A Cheaper Contender in the AI Coding Assistant Race
Cursor is pushing back into the spotlight with Composer 2.5, an in-house AI coding assistant designed to compete directly with premium enterprise tools. Built on Moonshot’s Kimi K2.5, the model aims to free Cursor from its reliance on external providers while restoring its early lead in AI-assisted coding. The company positions Composer 2.5 as a cost-effective development tool that can handle complex, long-running tasks without the price tag typically associated with frontier models. Cursor says the new release delivers significant gains in intelligence, reliability, and instruction-following, especially for multi-step coding workflows. For developers and teams frustrated by rising AI infrastructure bills, the pitch is simple: Composer 2.5 promises near-frontier performance for code generation and debugging at a fraction of the cost competitors charge, making affordable AI programming more accessible to mainstream engineering organizations.

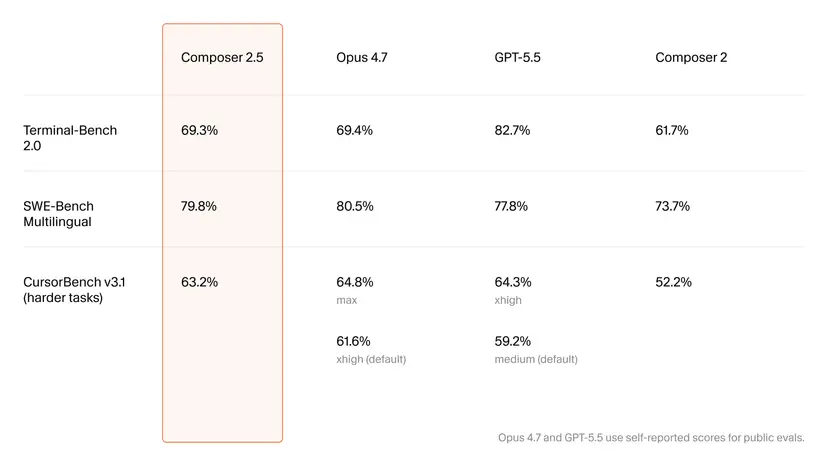
Benchmark Performance: Matching Claude Opus While Underpricing Frontier Models
On headline code generation benchmarks, Composer 2.5 is closer to top-tier models than its pricing suggests. Cursor reports a 79.8% score on SWE-Bench Multilingual, nearly tied with Claude Opus 4.7 at 80.5% and ahead of GPT-5.5’s 77.8%. On Terminal-Bench 2.0, Composer 2.5 reaches 69.3%, essentially matching Opus 4.7’s 69.4% and improving sharply over Composer 2. The in-house CursorBench v3.1, designed to stress harder, real-world tasks, shows Composer 2.5 at 63.2%, ahead of GPT-5.5’s default setting and close to Opus 4.7’s maximum configuration. Cursor pairs these results with a cost-efficiency chart showing Composer 2.5 achieving around 63% on CursorBench at under USD 1 (approx. RM4.60) per task, while rival models cost several times more for similar or lower scores. For teams evaluating AI coding assistants, the message is clear: benchmark parity at meaningfully lower run-time cost.

How Synthetic Training and RL Deliver Long-Running Coding Reliability
Under the hood, Composer 2.5 relies heavily on scaled synthetic training and more precise reinforcement learning to improve behavior on long-running coding tasks. Cursor says 85% of total compute went into its own training and RL on top of Kimi K2.5, with 25 times more synthetic tasks than in Composer 2. These synthetic scenarios are designed to mimic complex, multi-file changes and tool-using workflows that real engineering teams face. A key innovation is targeted RL with localized textual feedback: instead of a single reward at the end of a long rollout, Cursor injects short hints exactly where the model makes a mistake, such as a faulty tool call. This local signal helps the model learn better credit assignment over trajectories spanning hundreds of thousands of tokens, making it more stable for extended refactors, migrations, and iterative debugging sessions typical in enterprise codebases.
Behavioral Calibration for Enterprise Use: Style, Consistency, and Tool Calls
Beyond raw accuracy, Composer 2.5 focuses on behavioral calibration to make AI coding assistance more usable in day-to-day development. Cursor highlights improvements in communication style, effort calibration, and coding consistency, all shaped by its expanded synthetic data regime and RL training. The model is tuned to follow nuanced instructions, respect project conventions, and manage tool calls more reliably than earlier versions. Internal benchmarks and early user feedback suggest better performance on sustained coding tasks, though some reports still note occasional context loss and mode confusion during agent-style sessions. This underscores a key reality for cost-effective development tools: intelligence on a code generation benchmark does not automatically translate into frictionless productivity. Cursor’s bet is that by combining high-quality synthetic training with fine-grained feedback, Composer 2.5 will close that gap enough for enterprises to consider it a viable, lower-cost alternative to more expensive coding AI platforms.
Cost Structure and Market Positioning Against Enterprise Coding AI
Composer 2.5’s economic model is central to Cursor’s strategy. The standard version is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, substantially undercutting typical frontier-model rates. A faster default variant is available at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens, giving teams a choice between maximum cost-efficiency and higher throughput. Cursor claims up to 10x cost efficiency versus comparable competitors when looking at cost per successful task on its own benchmark suite. Coupled with widespread existing adoption among large companies, Composer 2.5 is clearly positioned as a direct alternative to premium, enterprise-focused AI coding tools: similar benchmark performance, more control over the model stack, and significantly lower variable costs for teams seeking scalable, affordable AI programming assistance.