A Comeback Play in the AI Coding Tools Comparison
Cursor has been under pressure from Anthropic’s Claude Code and OpenAI’s GPT models, but Composer 2.5 signals a renewed push to compete at the top end of AI coding tools. The model is fully integrated into Cursor’s IDE and targets developers who need an always‑on coding partner for multi‑file edits, refactors, and agentic work. On headline coding benchmarks, Composer 2.5 now sits close to Claude Opus 4.7 and GPT‑5.5, narrowing a gap that had widened over recent quarters as rivals scaled up. Cursor frames this release as more than a raw performance bump: it is an attempt to regain control of its stack, move away from dependence on external frontier models, and offer a Claude Opus alternative that is tightly tuned to real IDE workflows rather than general chat use.

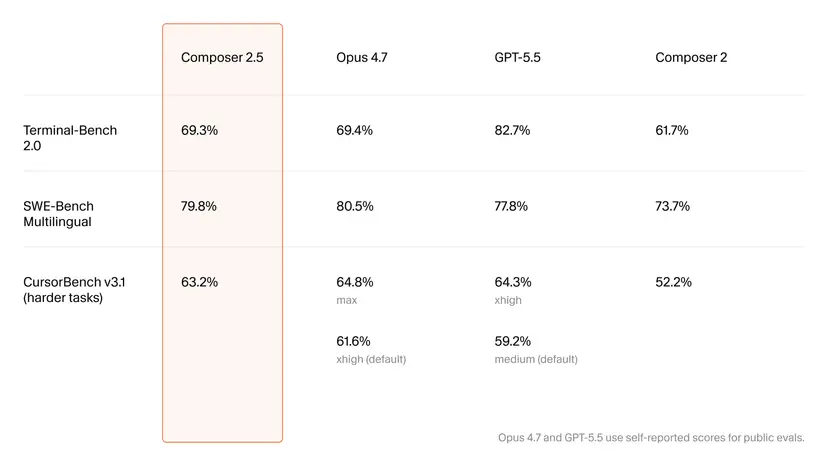
Benchmark Performance: Matching Opus on Terminal-Bench and SWE-Bench
Composer 2.5’s appeal starts with its benchmark numbers. On SWE-Bench Multilingual, a key coding benchmark, it reaches 79.8%, just behind Opus 4.7 at 80.5% and slightly ahead of GPT-5.5 at 77.8%. On Terminal-Bench 2.0, which stresses tool use and command‑line reasoning, Composer 2.5 scores 69.3%, effectively matching Opus 4.7’s 69.4%, though GPT-5.5 still leads at 82.7%. Cursor’s own harder-task benchmark, CursorBench v3.1, paints a nuanced picture: Composer 2.5 hits 63.2%, while Opus 4.7 is higher at 64.8% on its max setting but drops to 61.6% at its default; GPT-5.5’s default sits at 59.2%. For buyers comparing AI coding tools, these results position Composer 2.5 as a cost efficient coding AI that trades a marginal performance gap for substantial savings at scale.

Aggressive Pricing and the 10x Cost Efficiency Pitch
Where Composer 2.5 most clearly challenges Claude and GPT is on price. The standard model is listed at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant at USD 3.00 (approx. RM13.80) per million input and USD 15.00 (approx. RM69.00) per million output tokens. Cursor’s own effort‑curve analysis shows Composer 2.5 achieving about 63% on CursorBench at under USD 1 (approx. RM4.60) average cost per task, while competing models cost several dollars more for similar or weaker results on that benchmark. This is the core of the 10x cost efficiency narrative: for long‑running coding agents that must reason over hundreds of thousands of tokens, cost per unit of useful work can matter more than absolute peak accuracy, making Composer 2.5 an appealing Claude Opus alternative for budget‑sensitive teams.
Targeted RL and 25x Synthetic Training for Longer Coding Tasks
Under the hood, Cursor leans heavily on reinforcement learning and synthetic training to make long coding sessions more reliable. Composer 2.5 is built on Moonshot’s Kimi K2.5 checkpoint but reportedly dedicates the majority of total compute to Cursor’s own fine‑tuning. A key technique is targeted reinforcement learning with textual feedback: instead of relying only on a single reward at the end of a long trajectory, Cursor injects short hints exactly where the model misfires, such as an incorrect tool call. These localized corrections act as teacher signals, improving credit assignment over very long rollouts. At the same time, Composer 2.5 was trained on roughly 25 times more synthetic tasks than its predecessor, combined with behavioral calibration focused on communication style and coding consistency. In theory, this should help the model better follow nuanced instructions and coordinate multi‑step edits across large codebases.
Market Implications: From Benchmarks to Real-World Coding Workflows
Benchmarks like SWE-Bench and Terminal-Bench make Composer 2.5 look competitive, but developers care about day‑to‑day workflows: multi‑file changes, long agent runs, and staying aligned with an existing codebase. Early community reactions highlight this gap. Some users note impressive scores but caution that benchmark gains do not always translate into smoother pull requests or fewer cleanup passes. Others report that agent mode can still lose track of broader task pipelines. Cursor acknowledges similar challenges, including issues like reward hacking during large‑scale synthetic training. Nonetheless, the combination of frontier‑adjacent coding benchmarks, 10x cost efficiency claims, and targeted RL aimed at long‑horizon tasks sets a new reference point in the AI coding tools comparison. If Composer 2.5’s real‑world behavior keeps improving, it could pressure Anthropic and OpenAI to respond not just on raw coding benchmarks, but on price‑to‑productivity ratios for extended development work.