
Why AI Matters for Memory Chip Cost Optimization
Memory has quietly become one of the hardest hardware costs to control, especially as AI servers, GPUs and even routers demand more DRAM and NAND. Many organizations still buy RAM following old rules of thumb, routinely overprovisioning “just in case.” When prices surge, that habit becomes a direct hit to your budget and limits how many systems you can deploy. AI gives you a way to fight back. Instead of guessing, you can use AI tools to profile how much memory your workloads actually use, then translate those insights into concrete chip cost optimization strategies. That means buying only the capacity you genuinely need and choosing the most cost‑effective configurations without compromising performance. With the right data, AI memory pricing analysis becomes a powerful lever in negotiations with suppliers, helping you justify requests for better rates, discounts, and alternative configurations.
Profile Your Real DRAM and NAND Needs with AI
The first step toward better memory chip deals is understanding your true working set. Start by collecting detailed usage data from your environment: hypervisors like ESXi or Proxmox, cloud monitoring, or OS tools such as Task Manager, top, htop, or vmstat. Look beyond “free memory” to metrics like active memory, swap activity, compression, ballooning, and page faults. Modern operating systems aggressively cache, so apparent usage can be misleading. Once you have a few weeks of data, feed it into an AI agent or large language model. Ask it to highlight hosts that never exceed a certain working‑set threshold, VMs with high allocation but low p95 usage, nodes with swap activity, and workloads that are clearly memory‑resident and should not be cut. This AI‑assisted profiling replaces guesswork with an evidence‑based capacity target for DRAM and, where applicable, NAND‑backed cache tiers.
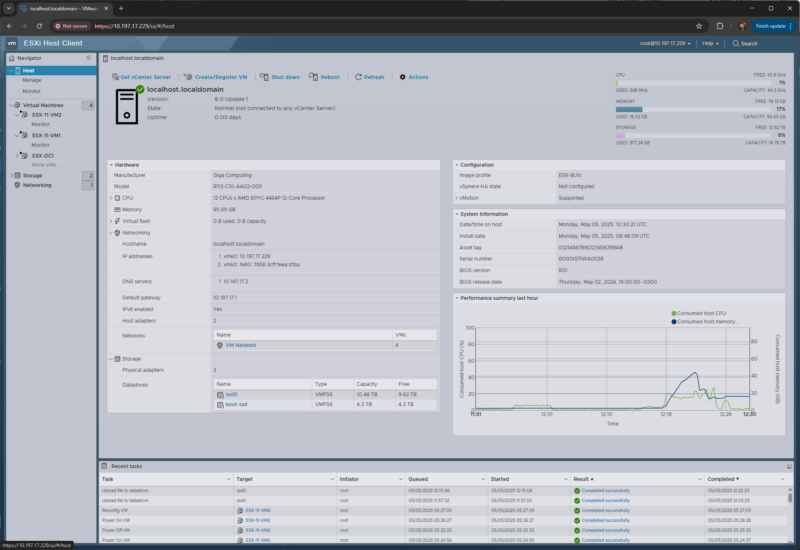
Turn Utilization Insights into Stronger Memory Chip Negotiations
Once AI has surfaced which systems are overprovisioned and which are tight on memory, you can turn those insights into leverage during NAND and DRAM pricing discussions. Build a simple map of allocated versus observed peak memory by host or VM. This makes pockets of slack immediately visible and supports a right‑sizing plan you can show suppliers. With a clear capacity target, you can ask for quotes on specific DIMM sizes, ranks, and channel populations instead of generic “more memory” requests. You can also simulate lower‑cost configurations—fewer or smaller DIMMs, different speed grades—and use AI to estimate performance impact. If there is a small slowdown, the analysis can show whether the savings could fund additional cores or nodes to more than offset it. Suppliers respond better when you negotiate from a detailed, data‑driven memory plan rather than rough estimates.
Case Example: Fleet Memory Audit to Cut Overprovisioning
Consider an organization running a mixed fleet of virtualized servers. Historically, each new box shipped with large DRAM allocations because memory was relatively cheap, and no one wanted to risk performance issues. By aggregating observability data across hundreds of hosts and pushing it through an AI agent, the team quickly identified machines that never went above a modest fraction of their installed RAM, plus a handful that only spiked during backups or month‑end jobs. AI helped group systems into categories: safe candidates for aggressive right‑sizing, workloads better suited to ballooning or soft limits instead of hard cuts, and true memory‑resident databases that should remain generously provisioned. The outcome was a concrete redesign of memory configurations for the next procurement cycle. Instead of copying past builds, the team had a targeted DRAM and NAND plan that directly reduced overbuying and strengthened their position in upcoming supplier negotiations.
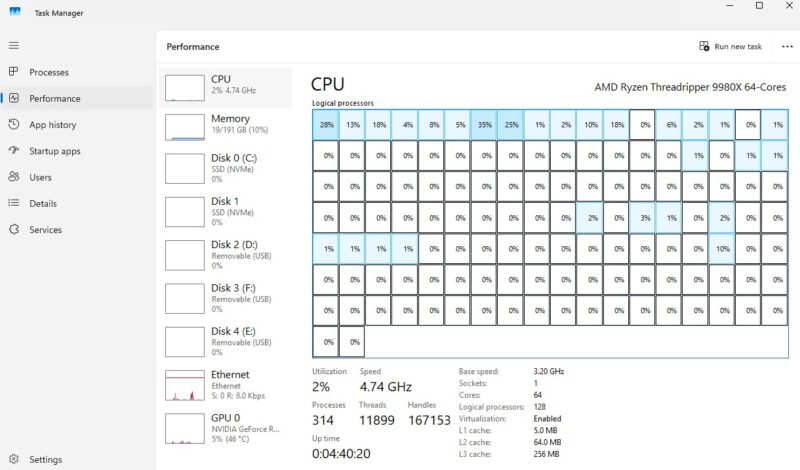
Adapting These Tactics for Enterprises and Individual Buyers
AI‑driven memory planning scales from a single workstation to entire data centers. Large enterprises can combine Prometheus, Grafana, or cloud monitoring with AI agents to continuously review memory pressure, swap behavior, and Kubernetes pod limits, feeding those results into their sourcing strategy for DRAM and NAND. Procurement teams gain hard data to demand better AI memory pricing, insist on configurations that match actual workloads, and compare offers across vendors. Individual buyers and small teams can follow the same pattern on a smaller scale: collect memory stats from a desktop, lab server, or VPS, then ask an AI assistant whether the p95 working set justifies a lower‑capacity kit or a smaller cloud instance. In both cases, the goal is the same: replace fear‑based overprovisioning with data‑driven confidence, so every memory chip you buy contributes directly to performance and value—not wasted headroom.