What LLM inference speed means and why it suddenly matters
LLM inference speed is the rate at which a large language model produces output tokens during generation, and recent advances now let standard GPUs reach over 1,000 tokens per second, pushing AI response times into near-instant territory for many applications. This shift turns latency from a frustrating bottleneck into a design choice: teams can trade speed, cost, and quality depending on the task. Faster tokens per second performance enables more interactive user experiences, denser multi-agent systems, and live tools that respond in real time. At the same time, GPU optimization techniques and new numeric formats are lowering the amount of hardware needed to get there. Together, these changes make high-end AI more accessible to startups and small product teams that cannot afford huge clusters, without forcing them to give up frontier-class capabilities.
Xiaomi MiMo-V2.5-Pro: UltraSpeed mode breaks the 1,000 TPS barrier
Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode is a headline example of LLM inference speed progress, pushing generation beyond 1,000 tokens per second on general-purpose GPUs. According to Xiaomi, this is achieved through an “ultimate co-design” of the 1-trillion-parameter model with its underlying system, aligning architecture, kernels, and memory layouts around throughput rather than training flexibility. Earlier in the MiMo family, MiMo-V2-Flash was already notable at around 150 tokens per second, so UltraSpeed represents roughly a tenfold jump over standard MiMo-V2.5-Pro API performance. Xiaomi prices the UltraSpeed API at about three times the regular rate and limits access to an application-based trial, reflecting the constrained supply of high-speed inference resources. Even with these limits, the demonstration shows that consumer-grade GPUs can host extremely large models while delivering responsiveness that feels closer to local software than to a remote cloud service.
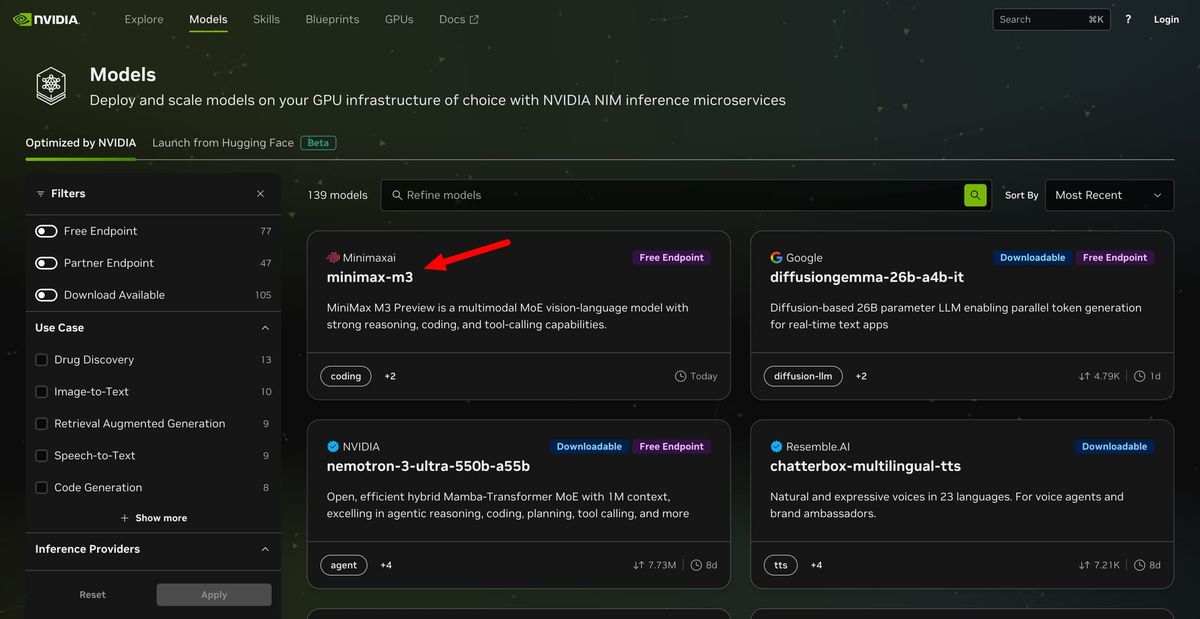
MiniMax M3 and sparse attention mechanisms for long contexts
Where MiMo chases raw speed, MiniMax M3 focuses on long-context efficiency using sparse attention mechanisms. The 428-billion-parameter model supports context windows up to one million tokens and is built around MiniMax Sparse Attention, which cuts the number of attention operations during both prefill and decoding. This targeted focus on relevant tokens reduces computational overhead and improves tokens per second performance on NVIDIA accelerators, especially for workloads like extended codebases, video analysis, and step-by-step design tasks. Trained natively on multimodal data, M3 treats text, images, and video as first-class inputs rather than bolt-ons. On the hardware side, formats such as BF16 and MXFP8, together with support for up to 128 experts per token, help the model run efficiently on Blackwell GPUs. For enterprises, this means they can process long, complex sessions without a linear explosion in latency or cost.
JAX, MaxText, and NVFP4: throughput as a first-class objective
On the training and serving stack, frameworks like JAX and MaxText are pairing with emerging numeric formats such as NVFP4 on NVIDIA Blackwell to squeeze more throughput out of each GPU. NVFP4 is designed to represent activations and sometimes weights in fewer bits while keeping error within acceptable bounds for large-scale models, which raises effective tokens per second performance at a fixed power budget. In this setup, MaxText provides an optimized training and inference template, while JAX offers fast compilation and XLA-based kernel fusion. The combination is well suited to trillion-token or trillion-parameter scale, where memory bandwidth and interconnect become dominant constraints. By increasing arithmetic density and reducing data movement, these stacks shorten training cycles and support higher-rate inference on the same hardware, helping smaller labs reach model sizes that were recently reserved for the largest AI companies.
Lowering hardware barriers and what comes next
Taken together, these advances in LLM inference speed shift the conversation from "Who can afford a giant cluster?" to "Who can make the best use of a few GPUs?" MiMo-V2.5-Pro’s UltraSpeed mode proves that even 1-trillion-parameter models can respond at over 1,000 tokens per second on standard GPUs when model and system are co-designed. MiniMax M3 shows how sparse attention mechanisms keep long-context tasks practical, avoiding a quadratic wall as context windows stretch to one million tokens. JAX and MaxText with formats like NVFP4 on Blackwell highlight that software and numerics are as important as raw silicon. For startups and small teams, the result is clear: frontier-class capabilities are moving within reach, unlocking new products such as real-time copilots, 24/7 agents, and multimodal analysis tools that no longer require hyperscaler budgets to build and run.