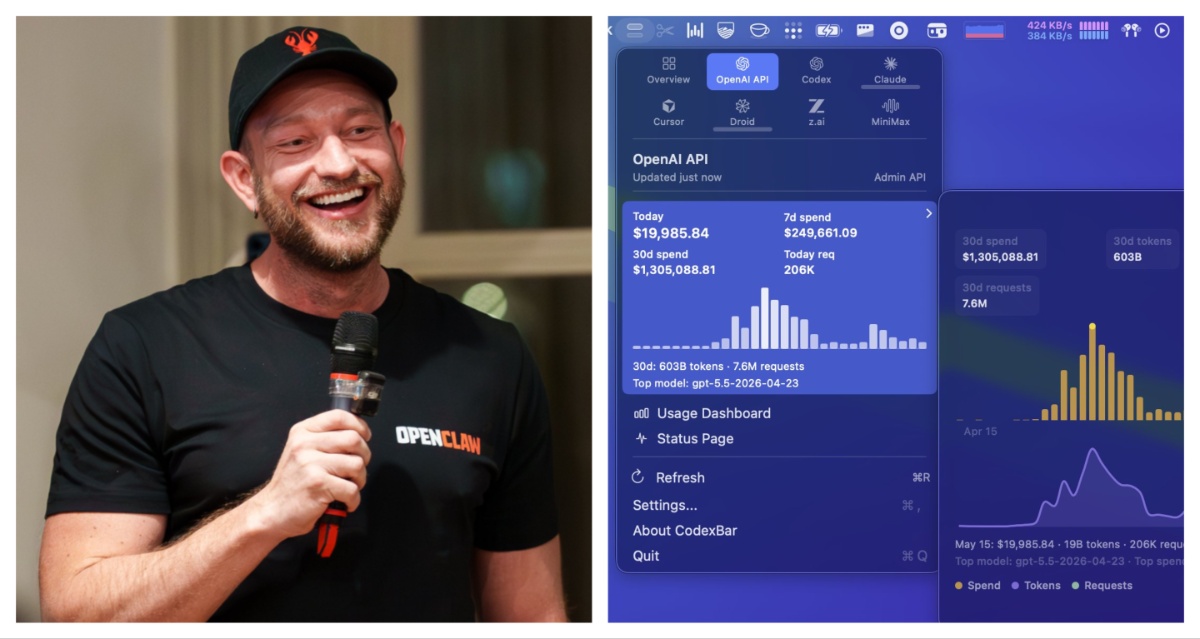
A Rare Look at Extreme AI Token Costs
When OpenClaw creator Peter Steinberger shared a screenshot of his CodexBar usage dashboard, it offered a rare, quantified glimpse into high-volume AI token costs. Over 30 days, the dashboard showed spending of USD 1,305,088.81 (approx. RM6,018,000) on OpenAI’s API, covering 603 billion tokens across 7.6 million requests. On a single day, 15 May, he tallied USD 19,985.84 (approx. RM92,000) in token spend, 19 billion tokens, and 206,000 requests, with the top model listed as gpt-5.5-2026-04-23. For many observers, the comparison was stark: that monthly token bill rivals the annual compensation of multiple senior engineers, yet it is being burned purely on inference and experimentation. In an industry where most teams never see their detailed token consumption, Steinberger’s post effectively turned his usage into a case study on what “peak” AI development looks like in financial terms.

When Your Employer Pays the Token Bill
The eye-popping line item is not coming out of Steinberger’s personal bank account. Now working at OpenAI, he clarified that the usage is effectively a perk, calling it “OpenAI supporting OpenClaw” and confirming that he is not charged for the tokens. That arrangement surfaces a critical question for enterprise AI spending: who actually owns and manages token consumption risk? For Steinberger, free compute is a talent benefit and a strategic subsidy, enabling him to run AI agents that listen to meetings, launch work from voice instructions, and filter spam while shipping tools like OpenClaw and CodexBar. For enterprises, however, similar workloads translate directly into operating expenses. The same experiments that are subsidised for a star developer could become a recurring, seven-figure cost centre once rolled out to teams at scale, forcing CFOs to treat tokens as a core line item alongside cloud infrastructure.
Tokenmaxxing Culture and the New Power User Gap
Steinberger’s dashboard also spotlights a growing cultural and economic divide between casual AI users and heavy-duty developers. On social platforms, commenters described his usage as “bankrolling a small startup,” while others questioned whether that spend might be better directed toward additional engineers. Yet in Silicon Valley, “tokenmaxxing” is increasingly a badge of honour, with competitive leaderboards and bragging rights tied to who can push the most tokens through frontier models. This elite group operates with effectively zero marginal token cost, treating models as an abundant resource. By contrast, most organizations experiment with AI in tightly constrained pilots, worried about unpredictable bills and unclear ROI. The result is a two-speed AI economy: subsidised power users racing ahead, and cost-conscious enterprises moving cautiously, despite relying on the same underlying APIs and pricing tables.
Subsidised OpenAI Pricing and Distorted Signals
Reactions to Steinberger’s spend quickly turned to the underlying economics. Commenters noted that current OpenAI pricing is heavily subsidised, arguing that the real compute cost of 603 billion tokens would be much higher if fully passed through. Former tech leaders have warned that cash, not energy, is the true constraint on AI, and Steinberger’s numbers embody that tension: labs are absorbing enormous costs to encourage token consumption and lock in developer behaviour. Steinberger himself stressed that disabling “fast mode” could make his stack about 70% cheaper, likening the reduction to the cost of a single employee. But that comparison underscores the distortion: workers are now in a position to spend the equivalent of a full salary on tokens without a clear value benchmark. When pricing signals are softened by subsidies, behaviour can drift into bubble territory long before profits catch up.
What Enterprise AI Budgets Can Learn from OpenClaw
For enterprises, Steinberger’s experiment is less a cautionary tale and more a stress test of future spending patterns. His OpenClaw work shows how AI-first workflows might look if tokens were treated as nearly free: agents running continuously, monitoring meetings, triaging content, and launching jobs with minimal human friction. That vision is compelling, but the token consumption is enormous. Most companies will not enjoy OpenAI-style subsidies; they will pay retail prices and answer to budgets. To avoid runaway bills, organizations will need explicit token budgets, per-team quotas, and governance around usage modes like “fast” versus cheaper options. They also must tie token spend to measurable outcomes: revenue, reclaimed engineering hours, or operational savings. The Steinberger case highlights that AI token costs aren’t just a technical detail—they are becoming a central design constraint for any serious enterprise AI strategy.