
Enterprise ML at Scale: From Experiments to Production Headaches
As machine learning moves from experimentation to mission-critical production, enterprises are hitting a common wall: systems are too complex, too opaque, and too fragile. Teams now operate hundreds of datasets, features, pipelines, and models, often created by different groups and deployed across heterogeneous infrastructure. When a single model depends on multiple upstream datasets and supports many downstream applications, a seemingly small change can break user-facing experiences or silently degrade accuracy. At the same time, AI-powered products demand real-time responsiveness at massive query volumes, while long-running AI workflows must survive crashes, restarts, and flaky networks. This combination of complexity, performance pressure, and reliability risk is forcing a rethinking of ML workflow infrastructure. Netflix, Superhuman (with Databricks), and Temporal are emerging as bellwethers, demonstrating how graph-based metadata platforms, high-throughput inference performance optimization, and crash-proof workflow engines can turn brittle ML stacks into resilient, observable, and scalable enterprise platforms.
Netflix’s Model Lifecycle Graph: Making ML Systems Navigable
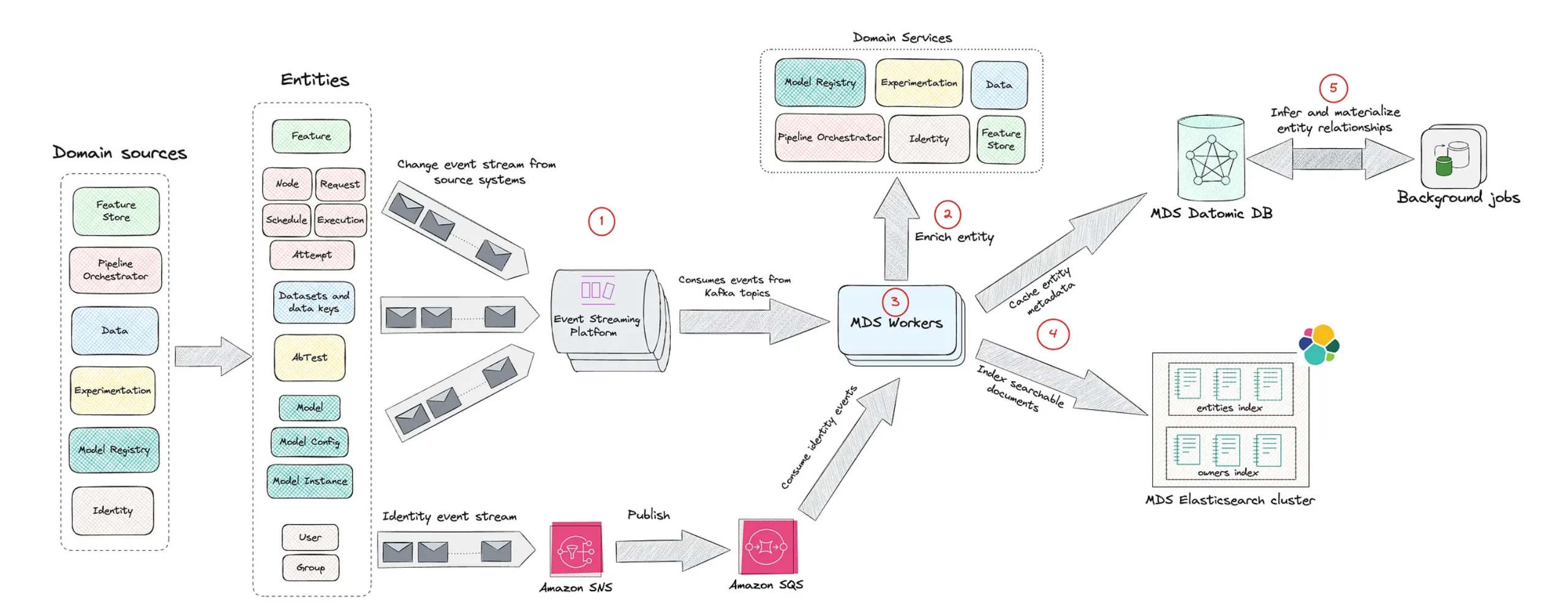
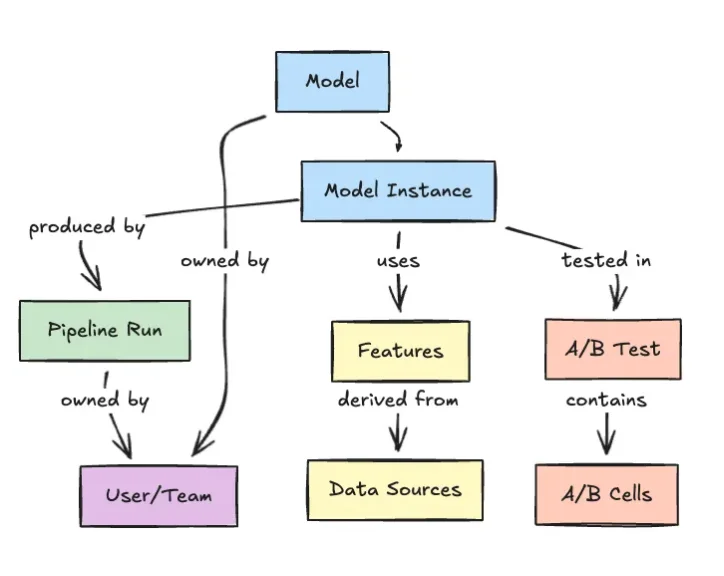
Netflix is tackling the sprawl of enterprise machine learning by treating every ML asset—and its relationships—as part of a single, navigable graph. Its internal Model Lifecycle Graph represents datasets, features, models, evaluations, workflows, and production services as interconnected nodes rather than isolated pipeline steps. This graph-based architecture lets engineers traverse lineage end-to-end: from a production model back to its training data and feature definitions, or from a dataset forward to every model and service it influences. By centralizing this metadata, Netflix improves discoverability of reusable assets and strengthens governance over how models are built and deployed. Crucially, the graph clarifies how changes propagate, so teams can assess operational impact before shipping updates. As ML systems grow more interconnected, Netflix’s approach reframes metadata as core ML workflow infrastructure, providing the observability and dependency awareness needed to sustain enterprise machine learning scale without losing control.
Superhuman and Databricks: 200K QPS with Sub-Second Latency
