
The Hidden Price of LLM Context Recomputation
LLM context recomputation is the repeated reprocessing of the same prompt or document by a large language model, causing each query or agent to re-run dense attention passes over identical tokens instead of reusing previously computed internal states. In enterprise AI deployments, that repeated prefill work has become the largest recurring cost, because every retrieval step, every agent hand-off, and every follow-up question can trigger another full pass over the same context. The pattern is most visible in multi-agent LLM pipelines and complex retrieval workflows. A long report is ingested once, yet dozens of specialized agents independently re-read it from scratch. Prefill cost scales with prompt length, so long-context workloads pay this tax many times over. Instead of paying for more GPUs or shorter prompts, emerging systems focus on redundant prefill elimination: saving, sharing, and restoring KV cache state so models continue from where an earlier computation stopped.
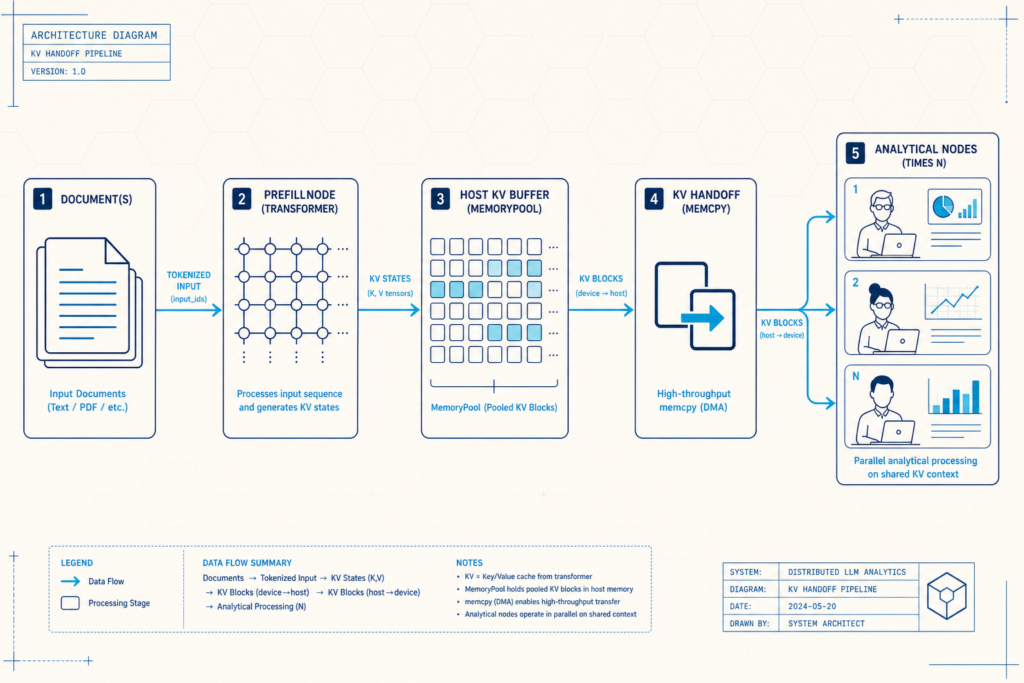
KV Snapshot Sharing: Prefill Once, Fan Out
KV cache optimization through snapshot sharing targets the core inefficiency: every agent in a pipeline rebuilding the same key/value cache. SwarmKV shows how to prefill once, serialize the KV state to a host buffer, copy it per branch, and restore it before decoding. The result is “compute once, fan out” instead of “compute N times, hope nobody notices.” According to the SwarmKV report, a two-agent analytical pipeline on a GTX 1080 became about 1.95× faster end to end, while the second agent’s activation latency dropped roughly 52×, eliminating 8,685 ms of redundant dense compute. Because redundant prefill scales quadratically with context length while KV transfer is linear, even the serialize–memcpy–restore round trip is cheaper than recalculating attention from scratch. For multi-agent LLM pipelines over shared documents, this kind of KV snapshot reuse turns the GPU into a broadcaster of shared state rather than a stateless worker.
Memory Engines Like Taliesin: Stop Re-Reading the Same Document
Where KV snapshot sharing focuses on branching inside a single run, memory engines like Taliesin tackle LLM context recomputation across sessions and hardware. Taliesin saves the AI’s internal memory for a long context on one server and restores it byte-identical on another, even across GPU generations. That means a model does not have to re-read a document every time a user asks a new question about it. Corbenic AI describes Taliesin as eliminating redundant recomputation of already processed context, restoring state so precisely that 64 of 64 output tokens matched across an Ampere A6000 and an Ada Lovelace RTX 4090. In one benchmark on a $0.69-per-hour graphics card, contexts that took more than two minutes to process from scratch were restored in under seven seconds, a 21× speedup with no loss of accuracy. Cryptographic SHA-256 hashes make these bit-identical restores independently verifiable.

Why These Optimizations Matter for Enterprise AI Costs
Enterprise AI costs are increasingly dominated by repeated prefills over long contexts rather than by decode steps. In retrieval-heavy workflows and multi-agent LLM pipelines, each analytical branch can have a full-context prefill, multiplying GPU time with no quality gain. KV cache optimization and memory engines attack this pattern directly by preventing models from reprocessing already-computed context. The performance gains are tangible: SwarmKV’s two-agent test saw about a 48.69% end-to-end speedup, while Taliesin reported up to 21× faster long-context restoration. These improvements arrive without retraining models, changing prompts, or sacrificing accuracy, because restored state is mathematically equivalent to a fresh read. For teams building multi-agent systems or dense retrieval graphs, the promise is straightforward: cut redundant prefill, keep answers identical, and reclaim 2–3× throughput that would otherwise go into re-reading the same documents over and over again.






