What a Peer-Reviewed Research Assistant Is—and Why It Exists
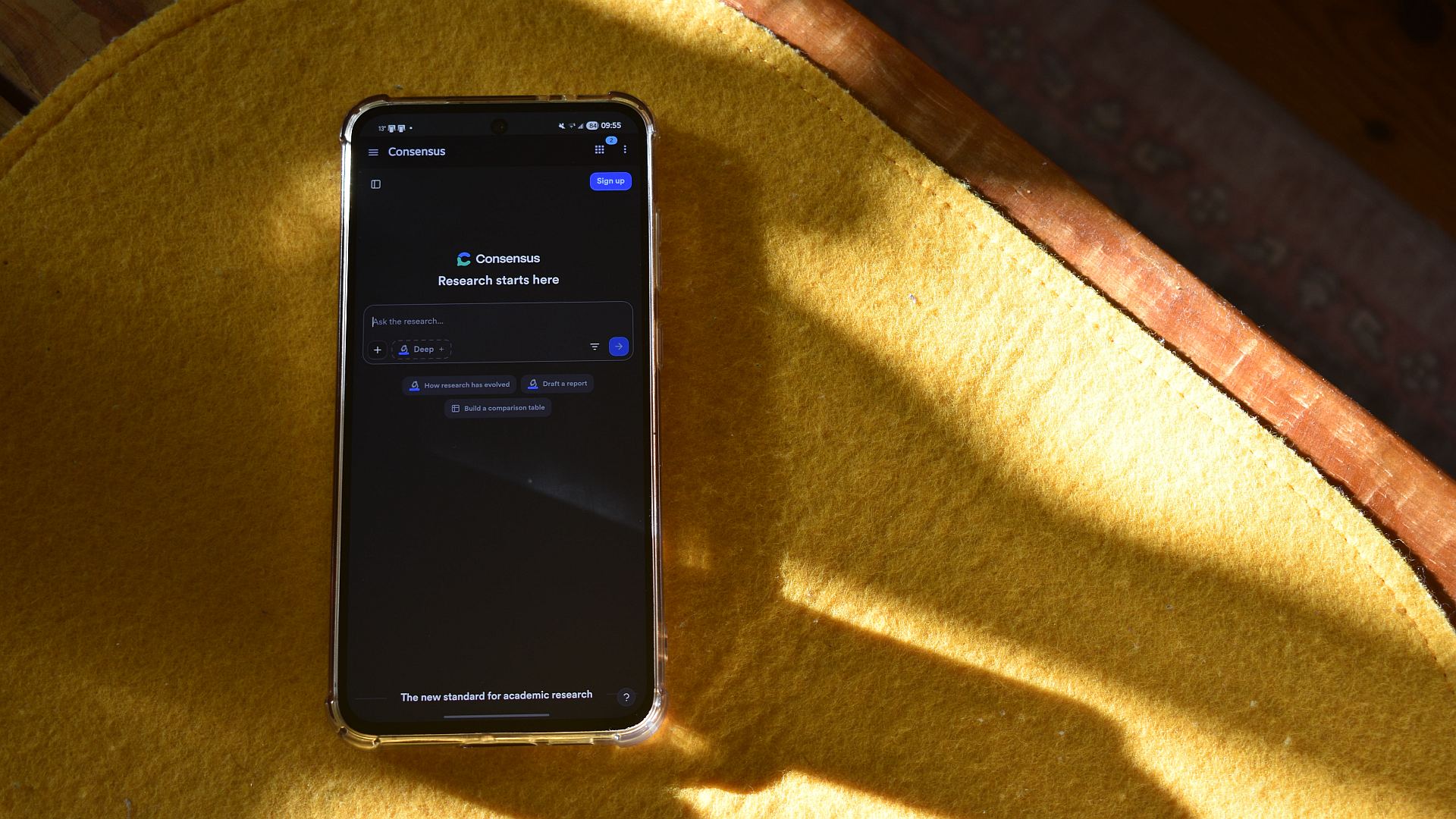
A peer-reviewed research assistant is an AI system that limits its answers to findings drawn from published, peer-reviewed scientific papers, presenting conclusions alongside clear citations so users can verify every claim. This design responds to the growing AI hallucinations problem, where popular chatbots confidently invent sources, legal cases, or strange recommendations. In a landscape where generative models are trained on enormous, mixed-quality datasets, speculative responses are a built‑in risk. By narrowing its knowledge base to vetted literature, this kind of assistant prioritizes reliability over creativity. Consensus, highlighted by Android Authority, embodies this shift by asking, in its own way, “What if Google Scholar were an AI assistant?” Instead of scraping the open web for guesses, it combs millions of scholarly papers and surfaces an evidence‑based summary that is far easier to read than the PDFs it relies on.
How Consensus Tackles the AI Hallucinations Problem
Consensus is designed around a simple rule: its fact-checked AI responses come from peer-reviewed research, not from opinion blogs, forums, or unverified web pages. According to Android Authority, one of the biggest problems facing mainstream assistants is the breadth of data they ingest, which is why a model might suggest tasting glue on pizza or cite nonexistent legal cases. Restricting inputs to vetted papers sharply reduces these failures. Instead of free-form speculation, the assistant assembles a literature-style answer, supported by numbered references that correspond to specific studies. This is a peer-reviewed research assistant that behaves more like a critical reader than a chatty search engine. It still summarizes and interprets, but it does so within the guardrails of published science, making its outputs more trustworthy and far easier to audit than the typical black‑box response.
Design Choices: From Citations Pane to Consensus Meter
Consensus differs from general chatbots in how it displays information as much as in how it sources it. Each answer arrives with a clearly separated references pane, with studies neatly numbered to match statements in the response. Users can click through to scan an overview, inspect metadata, or download the original paper when available. This layout encourages people to read beyond the summary and evaluate the underlying evidence. For logged‑in members, Consensus adds richer literature review features and a Consensus Meter, which weighs findings across multiple papers to show how strongly the research aligns. While details are still evolving, the intent is clear: move away from one‑off quotes toward a transparent view of where the evidence clusters. In effect, the tool nudges people toward research literacy, instead of asking them to trust the model’s word alone.
Who Needs a Fact-Checked AI Assistant the Most?
Because it is built on peer-reviewed sources, Consensus is particularly useful wherever the cost of being wrong is high. Academic users gain a literature-aware companion that can surface relevant studies and summarize themes faster than manually skimming dozens of PDFs. Medical and scientific professionals get an extra lens on current evidence—still something to cross-check, but far closer to their standards than generic web search answers. The tool’s focus also suits legal, policy, and technical research teams who need trustworthy AI tools that do not improvise facts to sound confident. Android Authority notes that Consensus is not meant as a direct competitor to broad tools like Claude, ChatGPT, or Gemini; instead, it fills a different niche. It is an AI you turn to when the question is not “What sounds plausible?” but “What does the published evidence show?”
Toward a More Trustworthy AI Ecosystem
Consensus is part of a wider shift toward AI systems that explain their sources and limits. In the same Android Authority roundup, other tools highlight different aspects of trust: KitLegit warns that its AI-based football shirt authentication is not 100% foolproof, reminding users to bring skepticism to AI claims, while Open Notebook offers an open-source, self-hosted alternative to NotebookLM so people can control where their research data lives and which models analyze it. Mindtrip shows how AI can organize travel plans while still benefiting from usability improvements. Together, these services hint at a maturing ecosystem where transparency, user control, and scope matter as much as raw model power. For critical domains, the path forward looks closer to Consensus: constrained, citation-driven, and built to be questioned rather than blindly believed.