
Security LLMs Move From Experiment to Frontline Defense
Security-focused large language models are rapidly transitioning from research novelties to frontline tools for AI vulnerability detection. Anthropic’s Claude Mythos Preview, deployed through Project Glasswing with around 50 vetted partners, has already surfaced more than 10,000 high- or critical-severity vulnerability candidates across widely used software. Early triage shows 1,726 of these as confirmed true positives, with 1,094 assessed as high or critical severity and nearly 100 already patched upstream. One notable case is a critical WolfSSL flaw (CVE-2026-5194, CVSS 9.1) enabling certificate forgery. In parallel, Google’s CodeMender, powered by Gemini Deep Think and program-analysis tooling, is being opened to a broader circle of expert testers via API while remaining tightly gated. Together, these efforts signal a structural shift: security LLM testing is no longer an edge experiment but an emerging pillar of code vulnerability scanning for systemically important infrastructure software.

Inside Project Glasswing: Mythos as a New Kind of Security Engine
Project Glasswing’s early results show why specialized agents like Mythos differ from traditional scanners and general-purpose models. When Cloudflare pointed Mythos Preview at over fifty internal repositories, the model didn’t just flag suspicious code; it built exploit chains that combined seemingly low-severity issues into credible, end-to-end attacks. It can autonomously craft proof-of-concept code, compile and execute it in a sandbox, and iteratively refine its hypotheses until it demonstrates a real exploit. This loop collapses the gap between speculative vulnerability candidates and demonstrated impact, revealing how many backlog “nuisance” bugs can compose into high-impact chains. Other frontier models could often spot similar primitives but typically stalled before stitching them into working exploits. The implication is clear: code vulnerability scanning is evolving from static pattern matching into dynamic, research-style reasoning capable of approximating the work of senior security engineers at scale.

Emergent Guardrails and the Limits of Fully Autonomous Analysis
Glasswing also highlights the current limits of AI vulnerability detection, especially around safety and consistency. The Mythos Preview model, which lacks the heavier safeguards of widely released assistants, still showed emergent guardrails: it sometimes refused to assist with exploit development or vulnerability research, even for legitimate defensive tasks. However, these refusals were inconsistent. The same codebase could be analyzed after a trivial environmental change, and semantically identical requests sometimes produced opposite outcomes across runs. In other cases, Mythos confirmed serious memory bugs but declined to generate demonstration exploits, only to comply when the request was rephrased. This inconsistency makes it risky to rely on organic model refusals as a comprehensive safety layer. For organizations, it underscores that security LLM testing must be embedded in a managed process, with human oversight and policy enforcement, rather than treated as a fully autonomous offensive or defensive capability.
CodeMender and the Rise of Human-in-the-Loop Patch Generation
While Mythos pushes the frontier of autonomous discovery, Google’s CodeMender illustrates how automated patch generation is being operationalized with humans firmly in the loop. Introduced as a controlled-access AI security agent, CodeMender uses Gemini Deep Think alongside static and dynamic analysis tools to locate vulnerabilities, trace root causes, and propose fixes that can be tested before deployment. Every patch still goes through human review, and Google is expanding API access only to vetted expert testers, not the general public. This reflects a broader industry consensus: powerful code security agents must remain gated, both to prevent misuse and to ensure that patch quality, compatibility, and risk trade-offs are evaluated by experienced engineers. Instead of replacing security teams, these agents are becoming force multipliers, letting humans focus on triage, validation, and strategic decisions while AI handles large-scale code vulnerability scanning and candidate fix generation.
