The Hidden Economics of AI Inference
As AI agents move from demos to production, two invisible costs are choking profitability: token overuse and GPU underutilization. Every long-horizon workflow—planning, research, multi-step reasoning—forces models to repeatedly reload context, driving up token bills and stretching latency. At the same time, GPUs waste cycles recomputing work because prior context and intermediate states are not cached close enough to the accelerator. This combination makes AI inference efficiency a core design problem, not an afterthought. Developers increasingly discover that raw model quality matters less than how intelligently requests are routed, how context memory is stored, and how often computation is reused. That shift has opened a lane for open-source AI agents and infrastructure to compete directly with proprietary stacks, focusing on token cost reduction and GPU utilization optimization rather than shiny front-end features. OpenSquilla and MemKV are two emerging tools that put these concerns at the center of their architectures.
OpenSquilla: Model Routing and Memory as Cost Controls
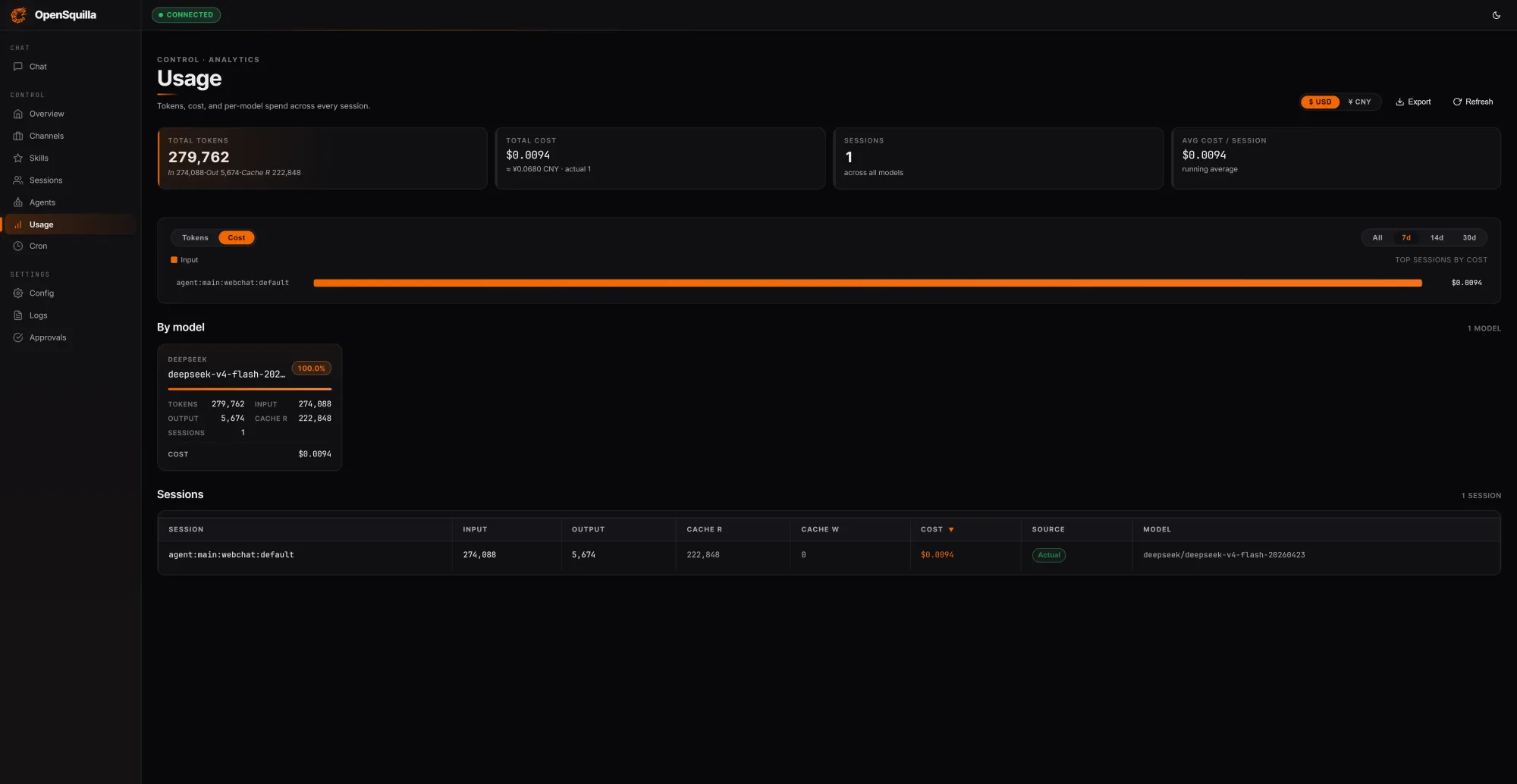
OpenSquilla positions itself as a self-hostable, open-source AI agent runtime optimized for token cost reduction. Instead of treating every prompt the same, it uses an ML-based routing classifier that blends handcrafted signals—such as message length, code presence, and keyword patterns—with embedding-derived semantics to score task complexity. Simple queries are automatically dispatched to cheaper models, and deep reasoning features are disabled for lightweight prompts so teams avoid paying for extended chain-of-thought when it is unnecessary. In a local test run, OpenSquilla processed 279,762 tokens for a total cost