What Claude Opus 4.8 Is and Why It Matters
Claude Opus 4.8 is Anthropic’s newest flagship large language model that focuses on safer code generation, sharper judgment, and configurable effort controls to support enterprise-scale automation, complex reasoning, and agentic workflows across software engineering and knowledge work. Anthropic says Opus 4.8 is around four times less likely than its predecessor to let flaws in code it has written pass unremarked, which translates to an approximate 75% reduction in code defect detection failures. Benchmarks show a SWE-Bench Pro score of 69.2%, ahead of GPT-5.5 and Gemini 3.1 Pro on that task, alongside gains in multidisciplinary reasoning and agentic financial analysis. At the same time, Opus 4.8 keeps base pricing unchanged while adding a faster, cheaper Fast mode and extending effort controls beyond Claude Code into claude.ai and Cowork, positioning this release as a meaningful upgrade rather than a cosmetic update.

Cutting Code Defects and Improving Engineering Judgment
Opus 4.8’s headline engineering improvement is its drop in silent code failures. Anthropic reports the model is four times less likely than Opus 4.7 to allow flaws in code it wrote to pass without comment, making its code defect detection far more reliable for continuous integration pipelines and automated refactors. Internal evaluations show agentic coding scores improving from 64.3% to 69.2% on SWE-Bench Pro, with higher marks in multidisciplinary reasoning with tools and agentic financial analysis as well. Early users highlight judgment gains: Shopify staff engineer Tom Pritchard notes that Opus 4.8 “asks the right questions, catches its own mistakes, [and] pushes back when a plan isn’t sound,” which is critical when automating high-risk changes across microservices. Alignment assessments indicate lower deception rates and stronger support for user autonomy, aligning the model’s behavior more closely with enterprise compliance and safety requirements.
Effort Controls: Letting Users Decide How Hard Claude Thinks
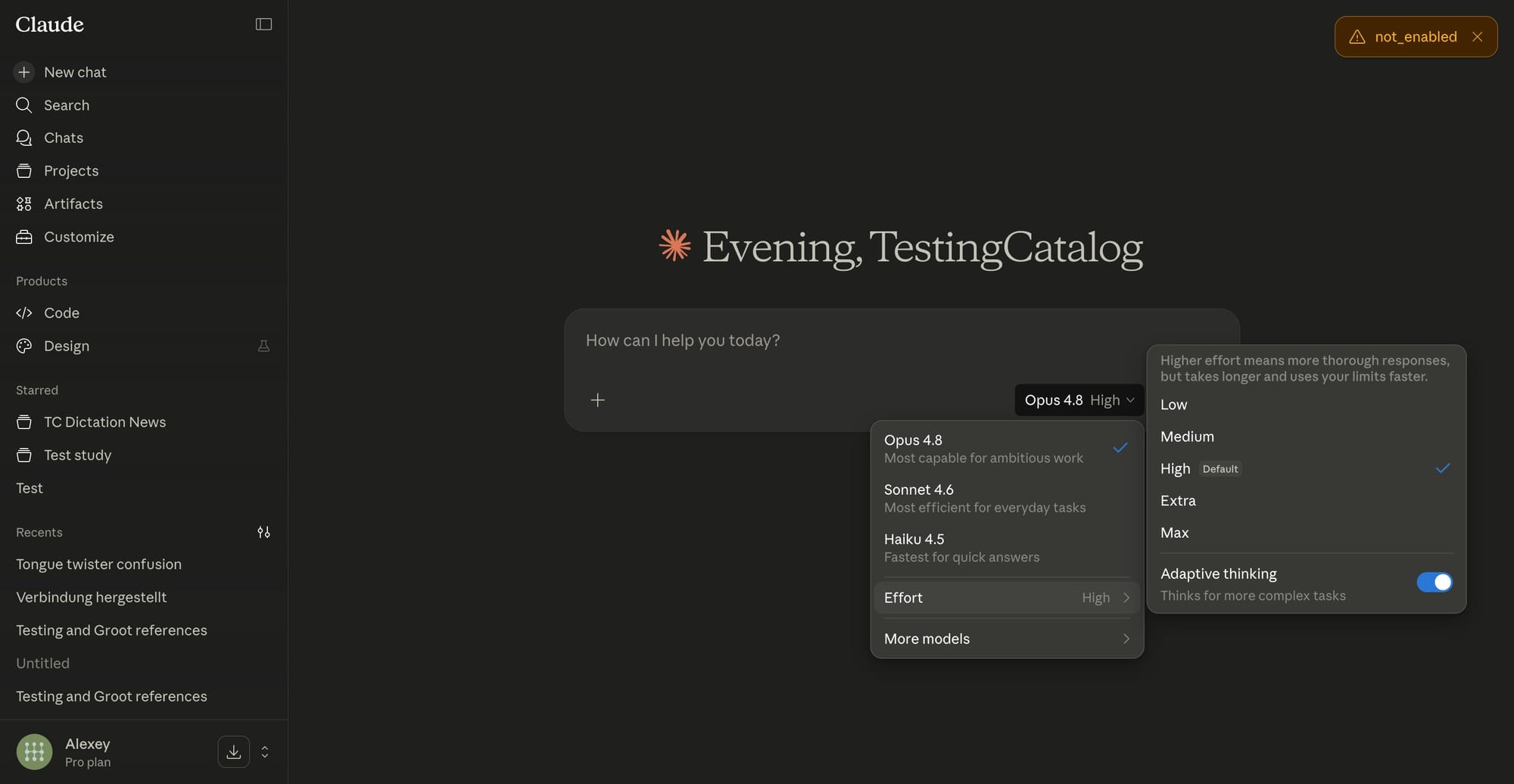
Effort controls Claude introduces in Opus 4.8 give users direct control over how much thinking the model does per query. On claude.ai and Cowork, a new selector offers five effort levels—Low, Medium, High (default), Extra, and Max—each trading off speed, depth, and token consumption. Low effort favors quick, shallow responses for tasks like simple Q&A or email drafts, while High through Max push Claude to plan more, reason in multiple steps, and