
What DeepSeek V4 Actually Is: Ambitious Design, Mixed Early Reality
DeepSeek’s new V4 and V4 Pro models arrive with loud claims and even louder expectations. The Chinese AI model family is built as a Mixture-of-Experts system: DeepSeek-V4-Pro has 1.6 trillion total parameters but activates only 49 billion per token, while V4-Flash uses 284 billion total parameters with 13 billion active. Both are trained on more than 30 trillion tokens and, crucially, promise a native one-million-token context window, targeting use cases like book-scale research or massive codebases. Yet Bloomberg-linked reporting suggests the latest release still falls short of matching the best US frontier models, leaving the performance gap between Chinese and American labs intact. That contrast – striking engineering and cost-saving tricks, but underwhelming benchmarks – is why many observers now see V4 less as a GPT 4 alternative and more as a serious value play in an intensifying AI price war rather than a clean technical breakthrough.
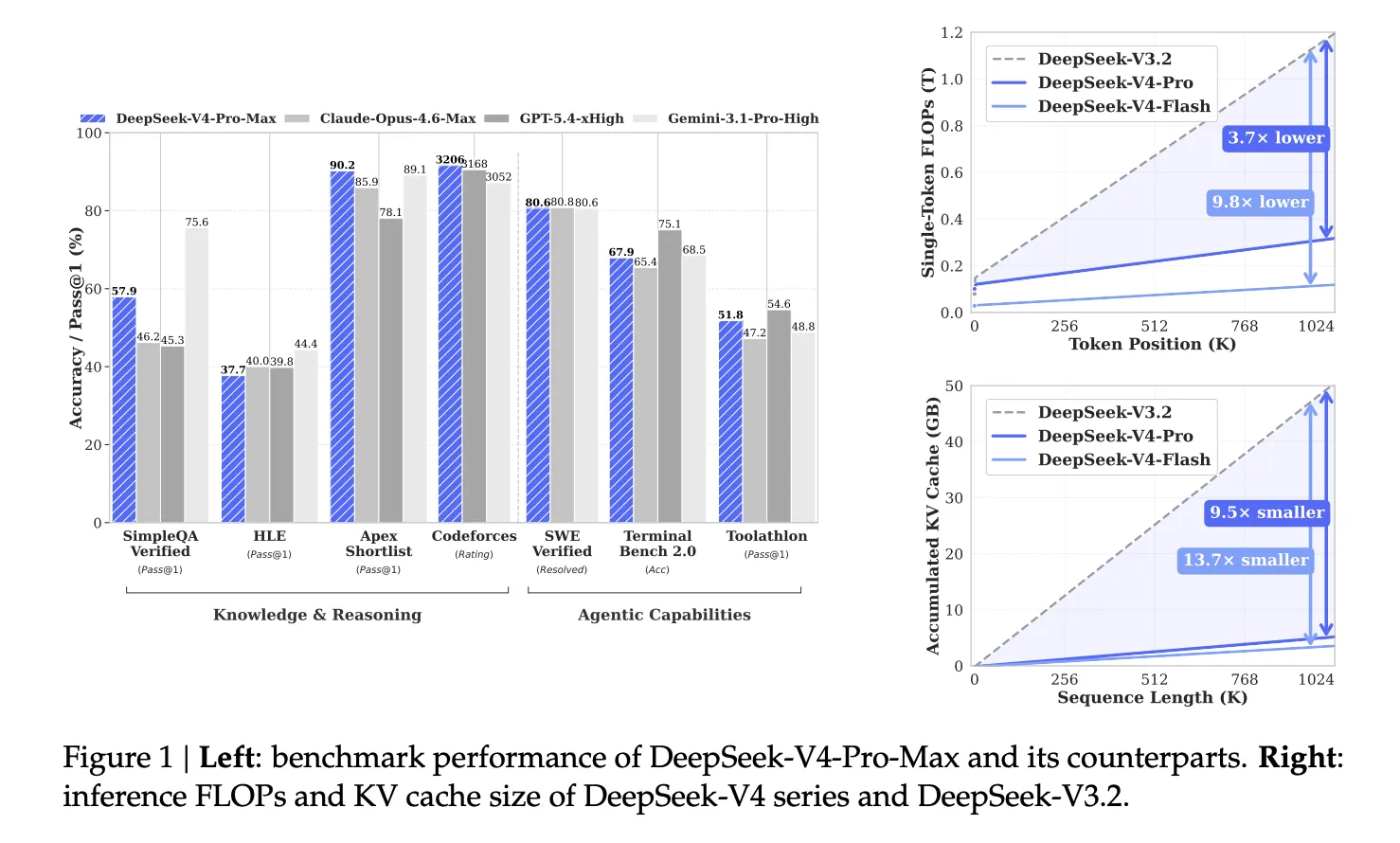
Compressed Sparse Attention, Heavily Compressed Attention and the Million-Token Context
Supporting a million token context is not a simple scaling exercise. Standard Transformer attention grows quadratically with sequence length, becoming computationally impossible at this scale. DeepSeek V4 tackles this with a hybrid attention architecture combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). CSA compresses key–value caches for every block of tokens, then uses a learned Lightning Indexer and sparse attention to focus only on the most relevant compressed entries, while still maintaining a sliding window for recent context. HCA goes further, aggressively consolidating much larger token blocks into single entries and applying dense attention over these ultra-compressed representations. The result, according to DeepSeek’s own technical notes, is a dramatic reduction in FLOPs and KV cache compared with its previous V3.2 models, making million token context feasible at inference time and positioning V4 as a specialised tool for long-context research and knowledge-heavy workflows.

Open Source, Half-Price Tokens and the Emerging AI Price War
Where DeepSeek V4 clearly disrupts is on cost and openness. V4 Pro is priced at USD 1.74 (approx. RM8.10) per million input tokens and USD 3.48 (approx. RM16.20) per million output tokens, roughly half what comparable closed models from US labs reportedly charge. V4 Flash pushes this further, at USD 0.14 (approx. RM0.65) per million input tokens and USD 0.28 (approx. RM1.30) per million output tokens, making it one of the cheapest