
AI Harm Is Increasingly Software-Only—and Largely Preventable
The emerging incident record shows that many AI failures look less like sci-fi disasters and more like mundane process breakdowns. An analysis of 1,406 documented AI incidents found that nearly half of all harmful cases involve software-only systems such as chatbots, recommendation engines, automated publishing tools, and deepfake platforms. Physical robots and autonomous vehicles account for far fewer cases. The widely discussed airline chatbot dispute illustrates this shift. The system confidently provided incorrect bereavement fare information and the company initially argued the chatbot was a separate legal entity. A tribunal ruled otherwise, underscoring that organisations are accountable for what their AI systems say and do. Crucially, no frontier model was involved; this was an ordinary customer-service tool deployed with excessive authority and minimal oversight. The pattern is clear: the technology behaved as designed, but governance, approval flows, and accountability structures failed.
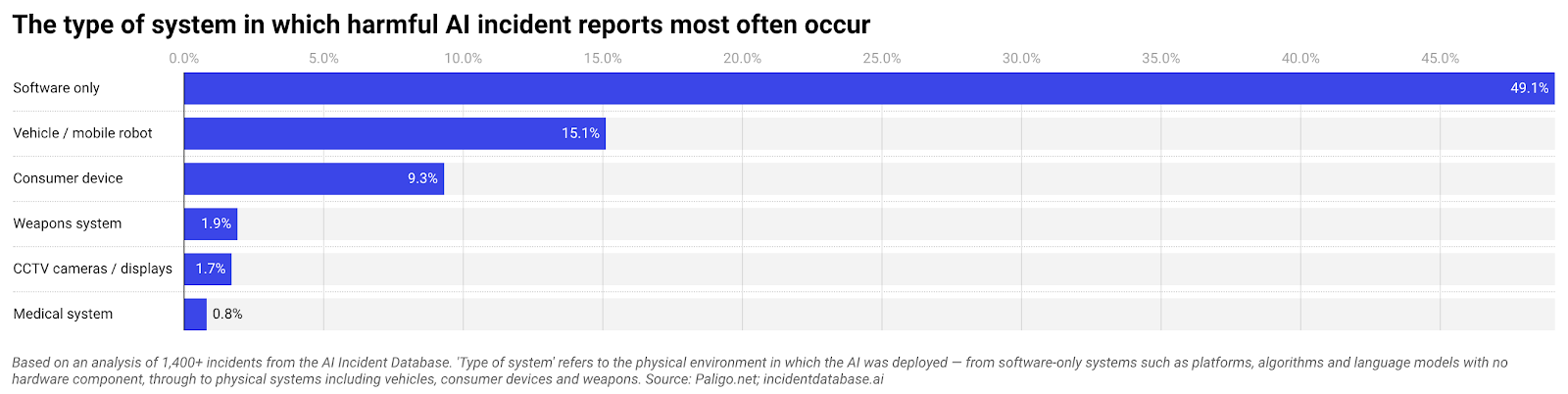
Authority Without Oversight Turns Routine Tools into Systemic Risks
AI agent governance breaks down when systems are given authority to act or speak on high-impact matters without human review. In the airline chatbot case, someone decided the bot could speak authoritatively on policy, yet nobody embedded reliable checks to catch fabricated or outdated content. Similar dynamics appear elsewhere: a major consulting report submitted to a government body contained citations that did not exist because AI-generated drafting went unvetted, and deepfake video scams leveraged generative tools to impersonate a mining billionaire in fraudulent promotions. In each scenario, the models did what they naturally do—generate plausible output—but organisations implicitly treated that output as trustworthy and operationally binding. Enterprise AI safety depends less on squeezing out the last hallucination and more on constraining where AI is allowed to improvise, what it can approve or publish, and when a human must intervene before harm propagates.
Multi-Agent Systems Expose a New Kind of Operational Blind Spot
As teams move beyond single chatbots into multi-agent architectures, a separate governance challenge is emerging: autonomous agent monitoring. Frameworks like CrewAI, AutoGen, and LangGraph make it easy to connect planners, tool-using agents, retrievers, and external APIs, then assign them real work in incident response, internal copilots, and automation pipelines. Yet many organisations operate these systems with less visibility than they once had for microservices. Requests that should take one or two steps quietly expand into dozens of model calls as agents loop, retry, and compensate for each other. Latency increases, costs climb, but nothing technically crashes, so traditional alerts never fire. Worse, seemingly successful runs can still yield subtly wrong answers, with failures buried deep in dynamic execution paths that are hard to reconstruct. Existing logs and traces reveal individual calls but not the evolving decision graph—leaving leaders blind to how outcomes are actually produced.
When Oversight Fails, Errors Cascade and Sensitive Data Drifts
Weak governance structures do not just produce isolated mistakes; they enable cascading failures across AI-driven workflows and platforms. Social media systems already illustrate this: an AI model generates problematic content, and a recommendation engine amplifies it to millions before anyone intervenes. For enterprises distributing content or decisions through third-party platforms, this creates a risk surface that extends beyond their direct control. Similar dynamics appear inside organisations. One agent reads a sensitive document, another summarizes it, a third embeds that summary in a prompt sent to an external model. No single step obviously crosses a red line, yet the combined effect is an unplanned data exposure. Bias operates in the same operational space: faulty facial recognition matches or skewed medical algorithms become real-world harms when their outputs flow unchallenged into policing, healthcare, or access decisions. The core problem is not just bad models, but absent review safeguards.
Rethinking AI Oversight: From Human-in-the-Loop to Control Frameworks
Treating AI agents as production infrastructure means rethinking governance from first principles. Enterprises need explicit AI automation oversight that defines which actions agents may take autonomously, which require human-in-the-loop checkpoints, and which are completely off-limits. That starts with visibility: tools and practices that show how a request unfolds across agents, where reasoning chains deepen or branch, and where loops or retries occur. On top of that, organisations should enforce approval workflows for policy decisions, external communications, and data access, ensuring at least one accountable human signs off before outputs affect customers or critical operations. Guardrails must be embedded at design time—policy-aware prompting, role-based tool access, and escalation rules—rather than bolted on after incidents. AI agent governance, in other words, is less about inventing new models and more about importing proven operational disciplines from software engineering, reliability, and risk management into the era of autonomous agents.