Multimodal AI models move from novelty to default expectation
Multimodal AI models are systems that can understand or generate more than one type of data—such as text, images, audio, or video—within a single model, enabling richer applications like conversational image editing, code reasoning across diagrams, and voice-driven assistants that handle documents and media together. Over the past year, multimodal capabilities have moved from an advanced feature to something closer to table stakes for major vendors. The latest launches from Microsoft and MiniMax show how quickly this baseline is shifting. Microsoft is tying voice, image, and transcription into a single MAI family, while MiniMax is focusing on long-context language models that can read and remember huge prompts spanning code, documents, and media. For developers, the question is no longer whether models understand multiple modalities, but how well they integrate them into reliable, affordable, and easy-to-use APIs.
MAI-Image-2.5 climbs the text-to-image leaderboard
Microsoft’s MAI-Image-2.5 has debuted at number three on the Arena text-to-image leaderboard, behind OpenAI’s gpt-image-2 and Google’s Nano Banana 2. This new model targets both quality and control: it follows instructions closely, renders text more reliably than earlier MAI-Image versions, and produces detailed, coherent images across a wide range of styles. According to Microsoft, MAI-Image-2.5 is “a step change in quality” over MAI-Image-2 with major gains in text rendering, stylized illustration, and commercial imagery. Visual reasoning is another focus, with stronger handling of objects, scene structure, lighting, scale, and spatial relationships. At Build, Microsoft is expected to ship two variants: a high-quality model and a faster MAI-Image-2.5e, plus support for image uploads so developers can edit as well as generate images, keeping pace with rival multimodal AI models from other large providers.
MAI-Transcribe-1.5 and MAI-Voice-2 bring speech into the stack
Alongside its image push, Microsoft is rounding out its MAI stack with speech-focused tools. MAI-Transcribe-1.5 builds on an earlier speech-to-text system that already claimed the lowest word error rate across 25 languages, offering a modest quality bump for transcription-heavy workloads. The bigger leap is MAI-Voice-2, a multilingual successor to MAI-Voice-1 that started with English only. The new model adds German, Australian and US English, Spanish, French, Hindi, Indonesian, Italian, Japanese, Korean, Dutch, Portuguese, Turkish, Vietnamese, and Chinese, and introduces a wider emotional range including tones such as angry, confused, and embarrassed, plus whisper capability. All three models—MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2—are designed to feed into Copilot, Teams, and Azure Speech, giving developers a more coherent path to build end-to-end voice, image, and text experiences on a single platform.
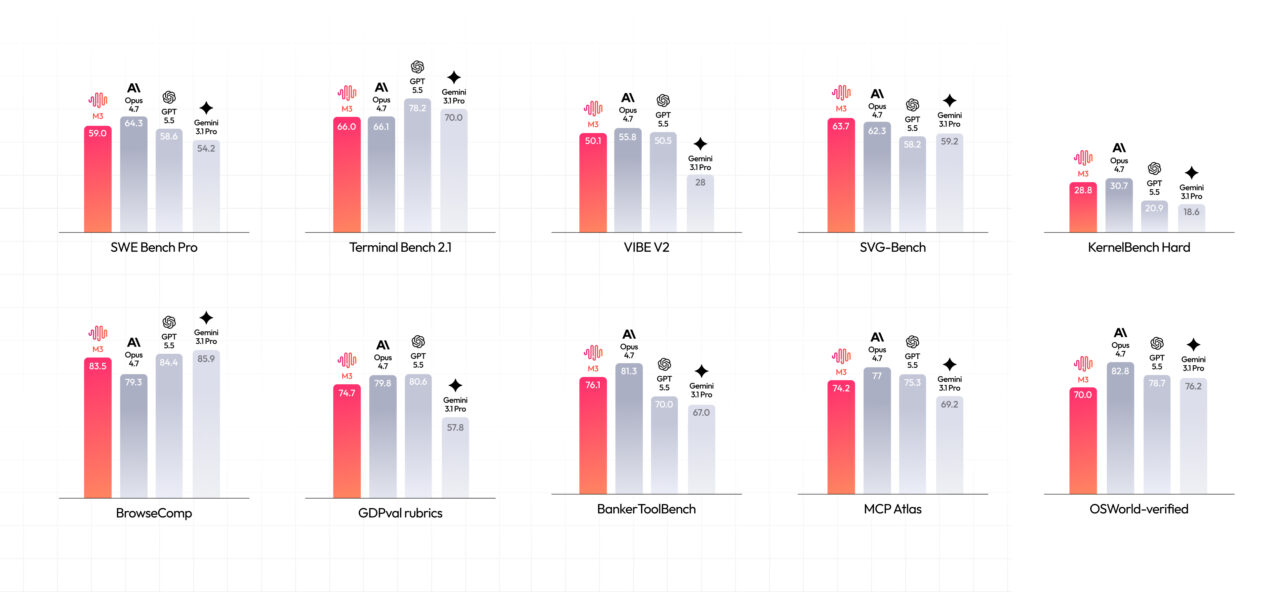
MiniMax’s M3 AI model bets on 1M-token long context
MiniMax’s M3 AI model targets a different frontier: long-context AI with multimodal input. M3 offers a headline 1 million-token context window and guarantees at least 512000 tokens, giving developers firmer planning numbers for large projects that involve long codebases, chained agents, or multi-document reasoning. The model supports text, image, and video input with text output, and is exposed through OpenAI-compatible endpoints to fit into existing tooling. MiniMax positions M3 as a single architecture that combines coding skills, agent capabilities, and native multimodal processing. Under the hood, it uses a Grouped-Query Attention backbone and MiniMax Sparse Attention to reduce prefill cost and speed decoding at million-token scale. M3 scores 59.0 on SWE-bench Pro and 66.0 percent on Terminal-Bench 2.1, but independent accuracy data is still limited, leaving developers to test the trade-off between speed and reliability in their own workflows.
What these multimodal and long-context shifts mean for developers
Taken together, Microsoft’s MAI family and MiniMax’s M3 signal a maturing phase for multimodal AI models where integration and context length matter as much as raw benchmarks. MAI-Image-2.5’s text-to-image leaderboard position shows Microsoft is competing seriously on generative quality while tying image, voice, and transcription into its existing developer ecosystem. MiniMax, by contrast, is betting that long-context language models with 1M-token prompts and multimodal input will reshape how teams work across code, diagrams, screenshots, and documents in a single session. For developers, these moves mean new design patterns: combining voice input with visual editing, letting agents scan entire repositories without chunking, or building Copilot-style tools that keep richer histories. The next test will be real-world constraints—latency, cost, and model accuracy—once broader access and promised weight releases arrive and everyday teams stress these systems at scale.





