A Comeback Bid in a Crowded Coding Assistant Market
Cursor’s release of Composer 2.5 is a strategic attempt to regain ground in a market now dominated by Claude and OpenAI-branded coding tools. Once seen as an early leader in AI-assisted development, Cursor has more recently been pressured by Anthropic’s ability to bundle Claude Code at aggressive prices while still selling inference to Cursor. Building its own model is Cursor’s way of breaking that dependency and reshaping AI code assistant pricing on its own terms. Composer 2.5 arrives as Cursor customers, including many large enterprises, are re-evaluating their stack around autonomous agents rather than just smart IDEs. The new model is framed as Cursor’s agent-style answer: a coding system capable of sustained, multi-step work across existing projects, not just snippet-level autocompletion. Against this backdrop, the question is whether Composer 2.5 can function as a credible Claude Opus alternative in both capability and cost efficiency.

Benchmark Results: Narrowing the Gap with Opus and GPT
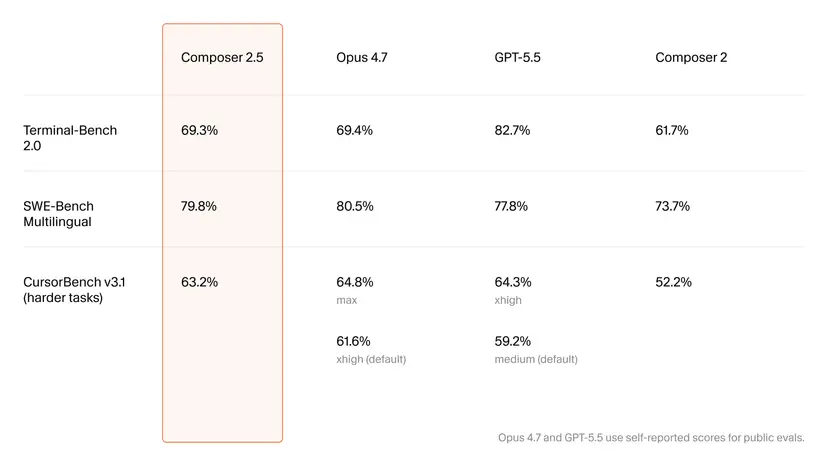
On headline benchmarks, Composer 2.5 now sits within striking distance of Anthropic and OpenAI’s top-tier coding models. On SWE-Bench Multilingual it posts a 79.8% score, just behind Opus 4.7’s 80.5% yet ahead of GPT-5.5’s 77.8%, suggesting comparable problem-solving for real-world software issues. Terminal-Bench 2.0 shows a similar story, with Composer 2.5 at 69.3% versus Opus 4.7’s 69.4%, while GPT-5.5 leads at 82.7%. On CursorBench v3.1, a harder internal benchmark focused on tougher tasks, Composer 2.5 reaches 63.2%. Opus 4.7 can edge it out at 64.8% on a max setting, but its more typical xhigh setting drops to 61.6%, with GPT-5.5 at 59.2%. For developers comparing coding benchmarks, the result is clear: Cursor no longer lags by a generation and can legitimately claim performance in the same class as premium assistants.

Cost Efficiency: Undercutting Premium Models with New Pricing
The most aggressive part of Cursor’s pitch is cost efficiency. Composer 2.5’s standard tier is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with Cursor describing up to 10x cost efficiency improvements over earlier Composer versions. A faster variant, set as the default, is listed at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. While exact prices for Opus 4.7 and GPT-5.5 are not given in the sources, Cursor explicitly positions Composer 2.5 as undercutting those premium models while offering similar benchmark performance. For teams tracking AI code assistant pricing as closely as raw capability, this combination of lower token costs and near-parity scores on key evaluations could shift procurement discussions toward Cursor for sustained, heavy IDE use.
Training Strategy: Synthetic Data, RL, and Behavioral Calibration
Composer 2.5 is notable not for a new base model, but for a new training strategy. Cursor keeps Moonshot’s Kimi K2.5 as the underlying checkpoint and instead leans on heavier post-training to lift real-world coding performance. The company reports training on 25 times more synthetic tasks than before, coupled with more complex reinforcement learning environments and localized textual feedback. This targeted reinforcement learning is meant to correct the model during long task rollouts, improving consistency when it is acting like a coding agent rather than a one-shot assistant. Cursor also emphasizes behavioral calibration: refining communication style, instruction-following, and how aggressively the model edits code. The intention is to reduce friction in extended sessions, where small misunderstandings can compound into refactor churn. In practice, this means Cursor is betting that smarter tuning and synthetic training can rival rivals’ larger or more expensive base models without a full architectural reboot.
Long-Running Coding Work as the Real Test
Beyond benchmarks, Composer 2.5 is framed as a tool for longer coding jobs and multi-file changes, areas where many developers feel today’s models still stumble. Internal tests and early user feedback cited by Cursor highlight better handling of complex instructions, improved tool calls, and more reliable behavior across extended sessions. However, even supportive observers caution that benchmark wins do not automatically translate into productivity gains. Developers will ultimately judge whether Composer 2.5 can keep project-wide context straight, perform live multi-file refactors, and maintain codebase consistency over hours rather than prompts. If it delivers, Cursor could re-establish itself as a cost-efficient Claude Opus alternative that blends competitive coding benchmarks comparison with significantly lower operating costs. If not, Composer 2.5’s numbers will remain impressive on paper but less decisive in day-to-day engineering workflows.