
What Claude Opus 4.8 Is and Why It Matters
Claude Opus 4.8 is Anthropic’s new flagship large language model release focused on reducing code errors, accelerating response times, and enabling dynamic multi-agent workflows for complex software and knowledge work. It arrives 41 days after Opus 4.7 and is marketed as a “modest but tangible improvement” that builds on the previous generation rather than replacing it outright. The central promise is predictable productivity gains without higher costs. Anthropic states that Opus 4.8 is four times less likely to let code flaws pass unnoticed than its predecessor, while Fast mode runs 2.5 times faster and three times cheaper than before. At the same time, alignment work has improved “sharper judgement” and more honest progress reporting. For developers and enterprises, Claude Opus 4.8 performance means more reliable AI code generation, fewer silent failures, and shorter feedback loops across engineering and analytical workflows.
Quantifying Code Reliability and Benchmark Wins
The headline improvement in Claude Opus 4.8 performance is error reduction. Anthropic reports the model is four times less likely to let code flaws slip through, which corresponds to roughly a 75% reduction in unnoticed defects compared with Opus 4.7. On SWE-Bench Pro, a benchmark based on resolving real GitHub issues, Opus 4.8 scores 69.2%, outpacing GPT-5.5 and Gemini 3.1 Pro in Anthropic’s internal comparisons. Artificial Analysis adds another data point: Opus 4.8 scores 61.4 on the Artificial Analysis Intelligence Index, compared with 60.2 for GPT-5.5 (xhigh). These results frame Opus 4.8 as a solid step up in AI code generation improvements rather than a dramatic leap in general intelligence. Knowledge work scores climb from 1753 to 1890, and tool-using tasks such as agentic coding and multidisciplinary reasoning also see several-point gains, signaling more consistent performance in real-world workflows.

Faster Processing and Stable Pricing for Developers
Speed and cost-efficiency are central to Opus 4.8’s appeal. Anthropic says Fast mode now runs at 2.5 times the speed while costing three times less than before, directly cutting latency and token spend for interactive coding, debugging, and analysis. Importantly, base pricing for Opus remains unchanged at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens. That stability means teams can upgrade to the new model without revising their budgets or rate-limit strategies. Opus 4.8 also introduces Effort Control, a slider that lets users choose how much compute to apply to each answer, trading off speed versus depth. High effort is the default, but lighter settings help teams stretch quotas during exploratory work. For enterprises, the combination of lower Fast mode costs and flat base pricing translates into higher throughput with the same spend profile.
Dynamic Workflows and Parallel AI Agents in Claude Code
Beyond raw model quality, Opus 4.8 ships alongside Dynamic Workflows in Claude Code, a research-preview feature for dynamic workflows AI agents coordination. Instead of manually wiring agent teams, users describe an objective and Claude constructs an orchestration script, breaks the work into subtasks, runs them in parallel, and then reconciles and validates the results. Anthropic positions this for codebase-scale tasks such as widespread bug investigations, large migrations, security audits, performance reviews, and architecture analysis across hundreds of thousands of lines of code. A new ultracode setting can allow Claude to decide when to switch into workflow mode automatically, and progress is saved so longer runs can resume after interruptions. Early developer feedback highlights the autonomy and speed of these workflows, which formalize what many teams were doing by hand with multiple AI sessions. The trade-off is higher token consumption, so Anthropic advises starting with tightly scoped projects.

Claude vs GPT Benchmark Context and Rapid Iteration
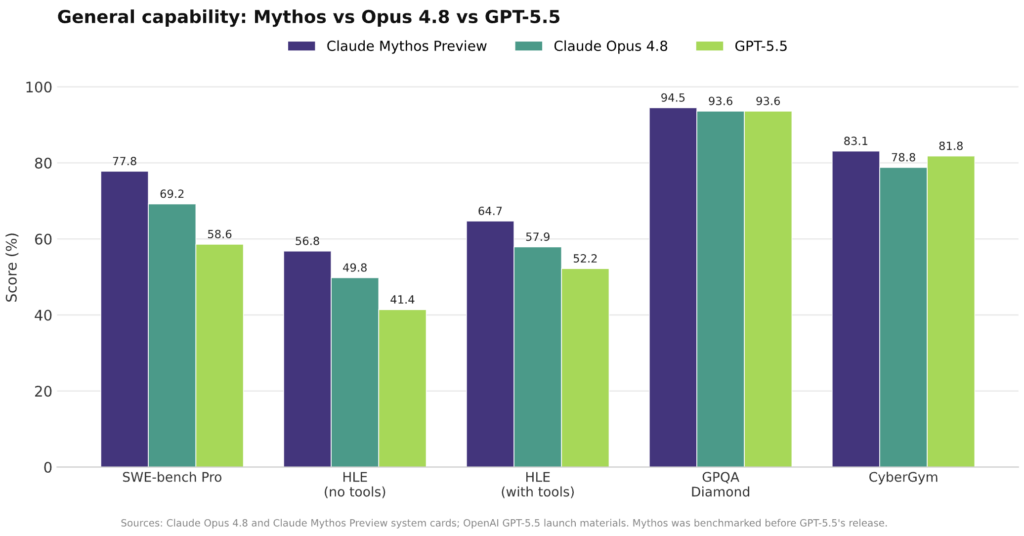
Opus 4.8’s position in the Claude vs GPT benchmark landscape is nuanced. On Anthropic’s internal AECI index, Opus 4.8 scores 155.5, slightly above 4.7’s 154.1 but below the Mythos Preview’s 158.3, indicating incremental rather than dramatic gains in general ability. On SWE-Bench Pro, Opus 4.8’s 69.2 trails Mythos’s 77.8 but still sits well ahead of GPT-5.5’s 58.6 according to reported comparisons. In cyber-related benchmarks, Anthropic’s own system card notes Opus 4.8 is much weaker than Mythos, which produced successful exploits far more often in internal tests. However, Opus 4.8’s strength is accessible, safer coding and knowledge work at standard Opus pricing, not leading-edge offensive capability. Perhaps the most strategic signal is cadence: shipping Opus 4.8 just 41 days after 4.7 shows Anthropic is moving to a rapid iteration rhythm, tightening feedback loops between benchmark findings and production releases.