of USD 0.0094 (approx. RM0.04), with 222,848 tokens—around 80% of inputs—served from cache by reusing context across turns. This agent runtime also exposes quota hooks and per-call cost tracking, giving developers real-time visibility into AI inference efficiency and enabling automatic throttling before token spend spirals out of control.
Four-Tier Cognitive Memory for Efficient Context Reuse
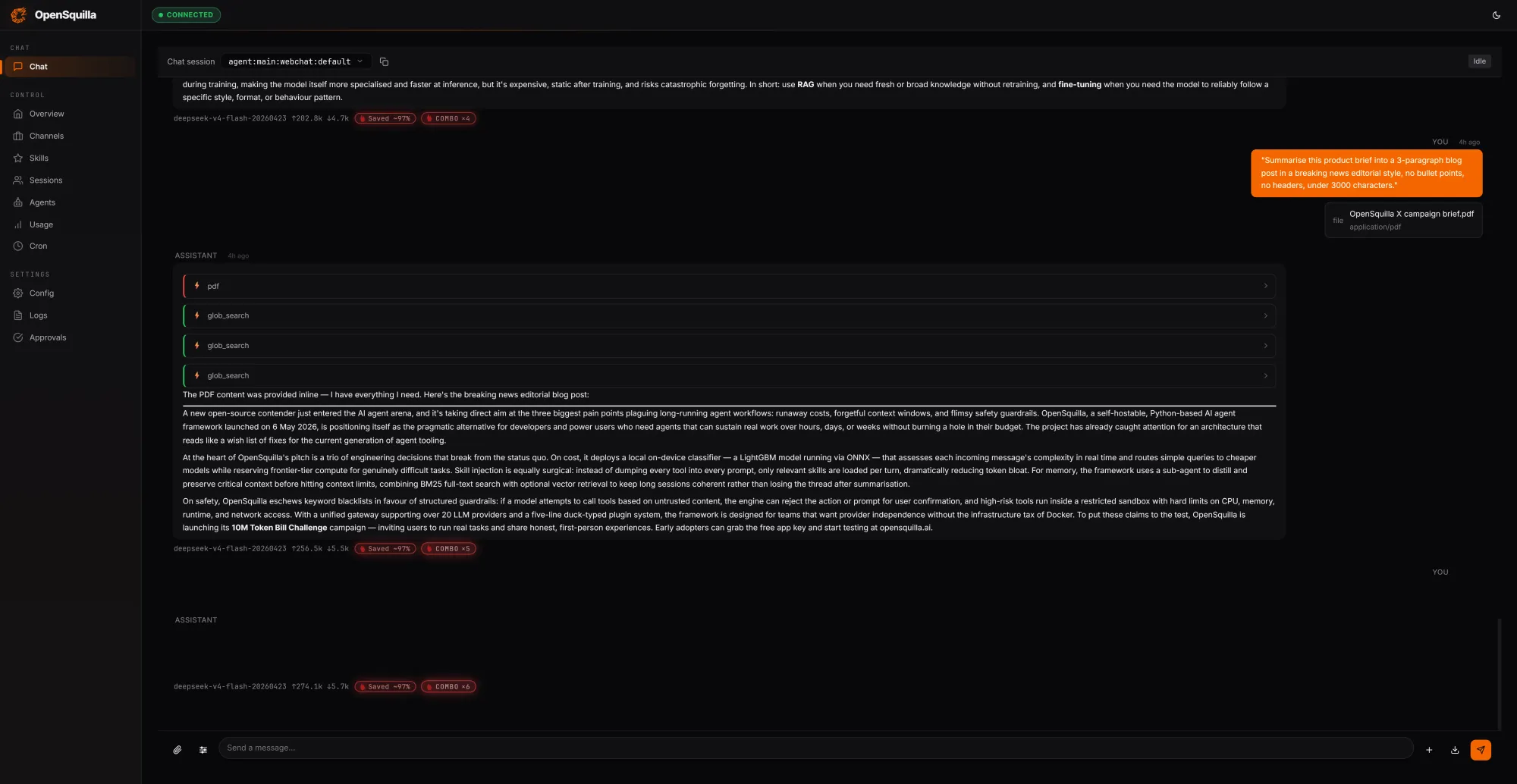
Beyond routing, OpenSquilla attacks AI inference inefficiency through a four-tier memory architecture inspired by human cognition. Working memory tracks the current task, episodic memory captures experiences and causal chains across sessions, semantic memory stores long-lived facts and rules, and raw memory serves as an audit and retraining corpus. Retrieval combines vector-semantic search with BM25 full-text search running in parallel, with embeddings generated locally via ONNX inference to keep data on-device. Frequently accessed items are automatically promoted as “hot” memory, while temporal decay lets outdated context fade unless explicitly marked evergreen. A daily consolidation pass restructures fragmented memories into denser knowledge, which further improves context memory caching effectiveness. According to the project’s benchmarks, this coordinated approach to routing and memory management can reduce token spend by 60–80% versus a flat, single-model setup, giving developers a practical path to open-source AI agents that scale economically.
MemKV: Slashing the ‘Recompute Tax’ on GPUs
