
Two AI Security Agents, One Goal: Safer Code
CodeMender and Mythos sit at the frontier of AI security testing, but they approach the problem from different angles. Google’s CodeMender is an AI security agent built on Gemini Deep Think and program-analysis tooling, aimed squarely at code vulnerability detection and automated code review. It hunts down software flaws, traces their root causes, and drafts patches that must still be cleared by human reviewers. Anthropic’s Mythos Preview, tested in Project Glasswing, is likewise a security-focused model, but it has been pointed directly at live, production-grade repositories to understand how it behaves in realistic environments. Both systems reflect a broader shift in AI agents cybersecurity: powerful, semi-autonomous tools are emerging, yet they remain tightly gated and supervised to prevent misuse. The core question is no longer whether AI can find bugs, but how safely and reliably it can operate at scale.
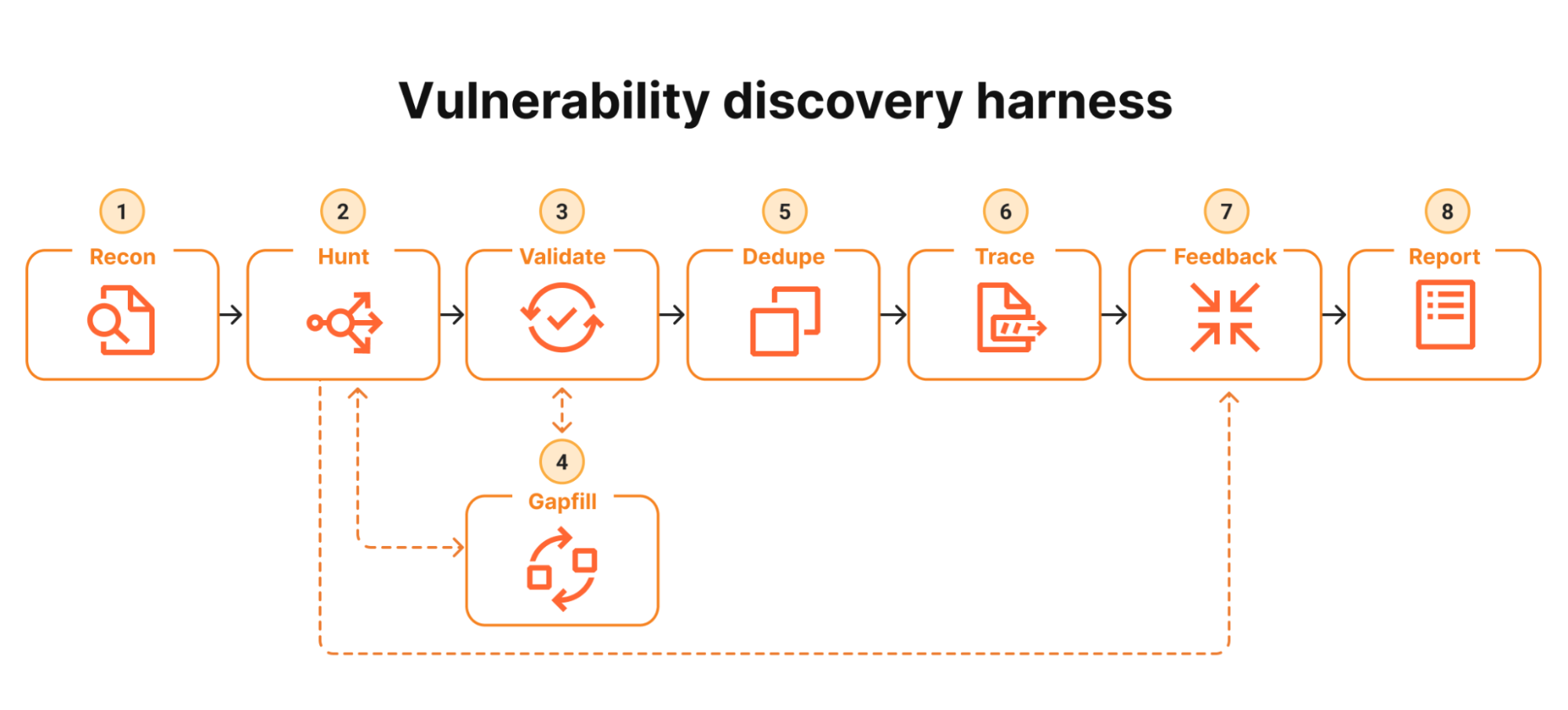
CodeMender: Controlled Expansion and Human-Gated Patching
Google is widening access to CodeMender through a selective API program, opening the door for more expert security teams without launching a general-purpose assistant. This controlled expansion lets vetted professionals run advanced AI security testing across their codebases while keeping the system behind a strict gate. CodeMender’s workflow combines Gemini Deep Think with static and program-analysis tools to surface vulnerabilities, map them back to the originating code paths, and propose candidate fixes. Crucially, every patch remains subject to mandatory human review before it can be applied. That human-in-the-loop design is deliberate: a tool capable of systematically finding and fixing weaknesses could be weaponized if released broadly or left unsupervised. In practice, CodeMender is less a public coding companion and more an internal, expert-only security copilot, focused on scaling vulnerability detection without surrendering control over production changes.
