From Philosophy to Engineering: What Microsoft’s AI Safety Toolkit Is
Microsoft’s new AI safety toolkit is a set of open and internal frameworks that embed AI agent safety testing, structured design review, and automated vulnerability discovery directly into the agent development lifecycle, turning security from an afterthought into a repeatable engineering practice. The company’s AI Red Team has open-sourced RAMPART, a CI-ready risk assessment framework for red‑team tests, and Clarity, a structured design review agent that helps teams stress-test assumptions before writing production code. Alongside these, Microsoft has introduced MDASH, a multi-model agentic platform for large-scale vulnerability discovery, and Webwright, a Playwright-based web agent framework that converts browser interactions into rerunnable code. Together these AI security tools aim to close the gap between AI agent design and safe deployment by making red-team testing, AI agent safety testing, and vulnerability discovery automation part of everyday engineering work rather than one-off audits.

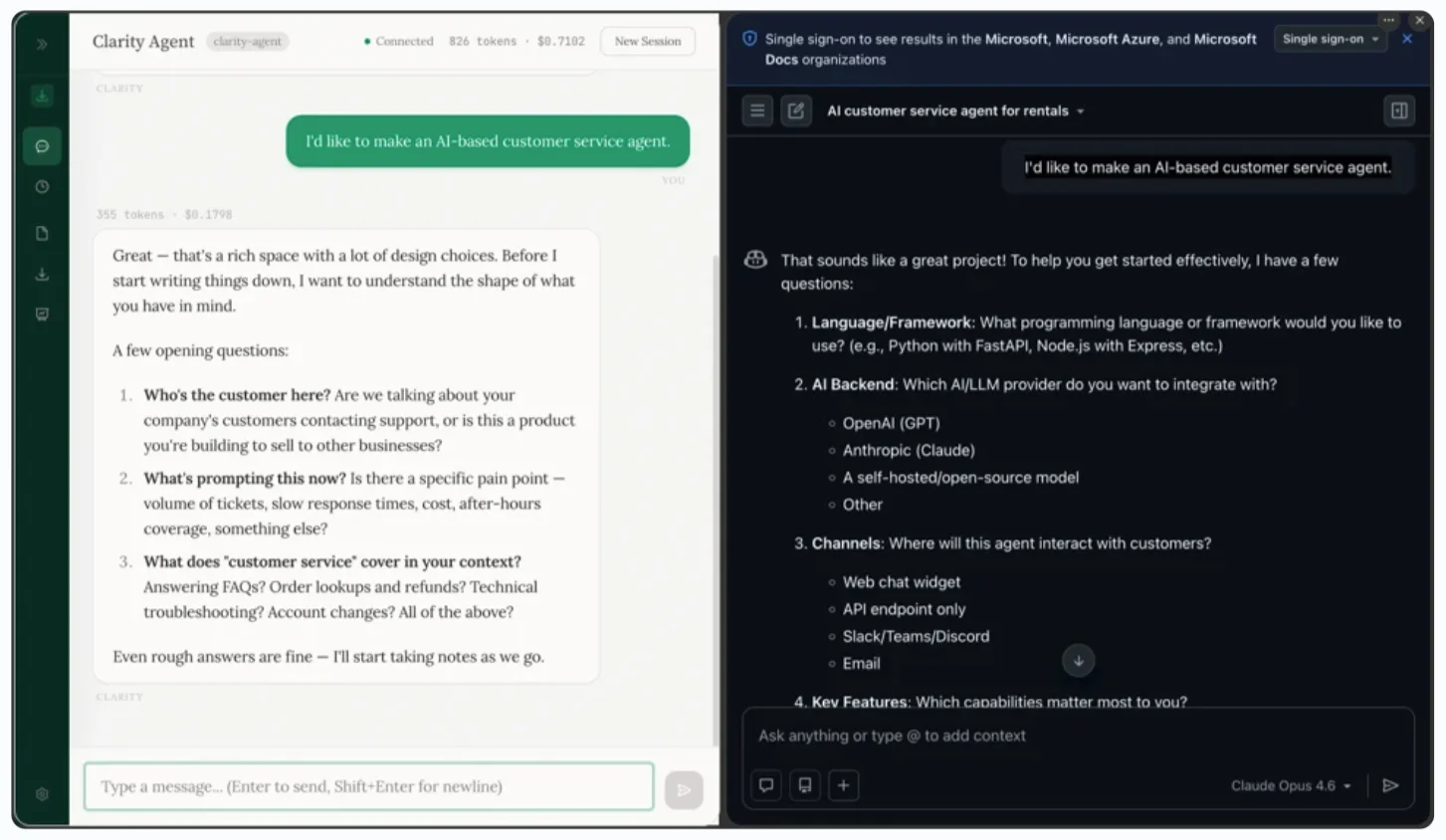
Clarity and RAMPART: Safety from Design Review to CI/CD
Clarity and RAMPART target different stages of the agent development workflow but share a common goal: turn safety checks into standard engineering steps. Clarity acts as a structured design review “sounding board”, helping teams examine assumptions, tool access, and failure risks before they write code. It frames questions about business systems, connected tools, and side effects so security and product teams can agree on acceptable behavior early. RAMPART, built on the PyRIT red‑teaming library, brings those concerns into continuous testing. Developers write pytest cases that describe adversarial scenarios such as prompt injection, connect them through thin adapters, and run them on every code change. Because models are probabilistic, RAMPART supports repeated trials and configurable pass thresholds, so teams can define policies like “this action must be safe in at least 80 percent of runs” and gate merges on those results.
