Flash-Tier Model, Pro-Level Results
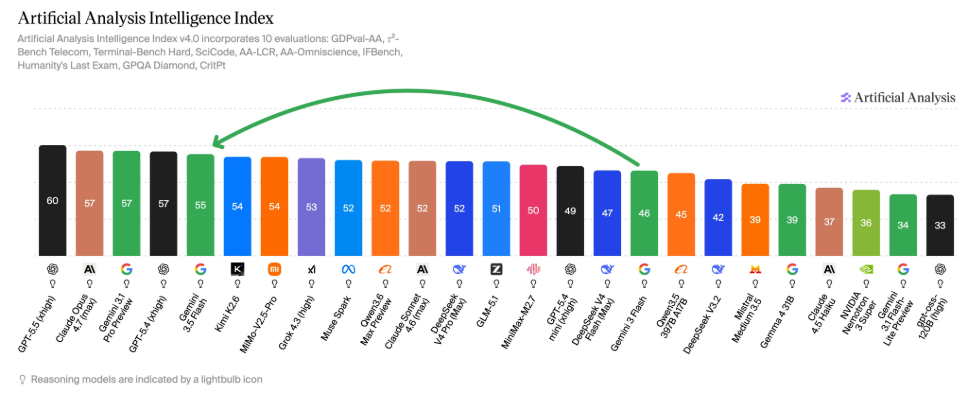
Gemini 3.5 Flash arrives with a surprisingly aggressive promise: a supposedly lightweight, speed-focused model that beats Google’s own Gemini 3.1 Pro on many key benchmarks. Officially positioned as the default Gemini model after its debut at Google I/O, 3.5 Flash is tuned for “frontier-level intelligence at exceptional speed,” shrinking the traditional gap between Flash and Pro tiers. On the Artificial Analysis Intelligence Index, it scores 55 and ranks fifth overall, ahead of several premium models, including Grok 4.3 (high) and Claude Sonnet 4.6 (max). At the same time, Google says it now rivals large flagship models for coding and agentic tasks, despite a separate 3.5 Pro model still to come. For developers, the message is clear: the old assumption that “faster” means “weaker” no longer holds when evaluating AI model performance and capability.
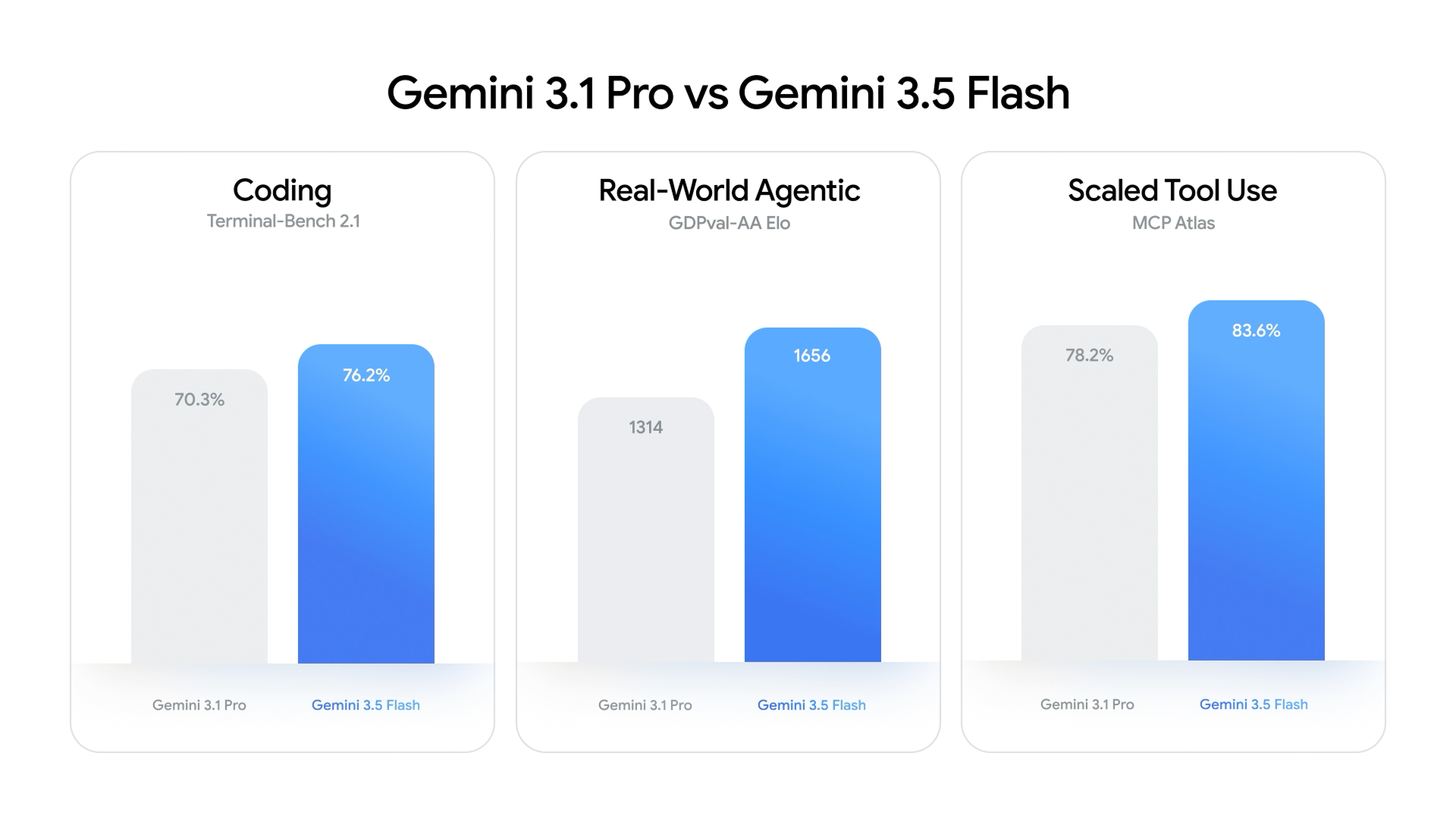
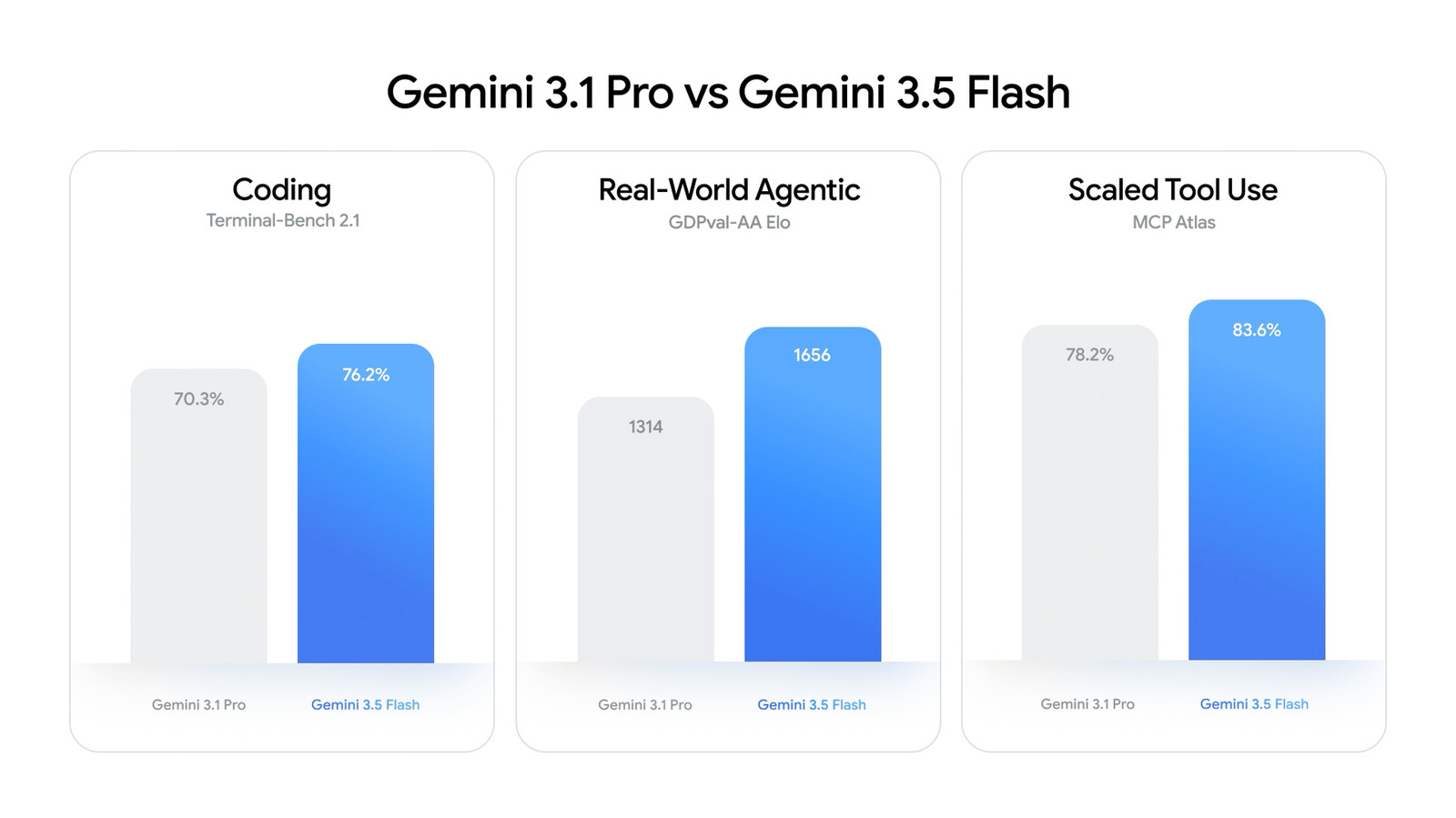
Benchmark Numbers: Flash Surpasses Gemini 3.1 Pro
On paper, Gemini 3.5 Flash doesn’t just close the gap with Gemini 3.1 Pro—it overtakes it where developers care most. In coding benchmarks, it reaches 76.2% on Terminal-Bench 2.1 compared with 3.1 Pro’s 70.3%, signaling stronger reliability for IDE copilots, refactoring and test generation. On GDPval-AA, which tracks real-world, economically valuable agentic tasks, 3.5 Flash scores an Elo of 1,656, far above Gemini 3 Flash’s 1,204 and Gemini 3.1 Pro’s 1,314, and just behind GPT-5.4 (xhigh). It also leads 3.1 Pro on scaled tool use, hitting 83.6% on MCP