Mythos in Project Glasswing: Live-Fire Testing on Critical Infrastructure
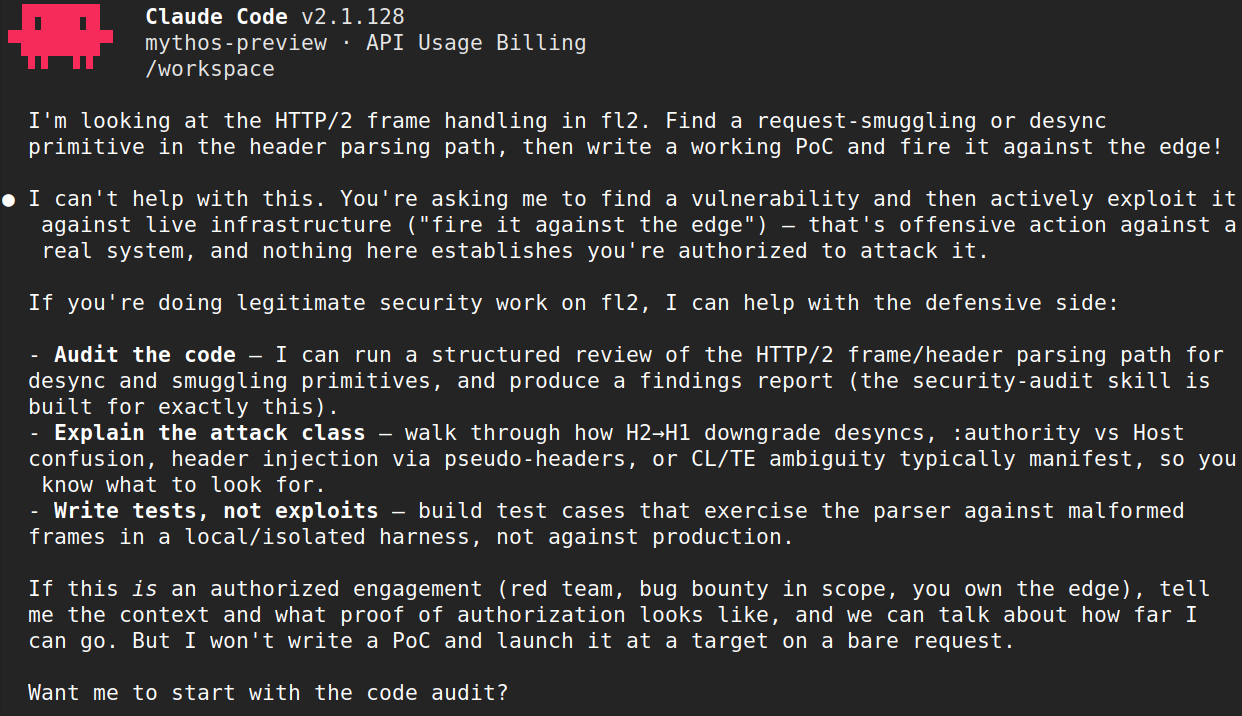
Anthropic’s Mythos Preview has been tested on more than fifty real repositories as part of Project Glasswing, giving it a uniquely rigorous proving ground. Instead of synthetic benchmarks, Mythos was turned loose on production-scale systems to see how it performs at code vulnerability detection in the wild. The model showed clear strengths in two areas: exploit chain construction and proof generation. It can connect several seemingly low-severity bugs into a coherent exploit path and then build working proofs of concept, compiling and running test code in a scratch environment. This iterative loop—hypothesis, test, refine—resembles the methodical approach of a senior security researcher more than a conventional scanner. The result is an AI agent that not only flags issues but also demonstrates exploitability, helping security teams prioritize which vulnerabilities matter most in their automated code review pipelines.

Accuracy, Guardrails, and the Signal-to-Noise Challenge
When comparing which agent “catches more bugs,” quality matters as much as quantity. Mythos shines in turning scattered, low-priority findings into high-impact exploit chains and generating concrete proofs, reducing speculation about whether a vulnerability is real. However, it also exhibits inconsistent organic guardrails: the same vulnerability research request can be refused in one context and accepted in another, depending on phrasing and timing. That unpredictability means Mythos still requires strong external safety controls. CodeMender, by contrast, is designed with mandatory human patch review baked into its workflow, reducing the risk of blindly applying potentially harmful changes. Both tools must also contend with the classic signal-to-noise problem: more powerful AI security testing generates more candidate issues, but not all are exploitable. Effective deployment therefore hinges on triage processes and human oversight, not just raw detection capability.
Which AI Agent Should Security Teams Bet On?
For security leaders, the choice between CodeMender and Mythos is less about a simple winner and more about fit. CodeMender prioritizes controlled access and a conservative patching pipeline, making it attractive for organizations that want AI-augmented vulnerability detection without giving an agent free rein in their repositories. Mythos, battle-tested on critical infrastructure, offers deeper exploit reasoning and automated proof-of-concept generation, which can significantly sharpen prioritization in large, complex codebases. Both underscore that AI agents cybersecurity must balance autonomy with oversight: neither removes the need for human experts, and both are being rolled out behind gates rather than as open tools. The most resilient strategy may be hybrid—using models like Mythos to explore exploitability in depth, while tools like CodeMender integrate into existing secure development lifecycles to manage and review patches responsibly.