Scaling Red-Team Work: How RAMPART Automates Agent Attacks and Fix Validation
At its core, the RAMPART framework turns one-off red-team exercises into reusable tests that can follow agents from prototype to production. Each test script orchestrates a scenario—such as poisoned content steering an agent toward credentials or unauthorized tools—and evaluates observable outcomes with a simple pass or fail signal. According to Microsoft’s Ram Shankar Siva Kumar, the AI incident response team used RAMPART to generate about 100 variants of a reported vulnerability and then run them nearly 300 times, shrinking work that previously took weeks down to hours. This repeatability matters once mitigations roll out: teams can re-run the same suite to confirm that fixes hold across tools, datasets, and multi‑turn conversations. By making those adversarial checks part of CI, RAMPART adds AI agent safety testing directly alongside integration tests, closing the loop between design intent, implementation, and fielded behavior.

MDASH: Multi-Agent Vulnerability Discovery Automation for Codebases
While RAMPART focuses on behavior, MDASH targets code itself, using a coordinated set of AI agents to automate vulnerability discovery at scale. Microsoft describes MDASH as a multi-model agentic security platform that runs more than 100 specialized agents across stages like scanning, debate, validation, deduplication, and exploitation. Rather than relying on a single model or fixed prompt chain, MDASH uses this pipeline to reason across multiple files and identify lifecycle or concurrency issues in complex systems such as Windows, Hyper‑V, and Azure components. On the public CyberGym benchmark, Microsoft reports that MDASH reached an 88.45 percent score across 1,507 real‑world vulnerabilities, about five points higher than the next best entry. The system is model‑agnostic, so teams can upgrade underlying models while keeping the surrounding validation and proof-generation workflow, making vulnerability discovery automation more maintainable over time.