Atlas versus 78.2%. Multimodal performance is similarly strong: 3.5 Flash posts 84% on MMMU-Pro, nudging ahead of Gemini 3.1 Pro’s 82%. These coding benchmarks and task scores substantiate Google’s claim that this faster AI model competes directly with recent flagship model releases.
Speed, Latency and the New Developer Baseline
The defining trait of Gemini 3.5 Flash is speed. Google reports throughput of 289 output tokens per second—roughly four times faster than other frontier models highlighted at I/O and around 70% faster than Gemini 3 Flash in Artificial Analysis testing. On a speed-versus-intelligence scatter plot, 3.5 Flash sits in the coveted upper-right quadrant alongside Gemini 3.1 Pro and Gemini 3.1 Flash-Lite, meaning high capability without the usual latency penalty. For developers, this changes how they think about AI-assisted workflows: long-horizon agents can iterate quickly enough to feel interactive, code reviews can run inline during editing, and multi-step refactors no longer require background batch jobs. Fast response is no longer a mere usability perk; it becomes a structural advantage that allows teams to embed AI deeper into CI pipelines, testing harnesses and real-time developer tooling.
Agentic Workflows Over Massive Codebases
Gemini 3.5 Flash is engineered for agentic behavior rather than just single-shot prompts. Google highlights its ability to plan and reason across massive codebases, spin up subagents in parallel and sustain multi-step workflows over extended periods. Benchmark results support this positioning: its GDPval-AA Elo and MCP Atlas scores indicate stronger