What Gemma 4 12B Is and Why It Matters for Local AI
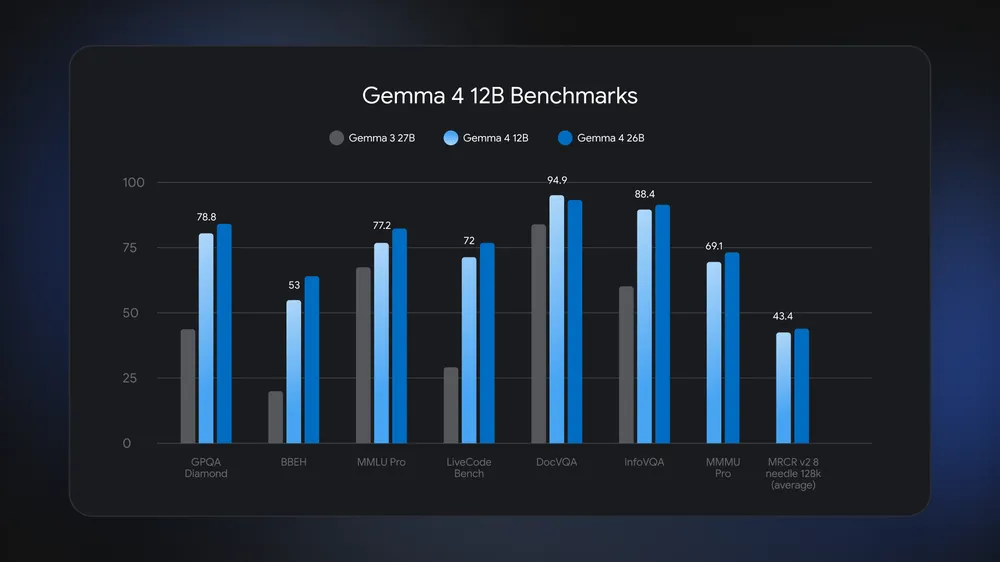
Gemma 4 12B is a 12‑billion‑parameter multimodal AI model from Google DeepMind that runs entirely on a standard 16GB laptop, handling text, images, audio, code, and tool calls without relying on cloud infrastructure, making it an attractive choice for privacy‑first workflows, offline AI processing, and edge computing scenarios where internet access, data control, and hardware cost are all constraints. According to Google DeepMind, Gemma 4 12B is the first mid‑sized Gemma model to drop separate multimodal encoders and route images and audio directly into the language backbone, which sharply reduces memory use and latency. Positioned between phone‑class models and the larger 26B and 31B variants, it aims to give developers a practical multimodal AI laptop experience rather than demanding a dedicated workstation. Google says it stays close to the 26B Mixture of Experts on benchmarks while beating the older Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA.

Under the Hood: Unified, Encoder‑Free Multimodal Design
Most multimodal local AI models bolt on separate vision and audio encoders before data reaches the language core, which inflates parameters and memory footprint. Gemma 4 12B instead uses a unified, encoder‑free architecture that sends multimodal inputs straight into the backbone. For images, a compact 35‑million‑parameter vision embedder splits them into 48×48 pixel patches and projects each patch into the model’s hidden space with a single matrix multiplication, replacing 27 vision transformer layers and roughly 550 million parameters in other medium‑sized Gemma 4 models. Audio receives even leaner treatment: raw 16 kHz waveforms are cut into 40‑millisecond frames and mapped directly into the same token space as text. This design helps the model stay within the memory limits of consumer hardware while still supporting speech recognition, speaker diarization, code generation, image understanding, and even video analysis in a single unified pipeline.
Performance on Consumer Hardware and Offline AI Processing
Gemma 4 12B is tuned for laptops with 16GB of system RAM or VRAM, using about half the memory of the Gemma 4 26B Mixture of Experts while staying close to it on benchmark performance. That means you can run a capable multimodal AI laptop setup without a high‑end accelerator. The weights are under 18GB and available as open weights under an Apache 2.0 license, which makes them easy to download and keep entirely on‑device. The model also ships with Multi‑Token Prediction (MTP) enabled by default, using spare compute to predict multiple future tokens and speed up generation for longer reasoning or coding tasks. While independent laptop benchmarks still need to validate latency, memory use, and multimodal accuracy on a broad set of machines, the design suggests a clear goal: reliable offline AI processing for complex, multi‑step work on everyday hardware.
Privacy‑First Workflows: Why Local AI Models Change the Trade‑Offs
Running Gemma 4 12B locally changes the privacy and reliability equation compared with cloud‑based AI services. Because the model weights live on your laptop and inputs never have to leave your machine, sensitive screenshots, meeting audio, logs, or prototype code can be processed without going through a remote API. This is especially useful for developers and teams with strict data‑handling rules or intermittent connectivity, where offline AI processing and edge computing are more than a convenience. A local AI model that can listen to speech, read a screenshot, write code, and call tools in one session reduces the need to juggle multiple online services. It also avoids account limits or sudden policy changes affecting critical workflows. You still trade some raw speed and scale compared with large cloud models, but gain stronger control, predictability, and auditability over how your data is used.
Getting Started: Building Local AI Agents and Edge Apps
For developers, Gemma 4 12B is built to slot into existing tools for local AI agents rather than forcing a new stack. The model can be served through LiteRT‑LM as an OpenAI‑compatible local API, so coding assistants such as Continue, Aider, OpenClaw, Hermes, and OpenCode can talk to it with minimal changes. With open weights on Hugging Face and Kaggle and an Apache 2.0 license, you can embed Gemma 4 12B into desktop apps, edge devices, or internal tools without per‑request cloud costs. A typical workflow on a 16GB multimodal AI laptop is straightforward: run a local server, point your IDE or agent framework at the new endpoint, and start testing tasks that mix speech input, code generation, screenshot understanding, and tool calls. From there, you can experiment with specialized prompts, custom tools, and domain‑specific data while keeping everything on your own hardware.





