
DeepSeek V4: A Preview Giant Aiming at GPT‑5.5
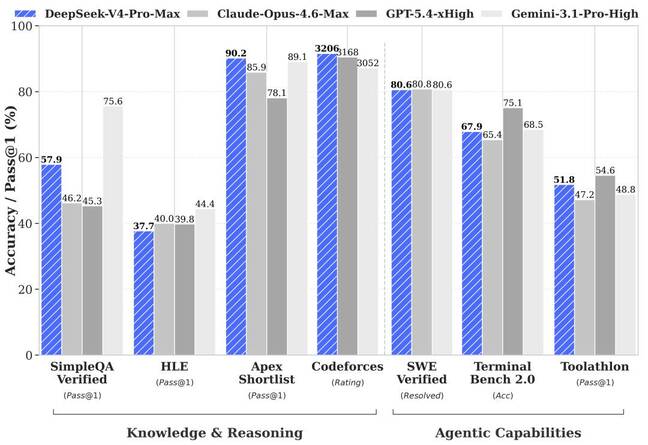
DeepSeek V4 arrives as a pair of open‑weight models—V4‑Pro and V4‑Flash—pitched directly against top‑tier proprietary systems like GPT‑5.5. V4‑Pro weighs in at 1.6 trillion parameters, but only 49 billion are activated per inference thanks to a Mixture‑of‑Experts design, letting it store vast knowledge while keeping compute in check. The Flash variant uses 284 billion total parameters with 13 billion active, targeting interactive, latency‑sensitive workloads. Both models ship in preview with one‑million‑token context windows, roughly enough to hold the entire Lord of the Rings trilogy without collapsing, and can be downloaded for local deployment by anyone able to host them. DeepSeek claims V4‑Pro delivers top‑tier performance in coding benchmarks and narrows the gap with leading closed‑source systems on reasoning and agentic tasks, positioning it as “the best open‑source model available today” while emphasizing efficiency and practical deployment.
The 98% Price Play: DeepSeek’s Direct Shot at GPT‑5.5
The most aggressive part of DeepSeek V4’s pitch is cost. The V4‑Pro API is listed at USD 1.74 (approx. RM8.10) per million input tokens and USD 3.48 (approx. RM16.20) per million output tokens, which DeepSeek says is 98% cheaper than GPT‑5.5 Pro and around one‑twentieth the price of Anthropic’s Opus 4.7. The timing is pointed: DeepSeek unveiled V4 just hours after OpenAI announced GPT‑5.5, signaling a deliberate challenge to premium, closed‑stack offerings. While GPT‑5.5 tops many capability benchmarks, its API list price doubled compared with GPT‑5.4 to USD 5 (approx. RM23.30) for input and USD 30 (approx. RM139.80) for output per million tokens, offset only partly by more efficient token usage. DeepSeek’s message is clear: near‑frontier performance, open weights, massive context—and an order‑of‑magnitude discount designed to undercut GPT‑class systems on cost per experiment and deployment.
Inference Costs, Long Context, and the New Economics of AI
As enterprises explore autonomous agents, large‑context retrieval, and continuous workflows, AI inference costs are moving from a footnote to a boardroom metric. Long‑running agents and million‑token contexts can consume tens of millions of tokens per day in production, turning per‑token pricing into a major constraint on experimentation. DeepSeek V4’s Mixture‑of‑Experts architecture, smaller active parameter sets, and split Pro/Flash tiers are all tuned to reduce serving costs, with the company explicitly marketing “dramatically” lower inference bills and promising further cuts once additional Ascend‑based supernodes come online. By contrast, GPT‑5.5’s higher list prices mean each exploratory workflow, multi‑step agent, or large‑document analysis carries a higher marginal cost, even if better compression partly offsets this. In this context, ultra‑cheap LLM pricing is not just a marketing gimmick; it can change how teams prototype, how often they iterate, and which use cases become economically viable at scale.
