What Claude Opus 4.8 Is and Why Its Benchmarks Matter
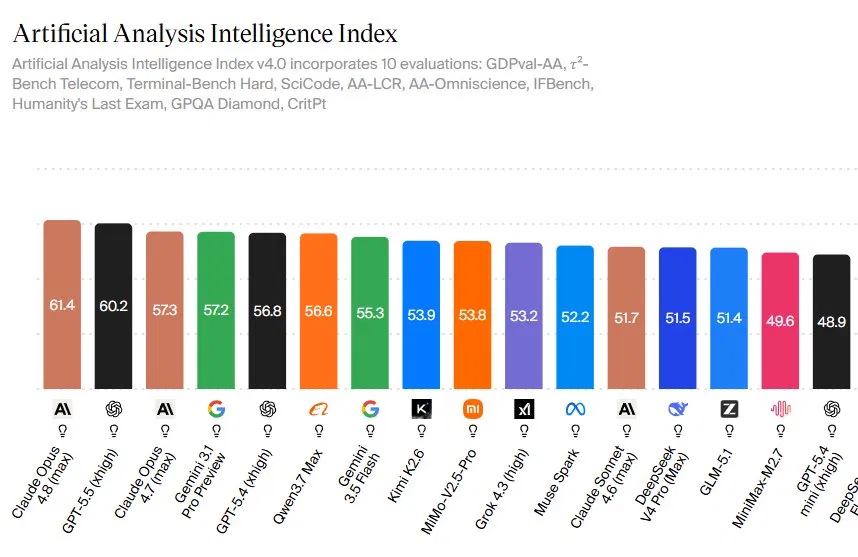
Claude Opus 4.8 is Anthropic’s latest flagship large language model, designed to act as an autonomous digital worker that can write code, use computers, and complete complex knowledge tasks with minimal supervision across long-running sessions. That means its benchmark results say less about trivia scores and more about how it might perform as a practical assistant on real-world work. On the Artificial Analysis Intelligence Index v4.0, Opus 4.8 scores 61.4, putting it ahead of GPT-5.5 at 60.2 and its predecessor Opus 4.7 at 57.3. The index blends ten demanding evaluations, from agentic coding and computer use to reasoning-heavy tests like Humanity’s Last Exam and GPQA Diamond. What stands out is that Opus 4.8’s lead is not built on a single outlier metric; it is a consistent edge across multiple domains.
Artificial Analysis Intelligence Index: A New Leader in AI Benchmark Rankings
The Artificial Analysis Intelligence Index v4.0 is one of the broadest AI benchmark rankings available, combining ten evaluations including GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. Claude Opus 4.8’s 61.4 score places it first, ahead of GPT-5.5 at 60.2 and Gemini 3.1 Pro Preview at 57.2. According to OfficeChai, “Claude Opus 4.8 leads the Artificial Analysis Intelligence Index v4.0 with a score of 61.4 — a clear margin above GPT-5.5’s 60.2 and Claude Opus 4.7’s 57.3.” The 1.2-point gap to GPT-5.5 may look small, but the index is designed so slight shifts reflect consistent gains across domains rather than flukes in isolated tests. Below the two leaders, mid-tier models like Qwen3.7 Max, Gemini 3.5 Flash, Kimi K2.6, and MiMo-V2.5-Pro cluster tightly between 53 and 57.
GDPval-AA and the GPT-5.5 Comparison on Real-World Tasks
If the composite index shows breadth, the GDPval-AA benchmark highlights real-world impact. Developed by Artificial Analysis using its Stirrup harness, GDPval-AA measures agentic performance on work-like tasks that use web and shell access across 44 occupations and 9 major industries. Claude Opus 4.8 debuts here with an Elo of 1890 at its max effort setting, a 137-point jump over Opus 4.7 and 121 points ahead of GPT-5.5’s 1769. That margin corresponds to an implied win rate of about 67% against GPT-5.5 xhigh in head-to-head comparisons. The story is not only about strength but also efficiency: Opus 4.8 completes GDPval-AA tasks with 15% fewer turns and 35% fewer tokens than Opus 4.7, though it still uses around 30% more turns per task than GPT-5.5. For enterprises, the trade-off is higher task success versus interaction cost.
Benchmark Improvements Over Opus 4.7 and Domain Strengths
Beyond GDPval-AA, Anthropic’s internal evaluations point to broad gains over Opus 4.7. On SWE-Bench Pro, a demanding agentic coding benchmark, Opus 4.8 scores 69.2%, compared with 64.3% for Opus 4.7, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. On Humanity’s Last Exam, which tests multidisciplinary reasoning, it reaches 49.8% without tools and 57.9% with tools, leading all rivals. Opus 4.8 also raises agentic computer use on OSWorld-Verified to 83.4%, slightly ahead of Opus 4.7’s 82.8% and comfortably ahead of GPT-5.5 at 78.7% and Gemini 3.1 Pro at 76.2%. Knowledge work is another bright spot: the model’s 1890 GDPval-AA score tops both GPT-5.5 and Opus 4.7. The one area where it does not lead is Terminal-Bench 2.1, focused on agentic terminal coding, where GPT-5.5’s 78.2% edges Opus 4.8’s 74.6%.
What Opus 4.8’s Lead Means for Large Language Model Performance
Taken together, these benchmarks place Claude Opus 4.8 at the top of current AI benchmark rankings for both breadth and practical performance. It consistently outperforms GPT-5.5 on real-world tasks like GDPval-AA and on agentic coding and computer-use metrics, while delivering measurable efficiency gains over Opus 4.7. Anthropic has kept pricing at Opus 4.7 levels and added a Fast Mode that runs the same model at about 2.5x speed at one-third the standard cost, which could soften concerns about turn-heavy behavior in high-volume workflows. The model is positioned squarely for agentic use cases: longer, more autonomous work sessions in tools like Claude Code, where it can plan, coordinate multiple subtasks, and follow through across a repository. In a race where top spots on leaderboards change hands quickly, Opus 4.8 currently sets the pace for large language model performance.