tool use, orchestration and real-world task execution than Gemini 3.1 Pro. Artificial Analysis notes that 3.5 Flash uses an average of 49 turns per task—one of the highest among top models—which reflects deeper multi-step reasoning chains. That higher turn count, however, lets the model decompose complex coding tasks, coordinate calls to tools and APIs, and revise outputs iteratively. For developers building agents that triage bugs, migrate services or manage infrastructure tasks, this long-horizon behavior is critical to achieving production-grade reliability.
Tradeoffs: Cost, Hallucinations and Tier Expectations
The performance gains of Gemini 3.5 Flash come with tradeoffs developers must weigh. Artificial Analysis reports that hallucination rates drop sharply relative to Gemini 3 Flash—from 92% to 61% on the AA-Omniscience benchmark—but still lag behind leading models like GPT-5.5 and Claude Opus 4.7. Architecturally, the model’s long, 49-turn interaction traces can drive up token consumption. Pricing compounds this: Gemini 3.5 Flash is listed at USD 1.50 (approx. RM6.90) per million input tokens and USD 9 (approx. RM41.40) per million output tokens, roughly three times the cost of Gemini 3 Flash. Combined with heavier agentic workloads, that pushed the total cost of running the Artificial Analysis Intelligence Index to USD 1,552 (approx. RM7,140), noticeably above Gemini 3.1 Pro. The bigger implication is strategic: Flash-tier models are now eclipsing Pro-tier models from just months ago, forcing teams to reconsider what “Pro” and “flagship” really mean when choosing coding and agentic foundations.