re-check outputs, making them suitable for complex debugging, design reviews, or legal analysis. According to Anthropic, the default High effort spends a similar number of tokens as Opus 4.7’s default but delivers better results, improving accuracy without increasing typical usage. This shift moves a key system decision into the hands of developers and analysts, who can now calibrate response quality and latency per task instead of relying on a single global behavior.
Dynamic Workflows and Parallel Agents for Enterprise Coding Automation
Dynamic workflows agents in Opus 4.8 extend Claude Code into a coordination layer for large automation projects. In research preview for Enterprise, Team, and Max plans, the system can plan a complex job, spin up hundreds of parallel subagents in one session, and verify their work before returning results. Anthropic’s example is codebase-scale migrations across hundreds of thousands of lines, where subagents can divide files, apply transformations, run tests, then adapt their priorities as issues surface. Unlike static scripts, these dynamic workflows adjust plans mid-flight, allowing Claude to handle evolving requirements or discoveries, such as inconsistent APIs or hidden dependencies. The company has previously demonstrated parallel Claude instances autonomously building a C compiler, suggesting this orchestration is designed for sustained agentic coding rather than one-off prompts. For enterprises, this turns Opus 4.8 into a candidate backbone for automated maintenance, security remediation, and multi-repo refactors.
Speed, Cost Profile, and Competitive Positioning as a Bridge to Mythos
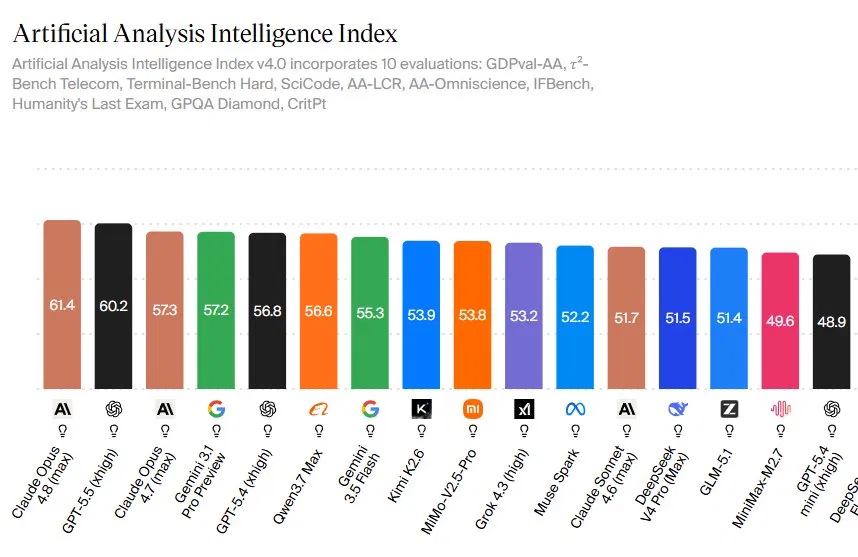
Anthropic balances these new AI coding features with pragmatic performance and pricing. Opus 4.8 keeps the same base rates as Opus 4.7 at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, while a new Fast mode runs the same model at about 2.5× the speed and at one-third the previous Fast mode cost. This helps offset the fact that Opus 4.8 tends to use roughly 30% more turns per task than GPT-5.5 in agentic workflows. On the capability side, Opus 4.8 tops the Artificial Analysis Intelligence Index with a score of 61.4, ahead of GPT-5.5’s 60.2 and Gemini 3.1 Pro Preview’s 57.2, reflecting consistent strength across ten benchmarks. Anthropic has signaled that Mythos-class models are coming soon, making Opus 4.8 a bridge release that delivers immediate enterprise value while preparing customers for a more powerful generation of dynamic AI agents.