What the Minimax M3 Model Is and Why 1 Million Tokens Matter
The Minimax M3 model is a long context, multimodal AI system that can process up to 1 million tokens of mixed inputs such as long text, large codebases, and complex visual references in a single session, reducing fragmentation of context across multiple tools and prompts. MiniMax positions M3 as a frontier model that joins together a huge working memory, coding and agent capabilities, and native multimodal processing in one package. The model’s guaranteed minimum context of 512,000 tokens gives developers a clearer lower bound for planning workloads that include extensive documents or chained tasks. With this long context window, M3 can keep far larger blocks of text or code in view than typical chatbots, which is key for tasks like scanning entire repositories, long reports, or deeply threaded conversations without cutting them into smaller, error-prone chunks.
Multimodal AI Models: Text, Images and Video in a Single Workflow
Minimax M3 is part of a new wave of multimodal AI models that treat text, images and video as first-class inputs in one coherent workflow. According to WinBuzzer, M3 supports text, image and video input with text output, all exposed through OpenAI-compatible endpoints. That means a single prompt can combine source files, screenshots, diagrams and other visual assets, allowing teams to keep more of a project inside one model rather than juggling multiple tools. For developers and analysts, this multimodal setup is especially useful when code comments, architecture diagrams and UI screenshots all influence a decision. Instead of manually summarizing visuals into text, users can pass raw artifacts into the Minimax M3 model and ask for explanations, code changes or test plans that respect every modality present in the original data.
Rethinking Retrieval: How Long Context Changes Enterprise Architectures
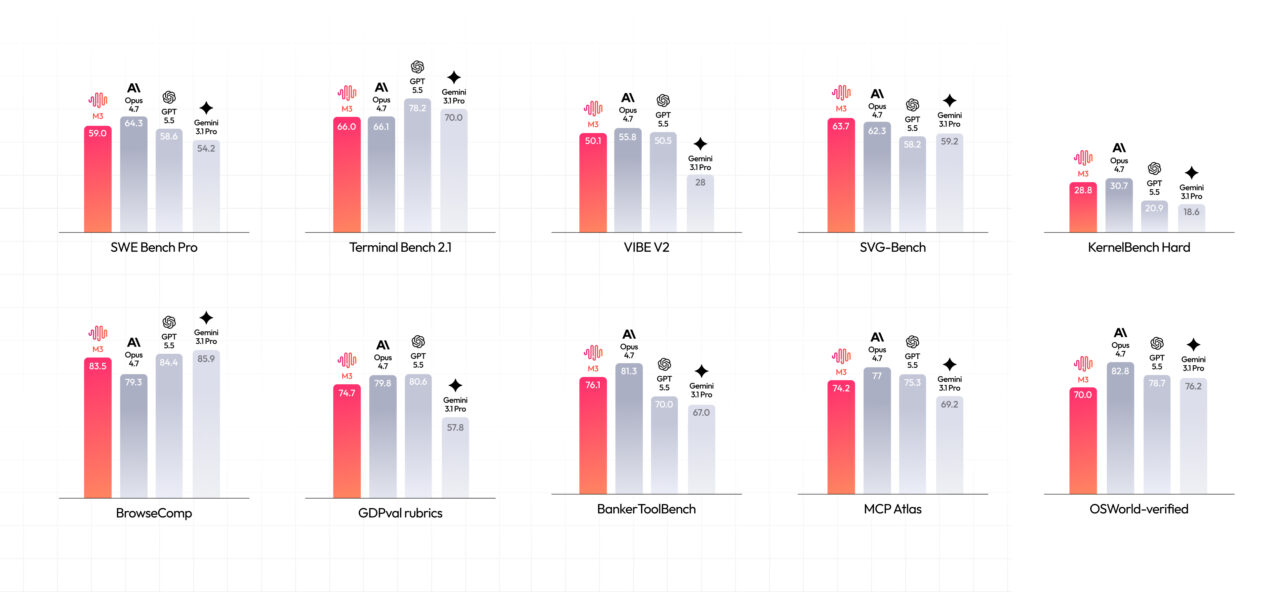
A 1 million-token long context window has architectural implications for how enterprises build AI systems. Today, many applications depend on retrieval-augmented generation (RAG), which fetches small chunks of documents into the prompt. With M3’s extended context, a complete policy manual, full contract history or entire product spec set can sit in one prompt, cutting down on brittle retrieval pipelines. MiniMax claims M3 uses Grouped-Query Attention with MiniMax Sparse Attention to cut prefill costs, and that at million-token scale it achieves 15.6x faster decoding and 9.7x faster prefill versus M2. While independent accuracy benchmarks beyond SWE-bench Pro and Terminal-Bench 2.1 are still limited, the direction is clear: more work can be done “in-context” instead of being split between search systems, heuristic chunking strategies and external vector databases, especially for knowledge-dense, document-heavy use cases.
Speed, Benchmarks and the Trade-offs Behind M3’s Design
Minimax frames M3 as a performance upgrade across both context length and runtime speed. The model uses a Grouped-Query Attention backbone combined with MiniMax Sparse Attention, a design aimed at lowering the cost of ingesting very large prompts before responding. At the coding level, Minimax reports that M3 scores 59.0 on SWE-bench Pro and 66.0 percent on Terminal-Bench 2.1, suggesting it is built with real developer workflows in mind. However, independent accuracy data beyond these numbers has not yet been deeply reported, and MiniMax’s own materials note that outside testing is still needed to show how much of the launch-day promise carries into production use. The company has stated that M3’s weights will be released within ten days of launch, which should allow teams to run their own tests and compare latency, quality and cost against incumbent models.
Competitive Positioning Against Claude and GPT in the Long-Context Race
M3 enters a market where Anthropic already offers a 1M-token context window for Claude Opus and Sonnet, and where OpenAI and others promote long-context models tied closely to their cloud ecosystems. Minimax’s earlier 4M-token experiments and the M2.5 release prepared the ground, but M3 tightens the focus on working coders and agents through a shorter product cycle and live API at launch. For enterprises, the key difference is how M3’s long context window and multimodal inputs stack against established players in real workloads: code refactoring across large repositories, multi-quarter conversation histories with customers or analysis of long-form multimedia reports. Because M3 exposes OpenAI-compatible endpoints and is designed as part of a broader long-context AI package, it can slot into existing tooling with relatively low friction, provided its latency, accuracy and price meet expectations once independent tests are available.





