
What DiffusionGemma Is and Why It Matters
DiffusionGemma is an experimental 26-billion-parameter text model from Google that replaces slow, word-by-word prediction with a diffusion process that refines whole blocks of tokens in parallel, delivering up to four times higher on-device text generation speed than standard Gemma 4 models while intentionally accepting lower benchmark accuracy to better serve latency-sensitive local AI applications such as code infilling and inline editing. Instead of predicting the next token like a typist, DiffusionGemma starts from a noisy canvas of placeholder tokens and repeatedly “denoises” them into readable prose. This diffusion approach mirrors how popular image generators evolve random noise into a clear picture. The result is a fast Gemma alternative that favors responsiveness over raw benchmark scores. Google labels it experimental and targets developers and researchers who want to explore new local AI models and on-device text generation techniques rather than a drop-in replacement for general-purpose chatbots.

Inside the Diffusion-Based Architecture and 4x Speed Boost
DiffusionGemma’s speed advantage comes from how it uses hardware. Traditional autoregressive models keep GPUs waiting between next-token steps, making memory bandwidth the bottleneck. DiffusionGemma instead denoises up to 256 tokens in parallel per step, handing GPUs a large chunk of work and shifting the bottleneck to compute, where modern accelerators excel. According to Google, DiffusionGemma can exceed 1,000 tokens per second on a single Nvidia H100 and reach around 700 tokens per second on a GeForce RTX 5090. The model is a Mixture of Experts design with 26 billion total parameters but activates only about 3.8 billion during inference. Quantized, it fits within roughly 18GB of VRAM, making it a practical fast Gemma alternative for high-end consumer GPUs. Tokens in each block can attend to every other token in both directions, a structure that favors non-linear tasks like code edits, amino acid sequences, and graph reasoning.
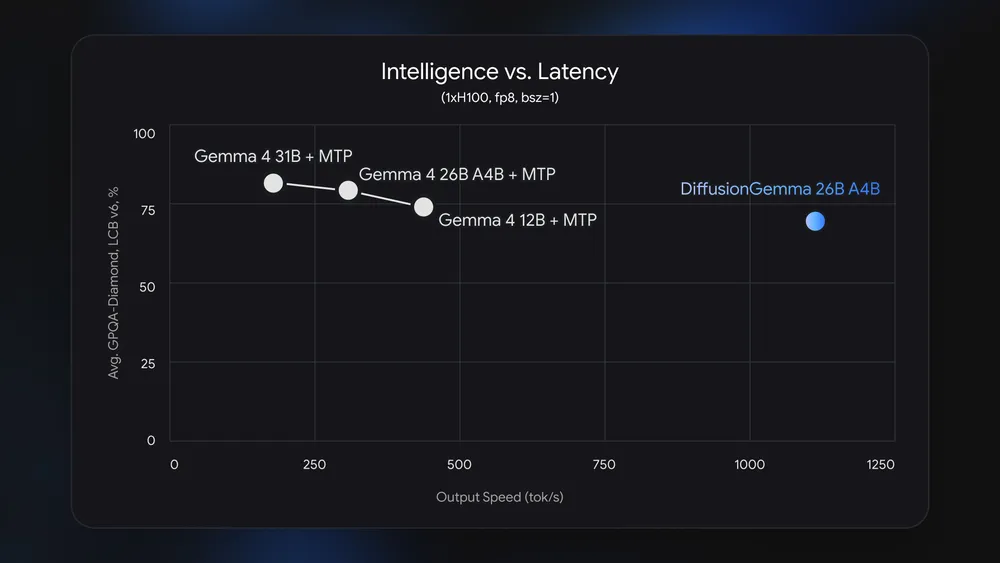
The Accuracy Tradeoff: Why Google Prioritized Speed
The impressive DiffusionGemma speed numbers come with a clear tradeoff: benchmark performance. Across standard evaluations, the model trails Google’s own Gemma 4 26B A4B. Google is explicit that this is a deliberate design choice rather than a fundamental limit of diffusion models. The company optimized the system for low-latency, single-user scenarios on local GPUs instead of leaderboard-topping scores. Because the model refines 256-token blocks, it is less tuned for long-form, globally coherent reasoning than a finely trained autoregressive counterpart. DiffusionGemma drafts and polishes in place; it is excellent at “fix this chunk” style operations but less focused on writing extended essays or complex multi-step arguments from scratch. For developers choosing between local AI models, the question is not which Gemma is smarter in aggregate, but whether on-device text generation needs snappy, interactive updates or maximum accuracy on broad benchmarks.

Best Use Cases: When to Pick DiffusionGemma Over Gemma 4
DiffusionGemma shines in workflows where latency matters more than peak accuracy and where text does not flow purely left to right. Inline editing is a prime example: the model can revise an entire sentence or function in one pass, with each token attending to every other token in the block. Code infilling benefits in the same way, since constraints may depend on lines that appear later in the file. Unsloth’s Sudoku demo illustrates this structural strength for grid- and graph-like problems. For real-time coding assistance on a single GPU, DiffusionGemma can feel more responsive than a larger, slower, but more accurate Gemma 4 model. It also suits interactive local tools that repeatedly rewrite small spans of text, such as IDE assistants, document refiner panels, or scientific sequence editors. For long-form writing, complex reasoning, or multi-user cloud serving, standard Gemma 4 remains the better default.
What DiffusionGemma Signals for On-Device AI
DiffusionGemma is framed as an experiment, but it signals where on-device AI might be heading. Google released it under an Apache 2.0 license and built it to run on a single high-end GPU, aligning with a broader push to move capable language models from data centers to desks. Its design makes clear that “local-first” does not only mean shrinking models; it can also mean changing the generation algorithm itself. For developers, DiffusionGemma is a testbed for new interaction patterns, especially for fast Gemma alternative deployments in editors, notebooks, and local tools. It encourages thinking in terms of blocks, revisions, and constraints instead of linear next-token streams. As more local AI models adopt diffusion-style on-device text generation, the tradeoff between accuracy and responsiveness will likely become a central design choice rather than an afterthought.