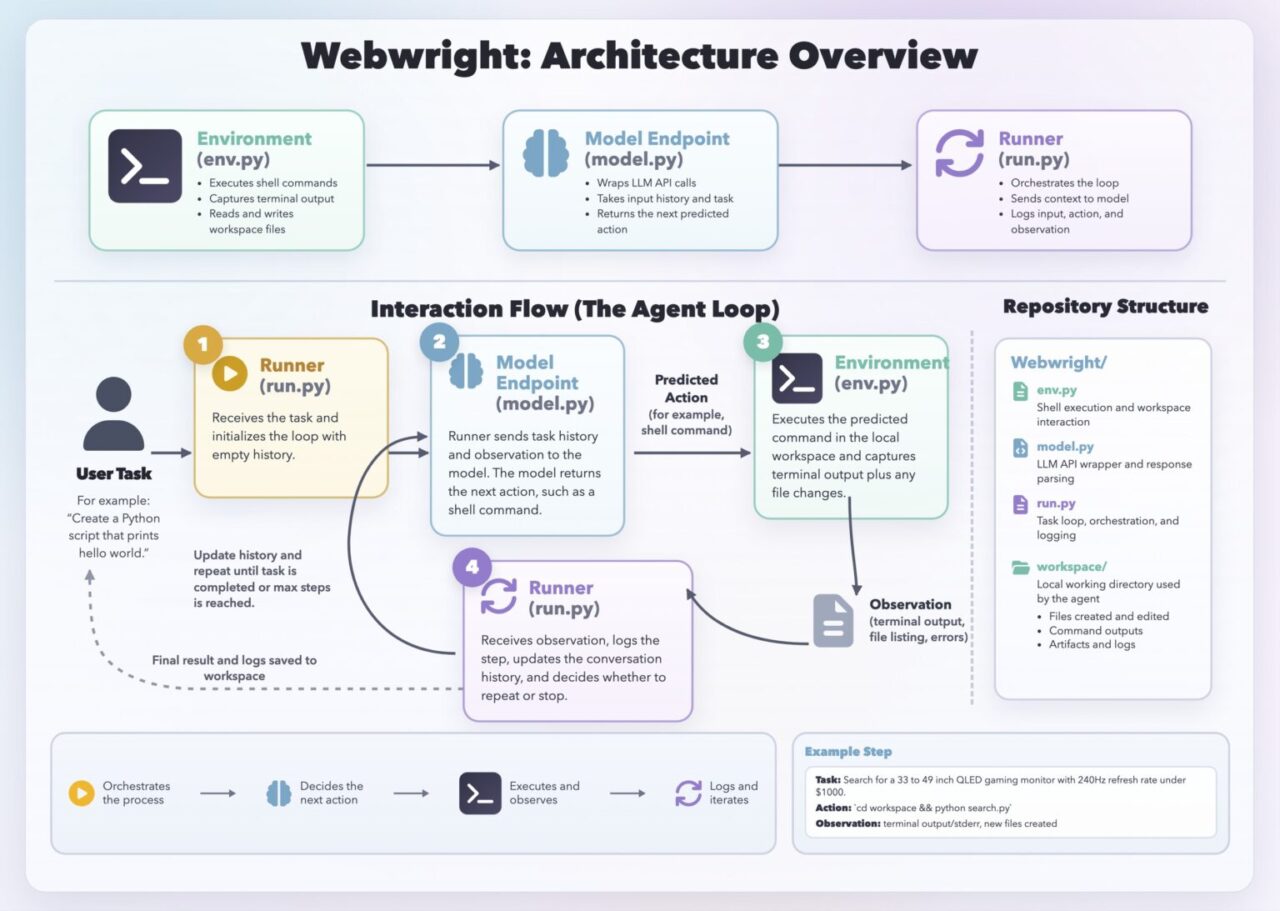
Webwright and the Future of Reliable Agent Workflows
Webwright extends the same safety-first philosophy into browser-based agents by turning fragile sessions into reproducible code. Built on Playwright, Webwright treats web automation as scripts, terminal commands, and local files instead of transient browser memory. When a web agent mis-clicks or fails to complete a workflow, developers can inspect saved logs, screenshots, and Playwright code, rerun the sequence, and repair it without reconstructing the task by hand. Microsoft reports that Webwright scores 60.1 percent on the Odysseys benchmark, a 26.6‑point gain over a base GPT‑5.4 score of 33.5, suggesting that code‑first steering can improve reliability. Because Webwright fits neatly into developer tooling, it also supports collaboration: teams can share failing scripts and apply the same CI practices used with RAMPART. Together, these tools move AI security tools beyond policy into concrete, testable workflows for safe agent deployment.