While OpenSquilla optimizes tokens, MinIO’s MemKV focuses on GPU utilization optimization by eliminating what it calls the “recompute tax.” In multi-step reasoning workloads, context is often dropped because the infrastructure near the GPU cannot retain enough of it, forcing models to redo work. MemKV introduces a flash-based context memory store, accessible end-to-end over high-speed Ethernet with RDMA, that holds persistent, shared context across GPU clusters. MinIO reports that on representative benchmarks, this architecture delivers over 95% GPU utilization and roughly 50% lower cost per token. By improving both Time to First Token (TTFT) and Time Per Output Token (TPOT), MemKV turns context into durable, addressable state—more like a database row than a throwaway cache entry. This “context-as-a-service” model lets any inference replica or agent reload prior state in microseconds instead of rebuilding it from scratch on every call.

Open Infrastructure, Fewer Barriers to Agentic AI at Scale
Together, OpenSquilla and MemKV illustrate how open-source infrastructure can reshape the economics of AI agents. By treating context as a first-class asset—whether through four-tier cognitive memory or petascale context stores—these tools attack both token cost and hardware waste. Developers can keep serving layers stateless, offload session and agent state into dedicated context stores, and avoid sticky sessions or GPU-bound state that complicates scaling. Local deployments of MemKV per GPU cluster and self-hostable runtimes like OpenSquilla also reduce reliance on proprietary vendor stacks, mitigating lock-in while enabling fine-grained control over token cost reduction strategies. As analysts push the conversation from raw model scores to token economics, AI inference efficiency and context memory caching are becoming competitive differentiators. For teams aiming to deploy agentic AI profitably at scale, open-source AI agents and infrastructure are rapidly evolving from experiments into essential building blocks.