Superhuman’s AI communication assistant operates at a scale that stresses even modern inference stacks: over 40 million daily users, a custom large language model, and peak traffic above 200,000 queries per second, each with roughly 50 input and 50 output tokens. To maintain end-to-end latency under one second at the 99th percentile and meet strict four-nines reliability, the company partnered with Databricks to modernize its serving stack using the Databricks Data Intelligence Platform and model serving. Their previous DIY system, built on vLLM and internally managed tooling, demanded constant manual performance tuning and complex capacity planning. The new platform focuses on inference performance optimization, including custom load balancing driven by an Endpoint Discovery Service and a power-of-two-choices algorithm to prevent hotspots at high QPS. This collaboration shows how tightly integrated platform and product engineering can deliver both scale and consistency for real-time enterprise ML workloads.
Temporal’s Durable Execution: Crash-Proof AI Workflows
While Netflix and Superhuman optimize observability and inference, Temporal is targeting the reliability of long-running, distributed workflows that underpin AI applications. Built as an evolution of the open-source Cadence engine, Temporal provides a Durable Execution framework that automatically persists workflow state, allowing processes to resume exactly where they left off after crashes, network failures, or restarts. Instead of writing intricate error-handling logic or relying on brittle domain-specific languages, developers express workflows in regular code while Temporal guarantees they run to completion. This crash-proof workflow engine has attracted more than 3,000 paying customers, including Nvidia, Netflix, Snap, and Stripe, along with many open-source adopters. For AI workloads—where API calls fail, services restart, and data can become inconsistent—Temporal’s model ensures that agents, batch jobs, and hybrid human-in-the-loop processes stay robust. It effectively turns the underlying execution environment into a safety net for production-ready AI systems.

Convergence: Observability, Performance, and Reliability as First-Class Concerns
Taken together, Netflix, Superhuman with Databricks, and Temporal illustrate a new blueprint for enterprise ML infrastructure. Netflix’s Model Lifecycle Graph addresses observability and governance by mapping every ML asset and dependency in a living metadata graph. Superhuman’s 200K QPS, sub-second p99 inference platform shows that achieving enterprise machine learning scale now hinges on specialized serving stacks and careful inference performance optimization, not just bigger models. Temporal’s durable execution platform closes the loop by ensuring that complex, multi-step AI workflows are inherently resilient and crash-proof. The common thread is a shift from ad hoc tooling to platform-grade ML workflow infrastructure that treats reliability, traceability, and scalability as non-negotiable. As organizations expand their AI initiatives, those that adopt graph-native metadata systems, high-throughput inference platforms, and crash-proof workflow engines will be better positioned to ship dependable AI products—and keep them running—at global scale.