What Claude Opus 4.8’s Benchmark Win Actually Means
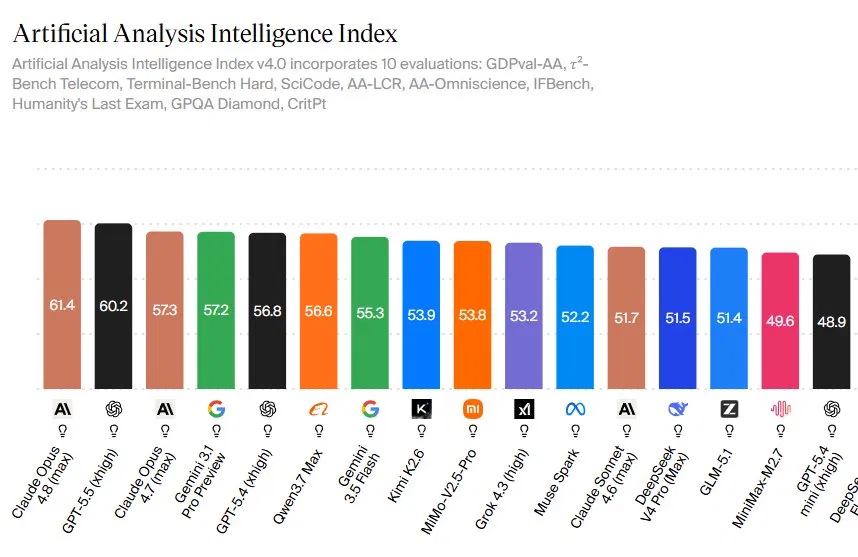
Claude Opus 4.8 is Anthropic’s latest flagship large language model, and its top score on the Artificial Analysis Intelligence Index signals a shift in the AI benchmark ranking that matters for how enterprises compare AI models and decide between systems like GPT 5.5 vs Claude for high‑stakes, economically valuable work. Opus 4.8 scores 61.4 on the Artificial Analysis Intelligence Index v4.0, ahead of GPT‑5.5’s 60.2 and Opus 4.7’s 57.3, making it the highest‑rated general‑purpose model in this independent AI model comparison. The index blends 10 demanding evaluations, including Humanity’s Last Exam, GPQA Diamond, GDPval‑AA, and Terminal‑Bench, giving a broad picture of reasoning, coding, tools use, and agentic behavior. Artificial Analysis’ table also places Gemini 3.1 Pro Preview and GPT‑5.4 in the high‑50s, with Qwen, Gemini 3.5 Flash, Kimi, and MiMo models forming a tight second pack, so the new lead is narrow but important.
Inside the Scores: Agentic Work, Coding, and the GDPval-AA Signal
The 1.2‑point gap between Claude Opus 4.8 and GPT 5.5 on the Artificial Analysis Index looks small, but it rests on a pattern: Opus 4.8 tends to win on hard, structured tasks that resemble enterprise workflows. Anthropic reports a 69.2% score for Opus 4.8 on SWE‑Bench Pro, compared with 58.6% for GPT‑5.5, and 57.9% on Humanity’s Last Exam with tools, ahead of all rivals. The clearest signal for business deployment is GDPval‑AA, which simulates real jobs across 44 occupations and 9 industries. Here Opus 4.8 reaches 1890 Elo, 121 points above GPT‑5.5. That benchmark focuses on agentic work over web and shell, closer to how AI agents execute tasks in production. The trade‑off: Opus 4.8 uses about 30% more turns per task than GPT‑5.5, a cost and latency factor for high‑volume automations even as quality improves.
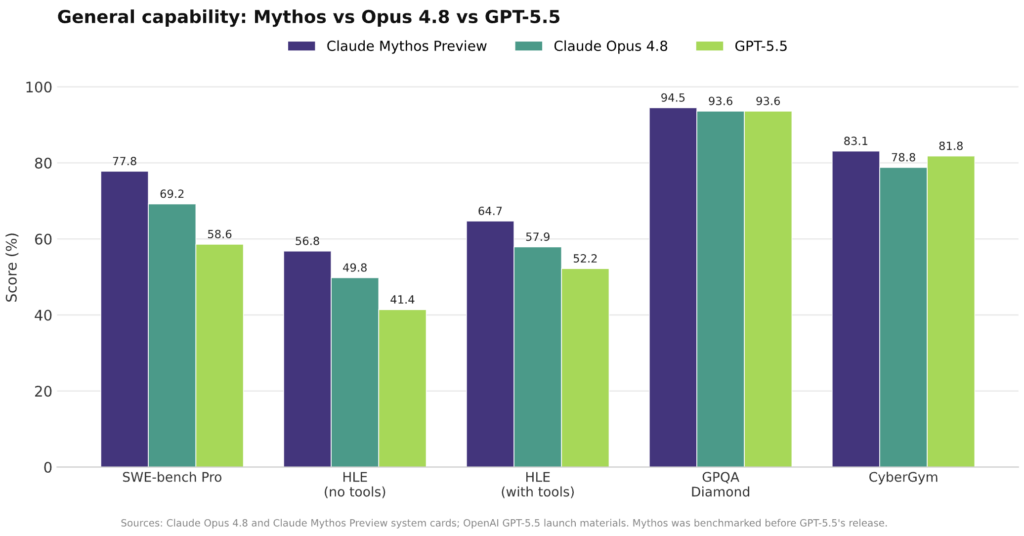
Mythos vs Opus 4.8 vs GPT 5.5: Where Each Model Leads
Anthropic positions Claude Mythos as a higher‑end tier above Opus 4.8, but the advantage is uneven. On Anthropic’s internal AECI index, Opus 4.8 scores 155.5, between Opus 4.7 at 154.1 and Mythos Preview at 158.3, pointing to a modest general‑intelligence gap rather than a dramatic leap. The separation grows on the hardest software tasks: Mythos hits 77.8 on SWE‑Bench Pro compared with 69.2 for Opus 4.8 and 58.6 for GPT‑5.5. Reasoning benchmarks are closer. GPQA Diamond, a frontier science set designed to be search‑proof, shows Mythos and Opus 4.8 both near 94, alongside GPT‑5.5, while USAMO‑style math scores sit within a point. Cybersecurity is the real outlier: Anthropic’s system cards describe Mythos as far stronger than Opus 4.8 on exploit generation and OSS‑Fuzz challenges, while external tests like ExploitGym and the UK AI Security Institute show Mythos and GPT‑5.5 trading narrow leads on expert cyber tasks.

Pricing, Speed, and How Benchmarks Shape Enterprise AI Choices
For buyers, Claude Opus 4.8’s benchmark gains matter because they arrive without a price hike. According to RDWorld, Opus 4.8 ships at the same base price as Opus 4.7, at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens. Anthropic is also offering a Fast Mode that runs the same model around 2.5x faster at roughly one‑third the standard cost, controllable in Claude Code via the /fast command. These details matter when mapping AI benchmark ranking to procurement decisions. Opus 4.8’s higher scores on GDPval‑AA, SWE‑Bench, and Humanity’s Last Exam make it attractive for agentic coding and workflow automation, but its higher turns‑per‑task can raise total spend versus GPT‑5.5. Mythos adds more power but at a preview price reportedly five times higher than Opus. The emerging pattern: benchmark leaders are segmenting into tiers, and enterprises are choosing not a single “best” model, but a portfolio matched to task complexity, security exposure, and budget.





