What Claude Opus 4.8’s Benchmark Win Actually Means
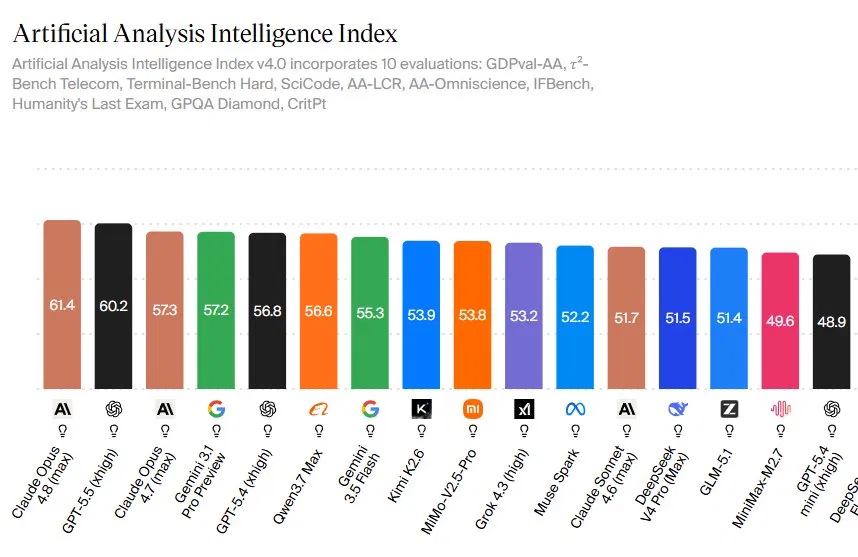
Claude Opus 4.8 is Anthropic’s latest flagship large language model that currently tops independent AI model rankings by scoring 61.4 on the Artificial Analysis Intelligence Index, a composite benchmark measuring reasoning, coding, agentic behavior, and tool use across multiple demanding tests. The Artificial Analysis Intelligence Index aggregates 10 evaluations, including GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. On this measure, Claude Opus 4.8 edges out GPT-5.5 at 60.2 and outpaces its predecessor Opus 4.7 at 57.3, making it the highest-scoring general-purpose model on this snapshot. The narrow 1.2-point lead over GPT-5.5 may look small, but it reflects consistent strength across domains, from complex science questions to full-stack coding tasks, rather than a single standout test. For organizations tracking language model comparison data, this is the new bar to beat.
Inside the Numbers: Reasoning, Coding, and Agentic Performance
Anthropic’s own evaluation data shows where Claude Opus 4.8 gains its edge. On SWE-bench Pro, a benchmark of real GitHub issues in large codebases, Opus 4.8 scores 69.2%, higher than GPT-5.5’s 58.6%. On Humanity’s Last Exam, which tests multidisciplinary reasoning, Opus 4.8 reaches 57.9% with tools, ahead of all rivals listed in the Artificial Analysis report. A standout metric is GDPval-AA, which simulates economically valuable work tasks across 44 occupations and 9 industries using web and shell access. Here, Opus 4.8 posts 1890 Elo, 121 points ahead of GPT-5.5. According to Artificial Analysis, this benchmark captures “agentic performance on real-world work tasks,” so the gap suggests stronger practical autonomy. The model also leads on agentic computer use with an 83.4% score on OSWorld-Verified, underscoring its ability to operate software environments rather than only answer questions.