options in its performance tier. At the same time, DeepSeek has open-sourced the architecture and checkpoints on platforms like Hugging Face. For startups and developers, this combination means they can self-host, fine-tune and audit the models, reducing vendor lock-in while leveraging a million token context. Even if V4 is a step behind top GPT 4 alternatives on raw benchmarks, its pricing and open ecosystem make it a potent weapon in the global AI price war.

IP Theft Accusations and the Shadow of US–China Tech Tensions
DeepSeek’s technical story is entangled with geopolitics. A recent US State Department cable instructed diplomats globally to warn partners about alleged efforts by Chinese firms, including DeepSeek, to steal intellectual property from US AI labs through techniques such as model distillation. The White House echoed these concerns, while OpenAI reportedly warned US lawmakers that DeepSeek was targeting leading American AI models. China’s government and the Chinese Embassy in Washington have rejected the accusations as baseless and politically motivated. These claims emerge against a backdrop of US export controls on advanced chips aimed at slowing Chinese AI progress, and after DeepSeek’s earlier R1 model already rattled policymakers by appearing to do more with less hardware. For international users, including in Southeast Asia, such allegations may influence trust, regulatory scrutiny and even long-term access to DeepSeek-powered cloud services or Huawei-based on-premise deployments.
Who Should Use DeepSeek V4 Now – and What It Means for Malaysia and the Region
Despite disappointing top-line benchmarks, DeepSeek V4 has clear niches. Long-context research, legal discovery, compliance review and analysis of large proprietary codebases can all benefit from the million token context, especially when absolute state-of-the-art quality is less critical than coverage and cost. Enterprises and startups in Malaysia and across ASEAN weighing a GPT 4 alternative must now consider not just accuracy but ecosystem, sovereignty and regulation. US models generally lead on quality and safety tooling, but DeepSeek’s open-source Chinese AI model, tied to Huawei hardware, offers attractive economics and local deployment options. For regional developers, the choice between Western and Chinese AI stacks increasingly mirrors broader trade and infrastructure decisions. In practice, many will adopt a hybrid strategy: premium US models for high-stakes tasks, and DeepSeek V4 or V4 Flash for bulk processing, experimentation and workloads where the price-performance ratio matters more than chasing the very last benchmark point.