

From Nano Banana Pro to Vision Banana: A Layout‑Aware AI Image Generator
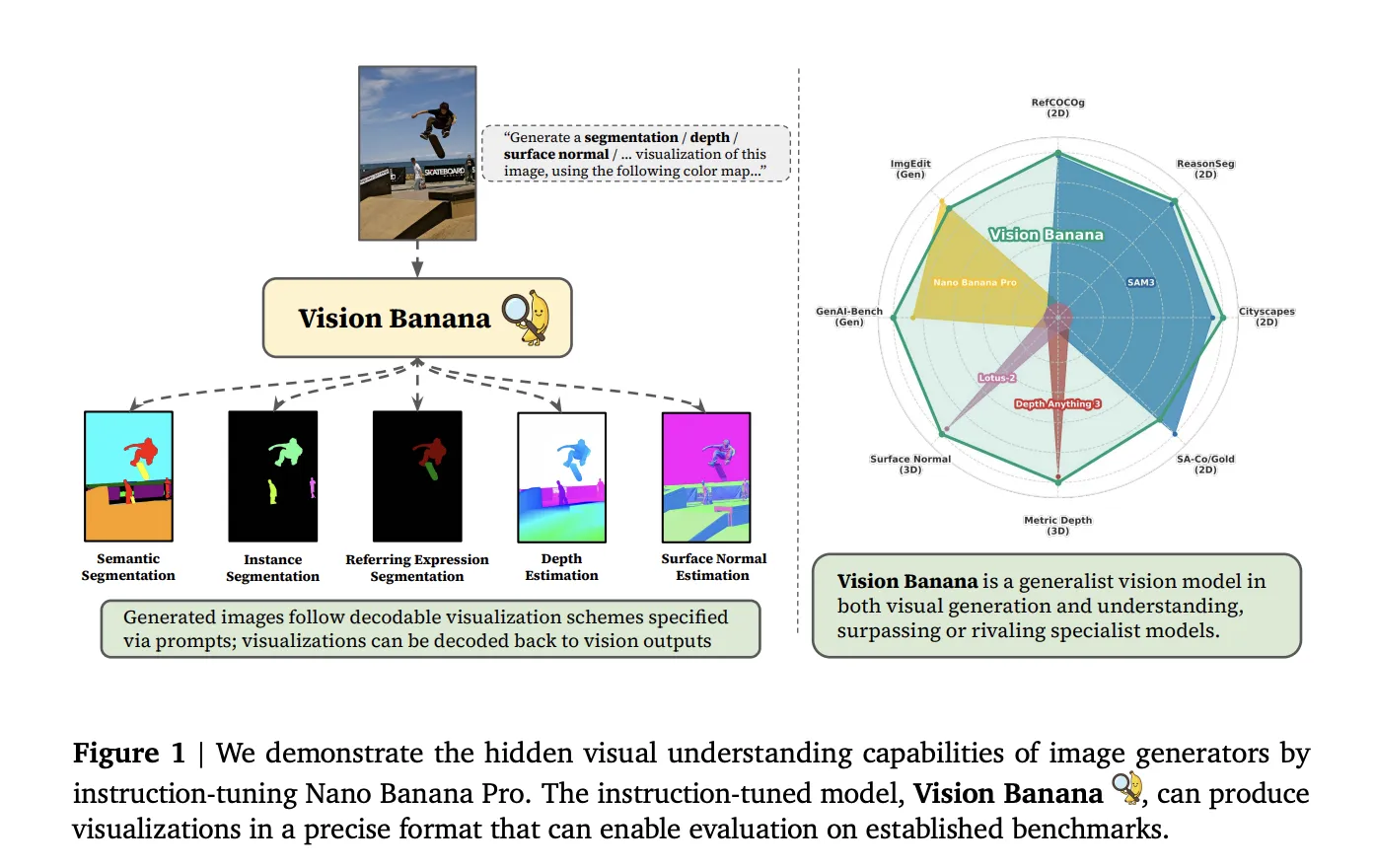
Vision Banana is Google DeepMind’s new instruction‑tuned AI image generator built on its Nano Banana Pro base model. Instead of separating “make an image” from “understand an image,” the team treats image generation as a general vision pretraining step. A light instruction‑tuning pass teaches the model to output RGB visualizations for tasks like semantic segmentation, instance segmentation, metric depth estimation and surface normals, without adding custom task‑specific heads. Benchmarks show Vision Banana surpassing or matching specialist systems such as SAM 3 for segmentation and Depth Anything V3 for metric depth estimation. For designers, this depth aware image capability matters because the model can reason about geometry, object boundaries and physical scale while still generating photorealistic content. That translates into more layout‑aware image generation: cleaner subject separation, fewer melted objects, and more believable perspective for scenes like product hero shots, interior renders and complex composites built for marketing campaigns.