How Opus 4.8 Fits Between GPT‑5.5 and Anthropic’s Mythos
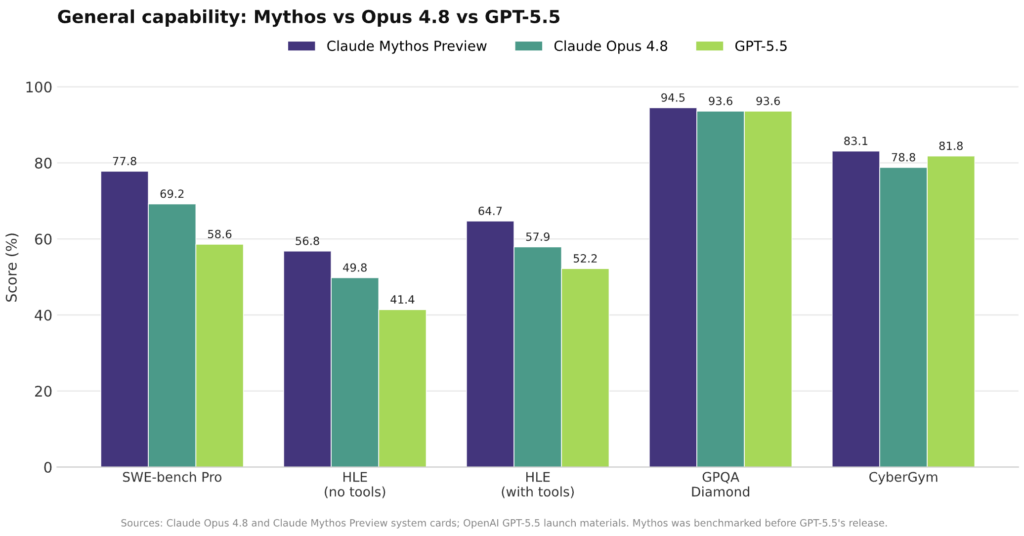
Claude Opus 4.8 does not stand alone; it sits in a growing family of high-end systems. On Anthropic’s internal AECI index, Opus 4.8 lands at 155.5, between Opus 4.7 at 154.1 and the more experimental Claude Mythos Preview at 158.3. In coding, Mythos leads on the hardest tasks, scoring 77.8 on SWE-bench Pro versus Opus 4.8’s 69.2 and GPT-5.5’s 58.6. On GPQA Diamond, a set of graduate-level science questions designed to be resistant to search, Mythos, Opus 4.8, and GPT-5.5 cluster closely, all around the mid-90s, suggesting a near-tie at the frontier of pure scientific reasoning. Cybersecurity is where the divergence becomes stark: Anthropic reports Mythos generating working exploits on 70.8% of Firefox targets with safeguards off, versus 8.8% for Opus 4.8, while public tests show GPT-5.5 performing competitively with Mythos on expert cyber tasks. For most enterprises, Opus 4.8 is the balanced, general-purpose option among these tiers.

Pricing, Efficiency, and the Trade-Offs Behind the Leaderboard
Benchmark leadership is only part of the story; cost and efficiency shape real deployments. Anthropic has kept Claude Opus 4.8 at the same base price as Opus 4.7: USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens. Opus 4.8 also introduces a Fast Mode—the same underlying model running at roughly 2.5× the speed and priced at about one-third of the standard cost, which developers can invoke in Claude Code via the /fast command. There is a trade-off: Opus 4.8 currently uses about 30% more turns per task than GPT-5.5 to achieve its superior scores. For high-volume, agentic workflows, that extra interaction cost can offset some quality gains. In other words, the new benchmark leader offers higher performance, but teams still must weigh latency, per-token cost, and interaction depth for their specific workloads.
How to Read AI Model Rankings for Your Use Case
AI model rankings like the Artificial Analysis Intelligence Index and Anthropic’s AECI are helpful signals, but they are not one-size-fits-all scores. The composite Artificial Analysis Intelligence Index highlights breadth across reasoning, coding, and agentic benchmarks, so Claude Opus 4.8’s 61.4 score indicates balanced strength. However, developers should also look at targeted tests: SWE-bench Pro for software engineering, OSWorld-Verified for computer-use agents, or GDPval-AA for real-world work tasks. For security-sensitive environments, cyber-focused evidence around Mythos and GPT-5.5 becomes more relevant than general scores. The practical approach is to treat language model comparison tables as a shortlist, then run pilot tasks that mirror your own workflows—codebases, support logs, documents, or internal tools. In that context, Opus 4.8’s benchmark win signals a strong default choice for complex, tool-using agents, but the “best” model remains the one that matches your reliability, safety, and budget constraints.





