code scaled to hundreds of thousands of business users and billions in annualized revenue, while Cursor itself still generates vast volumes of accepted code across many large enterprises. Composer 2.5 is Cursor’s answer to the growing appetite for autonomous coding agents and long-running workflows, rather than simple autocomplete. By building on an open-source base and heavily customizing it, Cursor aims to loosen its dependency on third‑party model providers and reposition itself as a first‑class model vendor. The pitch is clear: near-frontier performance on serious coding tasks, embedded directly in the IDE, at prices designed to undercut premium alternatives.

Benchmarks: Matching Claude Opus 4.7 on Core Coding Tasks
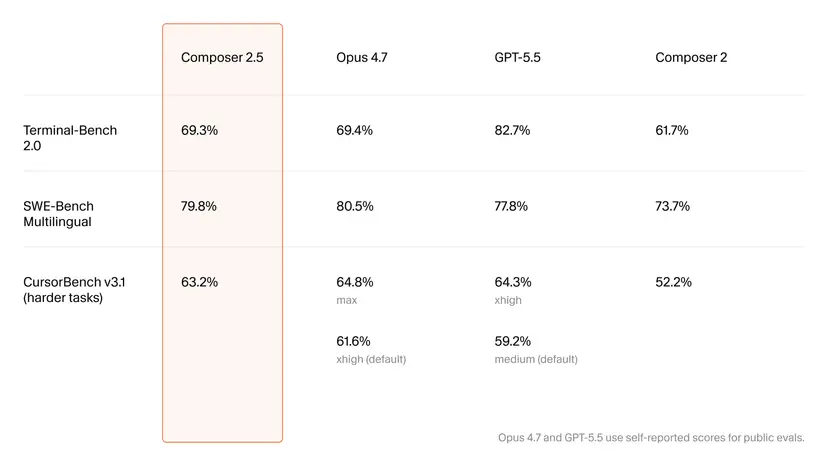
Composer 2.5’s appeal rests heavily on code generation benchmarks that place it in the same conversation as Anthropic’s Claude Opus 4.7 and OpenAI’s latest models. On SWE-Bench Multilingual, the model reaches 79.8%, effectively neck and neck with Opus 4.7’s 80.5% and ahead of GPT‑5.5 at 77.8%. On Terminal-Bench 2.0, a proxy for shell-based development workflows, Composer 2.5 scores 69.3%, essentially matching Opus 4.7’s 69.4%, while GPT‑5.5 leads at 82.7%. Cursor’s own harder-task metric, CursorBench v3.1, shows Composer 2.5 at 63.2%, beating GPT‑5.5’s default configuration and approaching Opus 4.7’s highest setting. These results suggest that, for many practical coding scenarios, Composer 2.5 can deliver comparable problem‑solving power to leading premium assistants, especially when integrated into an IDE experience that optimizes for multi-file edits and tool usage.

Cost Efficiency: Up to 10x Cheaper Without Sacrificing Quality
Where Composer 2.5 tries to truly differentiate is cost efficiency. Cursor positions the model as an affordable coding tool that narrows the quality gap while dramatically lowering per‑task spend. Official pricing for the standard variant is USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens. A faster default variant is listed at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. Cursor claims up to 10x cost efficiency gains over previous Composer generations and highlights internal effort‑curve analyses where Composer 2.5 reaches around 63% on CursorBench at under USD 1 (approx. RM4.60) per task, while comparable models cost several dollars more for similar or weaker results. For teams running thousands of long-running agent sessions, these differences can compound into substantial AI infrastructure savings.
Targeted RL and 25x Synthetic Training for Long-Running Tasks
Under the hood, Composer 2.5 is built on Moonshot’s Kimi K2.5 checkpoint, but Cursor says roughly 85% of total compute went into its own fine‑tuning and reinforcement learning stack. The most notable change is targeted RL with localized textual feedback: instead of waiting for a single reward at the end of a long rollout, Cursor injects short hints exactly where the model missteps, such as a faulty tool call. These local corrections help the model learn from trajectories spanning hundreds of thousands of tokens, a critical property for sustained refactors or multi-step debugging. On top of that, Composer 2.5 has been trained on 25x more synthetic tasks than Composer 2, using diverse generation pipelines to stress-test complex workflows. Cursor also reports improved behavioral calibration, aiming for better communication style, instruction-following, and coding consistency—key factors that benchmarks alone often fail to capture.
Real-World Implications for Developers and the Competitive Landscape
For developers choosing an AI coding assistant, Composer 2.5 reframes the trade-off between capability and cost. Benchmarks show it keeping pace with leading models on Terminal-Bench and SWE-Bench while dramatically undercutting them on price, making it attractive for organizations that want aggressive AI adoption without runaway spending. At the same time, community feedback underscores that benchmark wins do not automatically translate into frictionless coding: early users report both stronger long-running behavior and occasional agent confusion, where Composer 2.5 loses track of pipelines mid-task. This tension captures Cursor’s broader strategic bet. By rapidly iterating models, investing in agent-focused training methods, and aligning pricing with large‑scale enterprise usage, Cursor is challenging Anthropic’s and OpenAI’s dominance not just on raw scores, but on everyday developer experience, positioning Composer 2.5 as a realistic, cost-effective alternative for serious code generation work.