Midjourney V8 Alpha and a Maturing Video Pipeline
Midjourney’s V8 Alpha, quietly released to its Discord community, is a visible jump over V7 in areas power users care about most. Tests and community feedback highlight better semantic understanding of complex multi‑subject prompts, sharper text rendering in‑image, and improved spatial coherence when multiple elements interact. Problems like element merging—where three or more objects collapse into visual noise—are reduced, making it more reliable for intricate scenes like crowded events or multi‑product layouts. Alongside V8 Alpha, Midjourney is evolving a video pipeline. The 2026 Web Editor’s Animate button uses the Video V1 model to turn single images into smooth high‑definition clips, with users reporting 21‑second outputs from static frames. A Video V2 model is already on the roadmap, aimed at longer, more consistent motion, and a new Edit model promises inpainting, outpainting and multi‑reference workflows that historically required external tools. Together, they push Midjourney V8 Alpha toward becoming a full image‑and‑video creation hub.

Why Segmentation and Depth Matter for Everyday Design Work
Better segmentation and depth prediction sound technical, but they directly impact daily AI design workflow tasks. Vision Banana’s ability to generate segmentation masks as RGB images means designers can derive clean, task‑ready masks without hand‑painting selections in Photoshop or Figma. For product mockups, that means instant separation of foreground objects from backgrounds, making it easier to swap scenes, recolor surfaces or iterate on packaging concepts. Its strong metric depth estimation—encoded as invertible depth maps—enables depth aware image editing, like consistent blur, lighting or shadow adjustments based on actual scene structure rather than rough guesses. Combined with Midjourney V8 Alpha’s improved spatial coherence, the result is more reliable composite images, AR/VR concept art with believable scale, and storyboard frames where characters and props sit naturally in the scene. Designers can spend less time masking and retouching, and more time iterating on layout, copy and overall creative direction.
New Hybrid Workflows: Layout Brain Meets Stylization and Motion Engine
These models invite a division of labor in modern AI image generators. Vision Banana‑style systems can act as a layout brain: they understand where objects are, how far away they sit, and how surfaces relate. Designers might first use such a model to generate a clean segmentation visualization and depth map for a scene—say, a social ad featuring a runner, a city backdrop and overlaid typography. Those outputs then guide Midjourney V8 Alpha as a stylization and motion engine, focusing on aesthetics, lighting and animation. For storyboards, a pipeline could start with Vision Banana generating structured frames with consistent character positioning, followed by Midjourney adding style variations or animating key moments via the Animate button. Brand moodboards could leverage depth aware image prompts (e.g., “wide shot, subject in sharp foreground, city lights softly blurred in the background”) to produce coherent, reusable assets that plug straight into existing design stacks.
Risks, Limitations and Practical Prompt Strategies for Designers
More convincing synthetic images and video inevitably raise risks. Tools that beat specialist models at segmentation and depth can also make fabricated scenes, staged events or fake product photos look more plausible, amplifying misinformation if used irresponsibly. Designers and marketers need to stay critical of sources, understand that training data can introduce bias, and recognize where certain demographics, aesthetics or environments might be under‑represented or distorted. Practically, teams can prepare by developing prompt strategies that exploit segmentation and depth awareness: explicitly requesting “clear foreground subject, separate background layers” or “consistent depth ordering of objects” when planning composites. Exported masks and depth maps can be layered into Photoshop or compositing software as standard passes, while Midjourney V8 Alpha handles final style, texture and motion. Building repeatable templates—prompt libraries, layer naming conventions, review checklists—will help integrate these models into AI design workflows without losing creative control or ethical awareness.