What Enterprise AI Agents Are – And Why Context Decides Success
Enterprise AI agents are software entities that perform tasks, make recommendations, and automate workflows inside large organizations by acting on business data, content, and processes with limited human supervision, and their success depends on reliable access to contextual information from existing systems rather than operating as isolated tools. In the rush to adopt such AI agents, many vendors push “rip-and-replace” programs that demand new platforms, new processes, and large change-management efforts. The result is often a fragile stack where agents cannot see critical documents, transactions, or rules that still live in legacy repositories. Without this context, even advanced models default to clever chatbots instead of dependable co-workers. This gap between eye-catching demos and production reality explains why enterprises in regulated sectors, where unstructured documents dominate, are reassessing how they approach AI agents enterprise deployment and asking how to integrate them directly into established infrastructure.

The Hidden Cost of Rip-and-Replace AI Agent Deployments
Vendors promoting greenfield AI stacks frame them as cleaner and easier to manage, but they impose heavy integration and governance debts. Moving all enterprise data into a new cloud layer, rebuilding workflows, and re-training staff slows programs before any clear ROI emerges. Hyland CEO Jitesh Ghai calls this approach “blowing things up” and argues it is unnecessary and improper for most organizations. These projects underestimate how complex enterprise data is, especially when 70% to 90% of it is unstructured and spread across multiple content management systems and line-of-business tools. Each new siloed agent stack must be wired into identity systems, audit trails, records policies, and compliance workflows. Instead of accelerating transformation, rip-and-replace plans create parallel universes of content and rules that are hard to govern, confusing for users, and brittle under regulatory scrutiny.
Deploying AI Agents on Existing Infrastructure Integration
An alternative playbook is emerging: bring agents to the systems and processes organizations already trust. Rather than migrating everything into a single new platform, a content or data federation layer reaches into existing repositories and line-of-business apps, then exposes that context to AI agents. This existing infrastructure integration approach turns the current stack into a shared backbone for reasoning, without asking teams to abandon proven workflows. It also helps preserve security and compliance rules that are already understood by risk and legal teams. When AI agents enterprise deployment starts from where content and processes live today, enterprises can pilot narrow use cases, measure value, and expand safely. Time-to-value shortens because there is no multi-year rebuild; instead, agents attach to real work queues, cases, and records from day one, and IT teams avoid another monolithic platform to maintain.
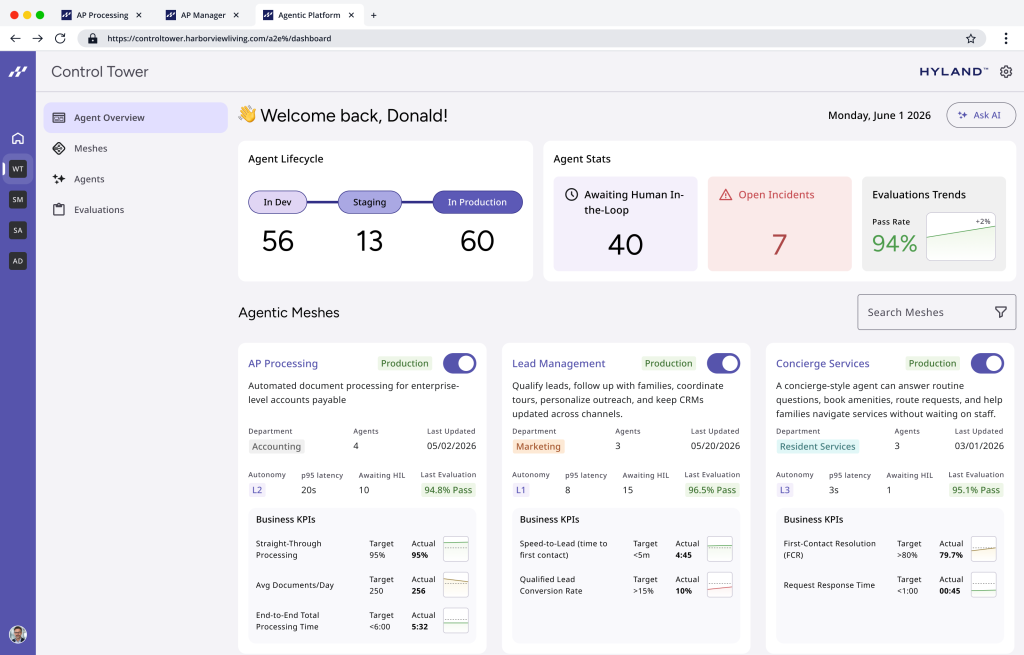
How Enterprise Context Engine and Agent Mesh Architectures Work
Hyland’s Enterprise Context Engine illustrates how a contextual layer can organize existing content and data into something AI agents can use. It builds a content and data fabric by structuring unstructured documents, enriching them, and linking them into knowledge graphs shaped by industry-specific ontologies for sectors such as healthcare, insurance, financial services, education, and government. According to Hyland, “so many initiatives are failing because there’s an under-appreciation for the complexity of the underlying data.” On top of this layer, an Enterprise Agent Mesh coordinates multiple agents, with Agent Lifecycle Management and an Agent Library tracking each agent’s identity, capabilities, and guardrails. An Agent Passport acts like a certificate that must be in place before an agent runs in production. A headless mode then exposes this architecture through APIs, so third-party tools and custom workflows can consume context, reasoning, and governance without adopting a new user interface.

Better Adoption and Governance Through Familiar Workflows
Enterprises report better adoption when AI agents work inside familiar tools rather than asking employees to learn yet another dashboard. If a claims processor, loan officer, or public-sector caseworker can trigger agents from the same content management, CRM, or workflow system they already use, resistance drops and outcomes improve. Governance also becomes more practical. A central “Control Tower” concept, as planned in Hyland’s architecture, gives observability into agent performance, decision paths, and compliance status. Agent Lifecycle Management provides traceability from design through retirement, which is essential in regulated industries where audits are routine. By keeping agents close to existing data classifications, retention rules, and access controls, organizations avoid policy drift between old and new systems. The result is an AI agents enterprise deployment model that balances innovation with oversight, turning context-aware agents into safe collaborators instead of unmanaged shadow systems.