Strengths, Gaps, and the Integration Edge of GPT‑5.5
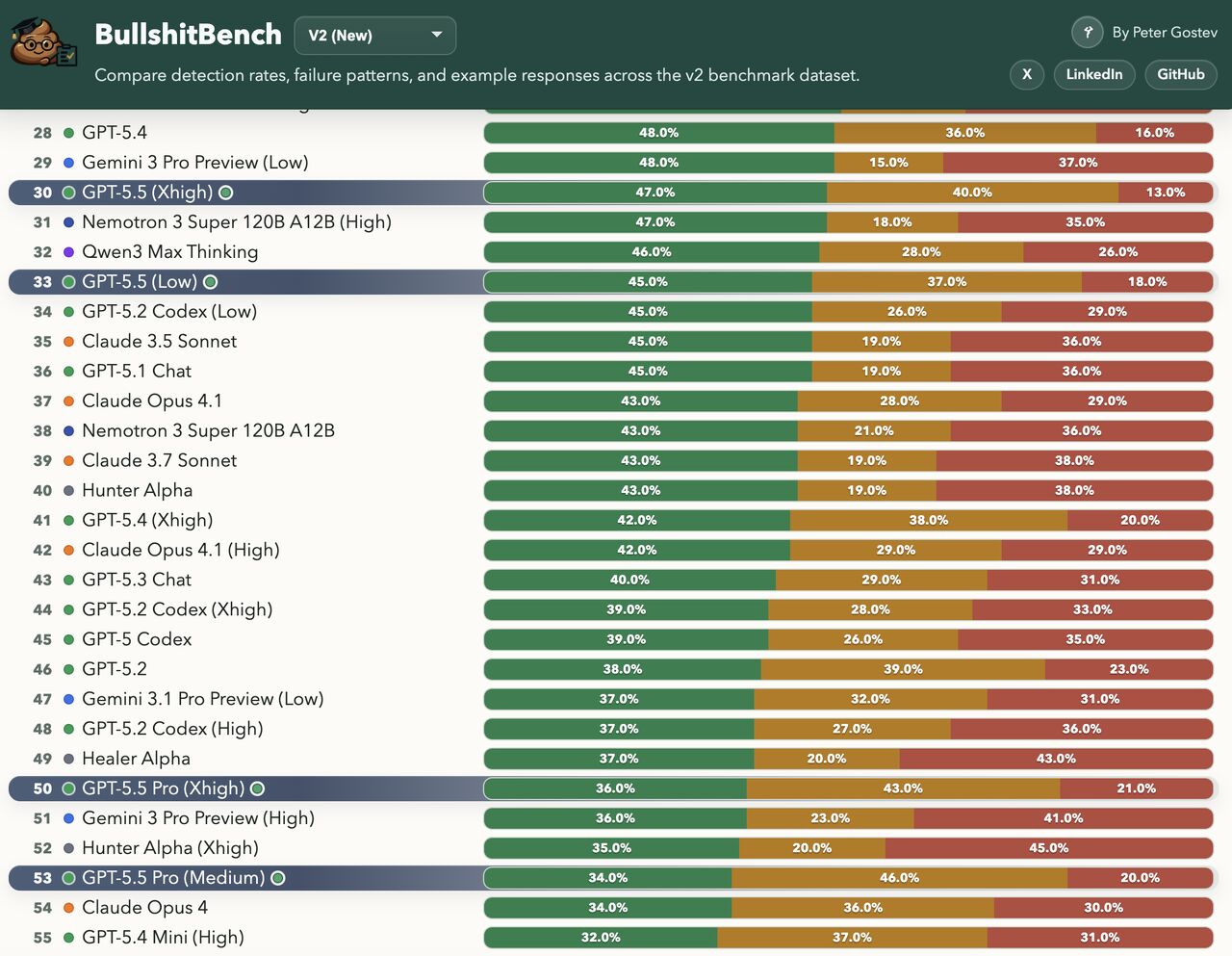
DeepSeek V4 is still in preview and arrives with several open questions. Benchmark charts suggest it rivals the best proprietary enterprise AI models, but its real‑world behavior outside canned tests remains to be proven. The surrounding ecosystem—tooling, monitoring, fine‑tuning pipelines, governance features, and enterprise support contracts—is nascent compared with OpenAI’s deeply integrated GPT‑5.5 stack. GPT‑5.5 not only leads many capability rankings, it also plugs into mature APIs, managed hosting, safety layers, and partner platforms. Yet it is not flawless: on BullshitBench, GPT‑5.5 and GPT‑5.5 Pro only push back on nonsensical queries around 45% and 35% of the time respectively, and “more thinking compute” can even mean more confidently rationalized nonsense. DeepSeek must show that its own reasoning‑focused modes avoid similar pitfalls while meeting enterprise requirements for stability, observability, and compliance before it can fully capitalize on its pricing advantage.
How the AI Cost War Reshapes Choices for Builders
DeepSeek V4’s entry highlights a broader split emerging in the LLM market: ultra‑cheap, high‑efficiency open models versus tightly integrated, premium GPT‑class systems. For builders, a DeepSeek‑style budget model is attractive when workloads are token‑heavy—think large‑context analysis, bulk code tasks, or fleets of lightweight agents—and when teams value on‑prem or self‑hosted control. The open‑weight nature of V4‑Pro and V4‑Flash also enables custom fine‑tuning and edge deployment strategies that closed models cannot match. Conversely, GPT‑5.5 remains compelling when organizations prioritize ecosystem depth, turnkey reliability, and tight integration with existing tools and platforms, even at a higher per‑token price. The likely result is not a single winner but a more stratified landscape: incumbents pressured into more granular pricing, specialized tiers, and on‑prem offerings, while challengers like DeepSeek race to prove that radically lower AI inference costs can coexist with dependable, enterprise‑grade performance.
