
What GitHub Copilot’s Token-Based Billing Change Really Means
GitHub Copilot’s token-based billing is a pricing model where developers pay for the exact volume of AI-generated tokens consumed, tying GitHub Copilot pricing directly to input prompts, model responses, and cached data instead of a fixed subscription or per-request limits. Under the old system, users paid flat monthly fees with request quotas, and GitHub absorbed much of the rising inference cost behind heavy usage. Now Copilot plans include monthly AI credits valued in cents, and each interaction draws down that balance according to the chosen model’s per-token charges. This reshapes AI usage costs: long chats, large context windows, and powerful models burn through credit pools much faster than short completions in lightweight models. As a result, developers who treated Copilot as an always-on assistant are seeing how many tokens their habits consume and how quickly those tokens can translate into real bills.

From Flat Subscriptions to Metered Tokens: How Pricing Works Now
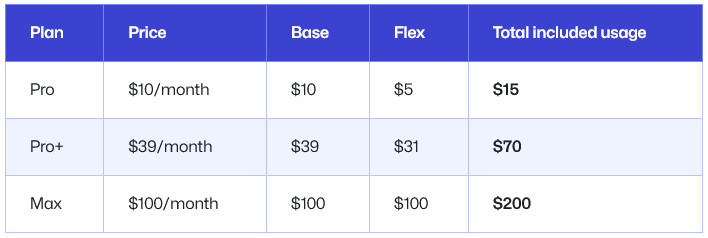
GitHub has retired premium request units and replaced them with GitHub AI Credits tied to token usage across models. Each credit corresponds to one cent of AI consumption, and plan prices themselves remain the same. Pro users paying USD 10 (approx. RM46) receive USD 15 (approx. RM69) in credits, while Pro+ users at USD 39 (approx. RM179) receive USD 70 (approx. RM321) in credits. The new Copilot Max tier costs USD 100 (approx. RM460) and includes USD 200 (approx. RM920) in monthly credits, aimed at sustained, high-volume work. One quotable detail from TechSpot is that “the $10-per-month Pro tier includes 1,500 credits, or $15 worth of AI usage.” Credits are consumed by tokens across inputs, outputs, and cached data, with different models priced differently. Smaller OpenAI models can generate one million output tokens for around USD 1.25 (approx. RM6), while the same volume on a frontier model can cost about USD 30 (approx. RM138).
Developers Report 10x Bills as Credits Vanish in a Day
The switch to metered, token-based billing is causing visible sticker shock. Ars Technica and PCMag describe users seeing billing estimates rise 10x or more compared with previous flat subscriptions. Some developers say they burned over half their monthly credits on the first day, while others exhausted a full month’s allocation in less than half a workday. One PCMag-cited user who previously spent USD 39 (approx. RM179) per month now faces an estimated bill near USD 1,800 (approx. RM8,280) under the new system. TechSpot notes that long agentic sessions, large context windows, and use of the most expensive models are the fastest paths to draining credits. Another quotable detail from GitHub is that it had been “absorbing much of the escalating inference costs” before, but that cross-subsidy is now over. For many, this first month is the moment when AI usage costs become uncomfortably transparent.

New Max Plan, Flex Allotments, and Enterprise Budget Control
To smooth the transition, GitHub introduced a layered structure of base and flex credits. Every paid individual plan includes base credits equal to the subscription price, plus a flex allotment that GitHub can adjust as AI infrastructure costs change. Joe Binder from Microsoft explains that “the flex allotment is a variable part of your included usage; it is designed to adapt as the economics of AI evolve.” Pro includes USD 10 (approx. RM46) in base credits and USD 5 (approx. RM23) in flex; Pro+ includes USD 39 (approx. RM179) base and USD 31 (approx. RM142) flex. Copilot Max doubles that pattern to USD 100 (approx. RM460) base plus USD 100 (approx. RM460) flex, for heavy users who want fewer interruptions. Business and enterprise tiers keep per-seat prices but tie credits exactly to those prices, with temporary promotional boosts and no flex component, giving organizations clearer budget ceilings over AI usage costs.
Strategies to Manage AI Usage Costs and Reduce Token Burn
Developers are already adjusting their workflows to keep AI usage costs under control. Some are experimenting with alternative tools and cheaper models, including options like Deepseek, while others consciously limit Copilot to focused tasks rather than open-ended chats. Coinbase CEO Brian Armstrong describes a model-routing strategy: prompts are sent to cheaper models by default, reserving frontier systems for only the most demanding “IQ maxing” work. He predicts that most workloads will shift to models that are dramatically cheaper on a per-token basis. In practice, developers can adopt similar tactics: shorter prompts, tighter scopes, and reduced context windows all cut token usage. Teams on GitHub Business or Enterprise can also use credit allocations as guardrails, monitoring dashboards for sudden spikes. As metered billing becomes the norm, “intelligence allocation” — deciding which tasks deserve expensive models — is becoming as important as writing the prompt itself.





