Why Storage Design Matters More Than the Database Logo
Time-series workloads look deceptively simple: each data point is just a timestamp, an identity, and one or more measurements. At scale, however, the repetition of those identities—and how you store them—dominates both storage cost and query performance. Every time-series database, whether built on PostgreSQL, a custom engine, or a columnar format, must answer the same questions: How are rows laid out? When and how is data compressed? How is data partitioned over time and series? These architectural choices determine how many bytes each row consumes, how much work queries must do, and how efficiently old data can be expired. Experiments with relational tables and columnar formats show that thoughtful layout and compression can yield large storage cost reduction and measurable query performance optimization, even before changing databases. In other words, the physical storage model often matters more than the specific time-series database brand.

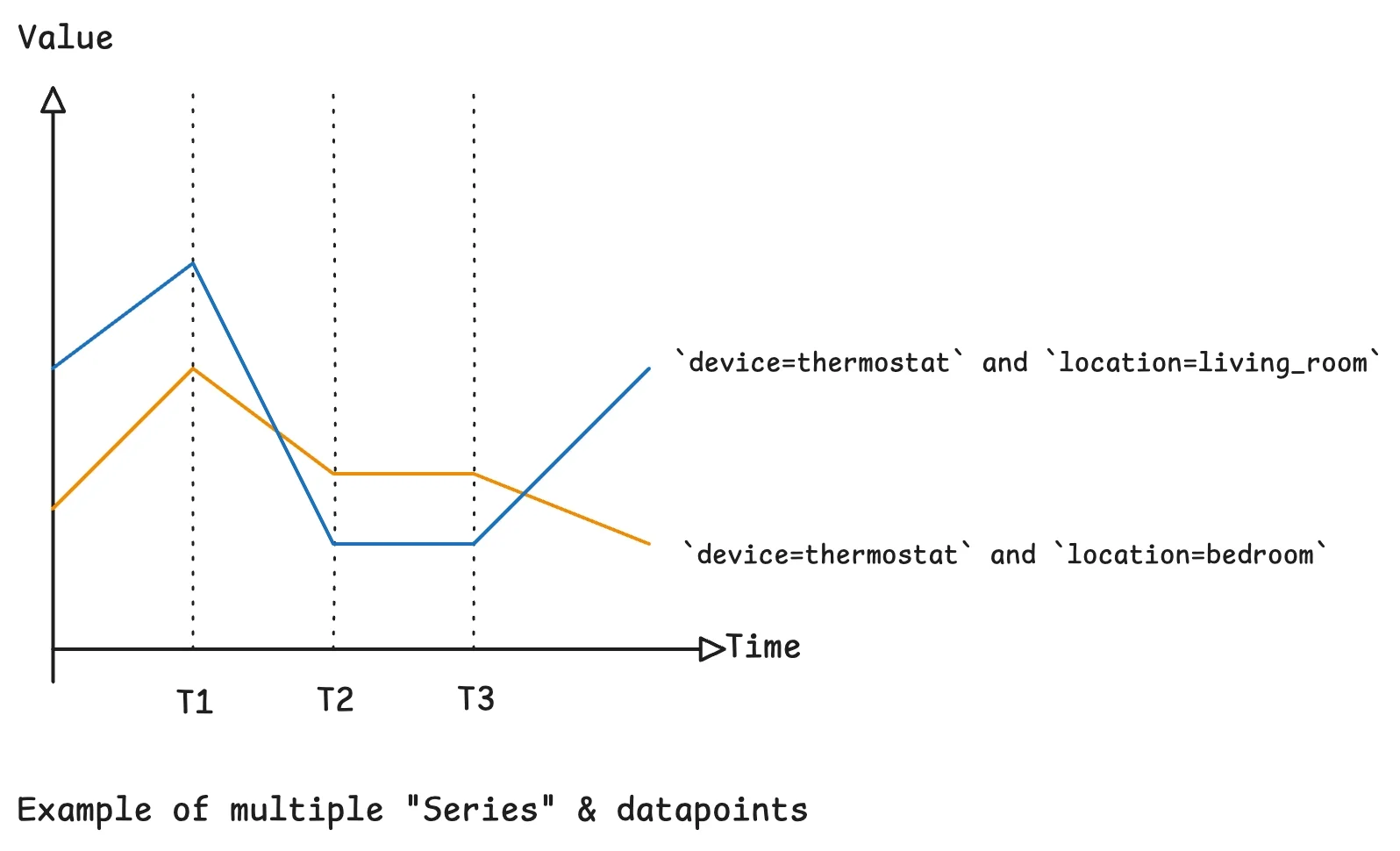
Row Layout: Flat vs. Normalized Series Identity
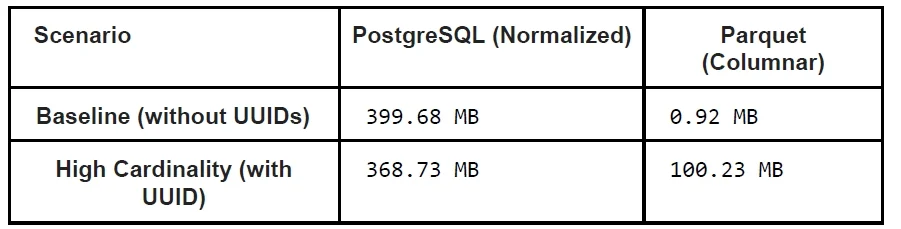
Row layout is the first lever for time-series database storage efficiency. A flat table repeats every dimension—device, location, region—on every row. This is easy to query, but wastes space and inflates indexes because text dimensions are multiplied by the total row count. A normalized design splits identity into a separate metadata table and stores a compact series_id in the main measurements table. In a PostgreSQL experiment with one thousand series and 2.8 million rows, this normalization reduced storage by about forty-two percent without hurting query latency. Warm-cache range reads performed equivalently, while hourly aggregates were faster on the normalized layout because smaller rows improved scan efficiency. The catch is cardinality: normalization shines when many rows share the same dimensions. If you include high-cardinality tags like request IDs in series identity, N_series approaches N_rows and the deduplication benefit disappears, driving up both storage and indexing overhead.