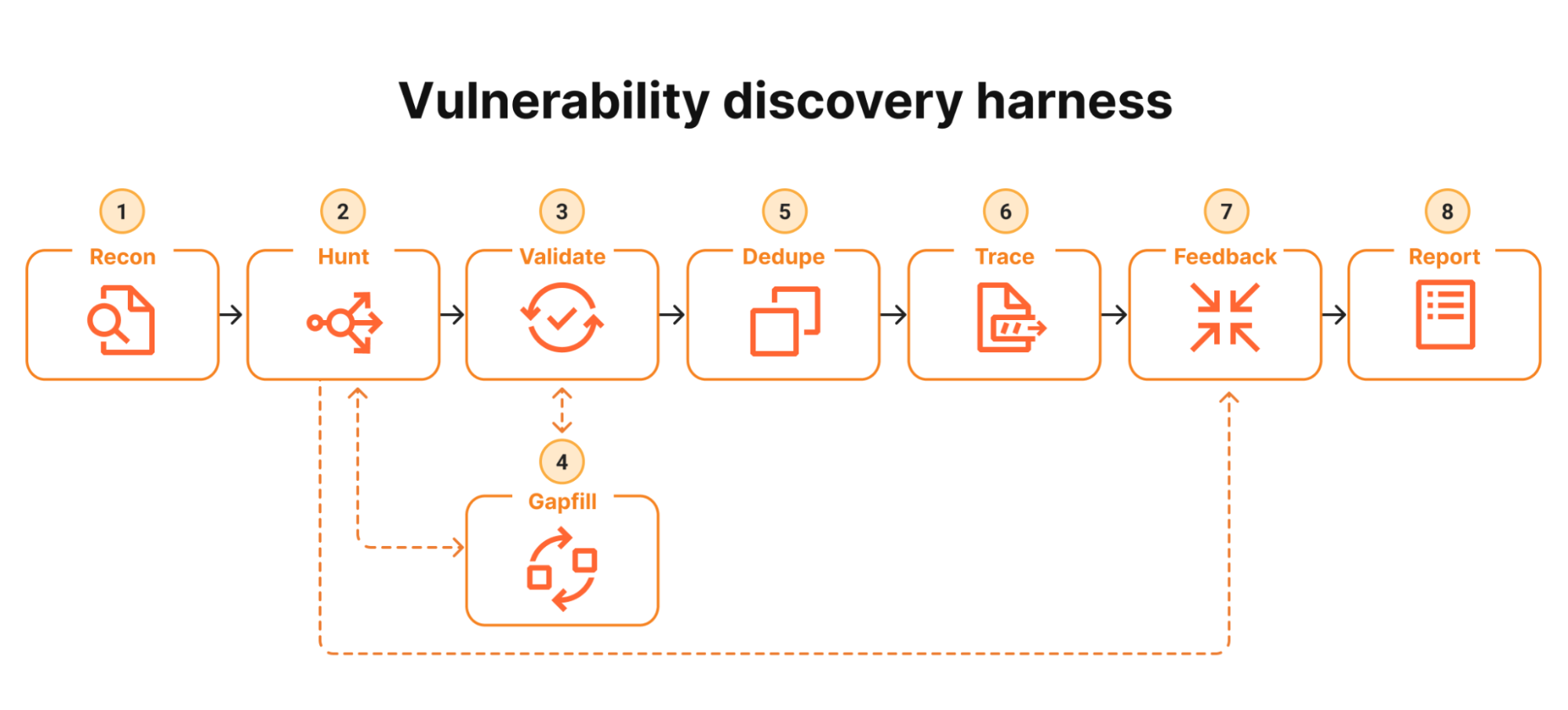
From Vulnerability Backlog to Patch Triage Crisis
The combined effect of Mythos, CodeMender, and similar tools is a dramatic acceleration in vulnerability discovery, with significant workflow consequences. Anthropic notes that finding vulnerabilities has become much easier than fixing them, a mismatch echoed by vendors reporting unprecedented patch volumes driven by AI-assisted discovery. In Glasswing, thousands of high-severity candidates quickly condensed into over a thousand serious, validated issues, prompting urgent patching and advisories for critical software components. This surge forces organizations to rethink vulnerability management: prioritization must now consider AI-generated exploit chains, not just individual CVSS scores, and remediation queues need to adapt to a constant influx of high-confidence findings. Security teams are moving toward continuous, AI-augmented assessment cycles where automated systems propose vulnerabilities and patches, but human experts arbitrate risk, coordinate disclosure, and ultimately decide what gets fixed first across sprawling production environments.