Cursor’s Comeback Play in the AI Coding Assistant Market
Cursor, once seen as a default choice for AI-assisted coding, has recently ceded mindshare to Anthropic’s Claude Code and OpenAI’s GPT family. Claude’s rapid commercial rise, including strong enterprise traction, has left Cursor paying a rival for inference while competing with it on product experience. Composer 2.5 is Cursor’s clearest attempt yet to reset that balance by running its own most capable in-house model instead of relying solely on external providers. The company frames the release as a response to a shifting market where autonomous coding agents, rather than traditional IDE-centric workflows, are driving excitement and budgets. Cursor still processes vast volumes of accepted code and counts a large share of major enterprises as customers, but perceptions have tilted toward Claude and GPT as the cutting-edge choices. Composer 2.5 is designed to change that narrative by combining competitive intelligence with significantly lower usage costs.

Benchmark Results: Matching Opus 4.7 and Pressuring GPT-5.5
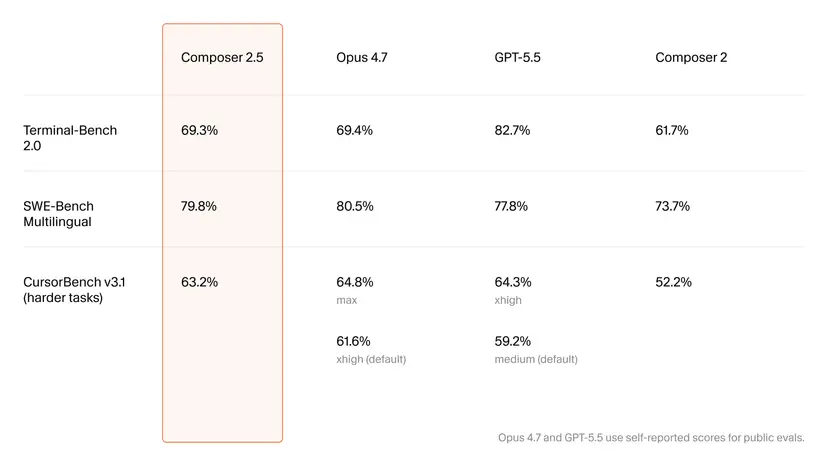
On standardized evaluations, the Composer 2.5 benchmark story is surprisingly strong for a cost-focused model. On SWE-Bench Multilingual, Composer 2.5 reaches 79.8%, just behind Claude Opus 4.7 at 80.5% while edging out GPT-5.5 at 77.8%. On Terminal-Bench 2.0, it posts 69.3%, effectively matching Opus 4.7’s 69.4%, though GPT-5.5 still leads at 82.7%. Cursor’s own CursorBench v3.1 paints a more nuanced picture: Composer 2.5 scores 63.2%, trailing Opus 4.7’s max configuration at 64.8% but beating the model’s default setting at 61.6% and GPT-5.5’s 59.2%. These results position Composer 2.5 as a credible Claude Opus alternative, especially for teams prioritizing consistent multi-benchmark competence over absolute peak scores. However, commentators and developers caution that benchmark wins do not automatically translate into superior real-world coding productivity, particularly for multi-file refactors and complex project contexts.

Cost-Efficient AI Models: Cursor’s 10x Value Proposition
Composer 2.5’s headline advantage is price. Cursor prices the standard model at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. Cursor claims up to 10x cost efficiency relative to comparable frontier models, making Composer 2.5 one of the most cost efficient AI models positioned against Claude Opus 4.7 and GPT-5.5. This pricing is central to Cursor’s strategy: by offering near-parity performance on key coding benchmarks at significantly lower token rates, it targets engineering teams that need large-scale AI coding assistance without runaway budgets. For organizations experimenting with AI coding assistant deployments across entire engineering orgs, cost predictability and lower spend per token could be decisive in vendor selection.
Training Strategy: Reinforcement Learning and 25x Synthetic Tasks
Composer 2.5 does not rely on a new base model; it continues to use the open-source Moonshot Kimi K2.5 checkpoint as its foundation. Cursor instead bets on post-training and data scaling to extract more performance. The model was trained on roughly 25 times more synthetic tasks than its predecessor, dramatically increasing exposure to long-horizon coding scenarios. Cursor also introduces targeted reinforcement learning with localized textual feedback, allowing the system to correct specific mistakes during long task rollouts rather than only adjusting global behavior. In parallel, improved behavioral calibration focuses on communication style, coding consistency, and adherence to nuanced instructions—traits that matter for sustained collaboration between developers and an AI coding assistant. Early internal and community feedback indicates better handling of tool calls and more robust long-running edits, reinforcing the idea that smarter tuning on a stable base can rival or surpass more expensive frontier models.
From Benchmarks to Real Projects: The Validation Still Ahead
While Composer 2.5’s metrics against Claude Opus 4.7 and GPT-5.5 look promising, the critical test lies in real repositories, not leaderboards. Developers will judge the model on its ability to reliably execute live multi-file refactors, maintain consistency with existing codebases, and recover gracefully from partial failures over long sessions. Community voices already highlight that benchmark intelligence often diverges from practical usefulness; models that score higher can still generate code requiring heavy cleanup or missing project-specific context. Cursor acknowledges this gap and positions Composer 2.5 as a step toward more dependable long-running agent behavior, rather than a benchmark-only play. If the model’s claimed improvements in complex instruction-following, communication, and cost efficiency hold up in day-to-day workflows, Cursor could reclaim momentum as a leading Claude Opus alternative. Until then, Composer 2.5 remains a high-potential entrant awaiting real-world validation.