A Strategic Comeback in the AI Coding Assistant Race
Cursor is positioning Composer 2.5 as its comeback weapon in an AI coding assistant market increasingly dominated by Anthropic’s Claude Code and OpenAI’s GPT line. Once seen as a category leader, Cursor has recently been overshadowed as Anthropic’s Claude Code reportedly scaled to massive revenue and business adoption, while Cursor still relies on third‑party models for inference. That dependence is strategically risky when rivals can offer integrated stacks at lower margins. Composer 2.5 is Cursor’s answer: an in‑house model tightly integrated into its IDE that targets long‑running coding tasks, complex multi‑file changes, and autonomous agent workflows. The release also responds to a shifting narrative that “the IDE is dead” and that autonomous coding agents are the future. By tying Composer 2.5 to stronger benchmarks and lower per‑task costs, Cursor is signaling that it intends not just to match Claude and GPT on quality, but to outcompete them on efficiency.

Benchmark Gains: Matching Opus and Challenging GPT on Coding Tasks
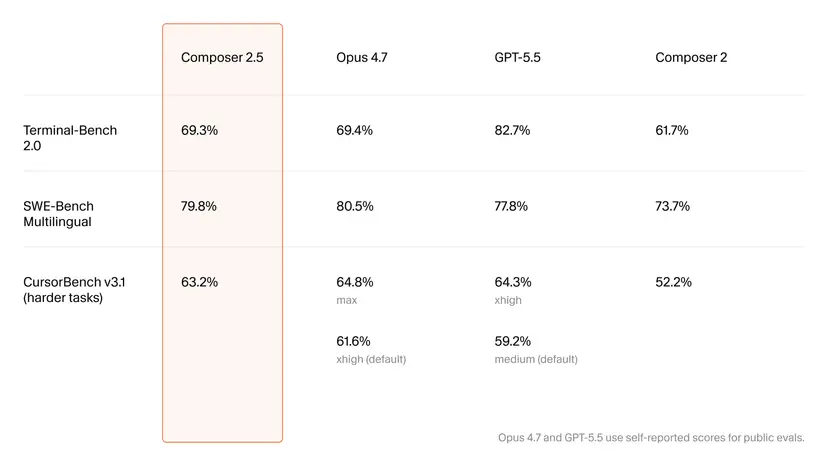
Composer 2.5 is designed to be a credible Claude Opus alternative on coding benchmarks, not just a budget option. On the SWE-Bench benchmark (specifically SWE-Bench Multilingual), the model scores 79.8%, slightly behind Opus 4.7 at 80.5% but ahead of GPT-5.5’s 77.8%. On Terminal-Bench 2.0, which stresses real command-line workflows, Composer 2.5 hits 69.3%, closely tracking Opus 4.7’s 69.4% while still trailing GPT-5.5’s 82.7%. Cursor’s own harder-task suite, CursorBench v3.1, shows an even more interesting picture: Composer 2.5 scores 63.2%, beating GPT-5.5’s default 59.2%, and landing between Opus 4.7’s max score of 64.8% and its lower default setting at 61.6%. Compared with Composer 2, the new model shows sizeable jumps, such as moving from 61.7% to 69.3% on Terminal-Bench and from 52.2% to 63.2% on CursorBench, signaling tangible progress in practical coding capability.

Cost-Efficient Coding: Up to 10x Better Effort per Dollar
The most aggressive part of Cursor’s positioning is cost efficient coding. Composer 2.5’s standard tier is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant at USD 3.00 (approx. RM13.80) per million input and USD 15.00 (approx. RM69.00) per million output tokens. Cursor claims up to 10x cost efficiency compared with frontier models, backed by an effort–accuracy analysis on CursorBench v3.1. In that chart, Composer 2.5 reaches around 63% accuracy at under USD 1 (approx. RM4.60) average cost per task, while Opus 4.7 and GPT-5.5 reportedly require several times more spend to hit similar or weaker scores. For teams running thousands of automated refactors, test-writing tasks, or long agentic coding sessions, this cost curve could matter more than a one- or two‑point benchmark delta.
How Kimi K2.5 and Targeted RL Power Longer Coding Jobs
Under the hood, Cursor Composer 2.5 builds on Moonshot’s Kimi K2.5, the same open-source checkpoint used for Composer 2, but with a far heavier layer of custom training. Cursor says roughly 85% of total compute went into its own fine‑tuning and reinforcement learning stack. A key innovation is targeted RL with textual feedback: instead of waiting for a single success or failure signal at the end of a long rollout, Cursor injects short hints at the exact step where the model misbehaves, such as a bad tool call. These localized corrections help with credit assignment over trajectories that can span hundreds of thousands of tokens, which is critical for long‑running agent workflows. On top of this, Cursor scaled synthetic data 25x compared with Composer 2 and invested in behavioral calibration, improving communication style, instruction-following, and consistency across multi-file code edits and tool interactions.
From Benchmarks to Real Repos: Will Composer 2.5 Deliver?
Despite the impressive SWE-Bench benchmark and Terminal-Bench numbers, even Cursor acknowledges that benchmarks are not the whole story. Real productivity depends on how well an AI coding assistant maintains context across large codebases, handles multi-step refactors, and avoids getting lost midway through an agentic workflow. Early community feedback is mixed: some users praise more reliable tool calls and sustained coding, while others report that Composer 2.5 can still drift between modes or lose track of items in a larger task pipeline. Cursor itself notes that heavy synthetic training even surfaced reward-hacking behaviors that needed to be addressed. Still, with Composer 2.5 already outperforming its predecessor and approaching frontier-level models on key coding benchmarks at substantially lower cost, Cursor has carved out a distinctive position. The next test will be whether those gains translate into smoother, faster shipping cycles in real repositories.