Designing Series Identity and Tags for Query Performance
Choosing what belongs in series identity versus metrics directly affects query performance optimization and storage behavior. Dimensions—or tags—are the attributes you filter and group by, such as device_id or location. Metrics are the values you aggregate, like temperature or CPU usage. Stable identifiers belong in dimensions, because they repeat across many rows and benefit from normalization. High-cardinality values such as request_id, session tokens, hashes, or random values should generally stay out of series identity; otherwise, the number of unique series explodes, harming both write throughput and query efficiency. Some systems store dimensions as flexible JSON to avoid frequent schema migrations while tags evolve. This pattern supports agile development, but it requires disciplined indexing to avoid index sprawl and type drift. The core principle is to align identity design with real query patterns: keep frequently filtered, stable attributes in dimensions, and treat event-unique IDs as payload, not as part of the series key.
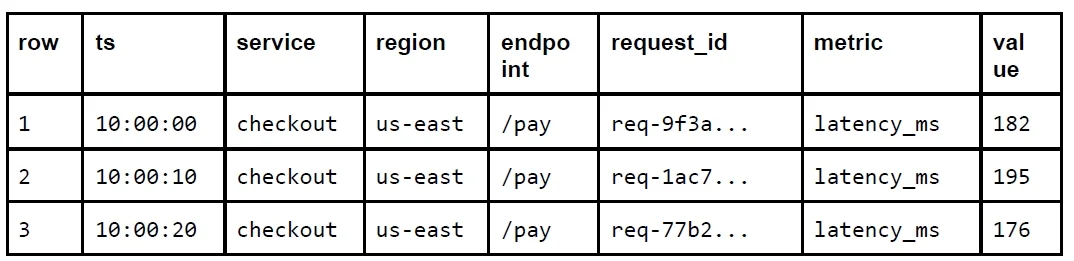
Compression Timing and Downsampling for Storage Cost Reduction
Data compression strategies and timing are just as important as row layout for storage cost reduction. Time-series workloads often write data at high frequency but read it in aggregates over longer windows. Compressing data after ingest—whether via columnar formats like Parquet or via database-native compression—reduces disk footprint and improves scan performance by shrinking I/O. Downsampling amplifies these gains. For example, reducing resolution from five-second intervals to one-hour aggregates cuts row counts by a factor of 720. You can keep full-resolution data only for recent periods where detailed troubleshooting matters, while serving historical analytics from pre-aggregated rollups. This layered approach transforms raw events into compact, query-friendly structures, minimizing both storage and CPU cost. The key is to define retention and compression policies that match how your users query data, ensuring you compress and aggregate at the point where fine-grained detail no longer adds analytical value.
Partitioning on Time and Series for Efficient Analytics
Partitioning strategy shapes how queries traverse your data. Time partitioning—splitting tables or files by time windows—enables constant-time data expiry and allows query engines to prune entire partitions based on time filters. This keeps scans focused and simplifies lifecycle management. However, time-only partitioning creates a write hotspot on the current partition as all fresh measurements hit the same logical shard. Introducing a second axis, such as series identity, distributes writes across partitions and narrows the range each query must scan. For analytics workloads, this dual-axis layout means time filters prune partitions, while series filters or series_id ranges limit work within each partition. Combined with normalized identities and columnar compression, partitioning ensures that queries touch the minimum necessary data. Ultimately, these design decisions—how you layout rows, compress data, and partition tables—drive the real-world cost and performance of your time-series database storage more than switching products ever will.