
When Non‑Deterministic AI Breaks Classic Debugging
Non-deterministic AI debugging is the practice of understanding and controlling probabilistic model behavior in systems where the same input can yield different outputs, making traditional stack traces, breakpoints, and reproduction-based techniques unreliable and incomplete. Classic debugging assumes determinism: repeat the input, step through the stack, and find the failing line of code. Large language models and other agentic systems violate that assumption. Their responses depend on hidden state, token limits, prompt wording, and configuration, so the same call may succeed once and fail the next time. Logs that only show input and output cannot explain why the model changed its mind, and there is no stack trace into the model’s internal reasoning. AI debugging tools need to observe decisions at the level of prompts and responses rather than lines and functions, or teams are left chasing ghosts.
From Stack Traces to Prompt Tracing
In a traditional service, you can rely on a stack trace to show the exact call chain that led to an error, and logs to replay the same path. With non-deterministic AI, the line `const response = await ai.generate({ prompt: userInput });` hides a complex, probabilistic process shaped by system prompts, conversation history, and model parameters. Prompt tracing replaces the missing stack trace for AI by recording the full lifecycle of an AI call: raw user input, system instructions, intermediate prompts, model configuration, token usage, and final outputs. Over time, these traces show which prompts drift, where hallucinations start, and how small changes in context affect results. For AI debugging tools, prompt tracing turns opaque model calls into observable and partially reproducible workflows, making it possible to explain bad outputs instead of treating them as random failures.
Runtime Verification: Moving Safety Into the Inner Loop
As agentic systems gain autonomy, the main risk is no longer generation speed but verification. When developers supervise every step, they read diffs, run tests, and act as the verifier. Once agents run asynchronously from events or schedules, that human gate disappears. According to The New Stack’s coverage of asynchronous agents, generation stopped being the constraint; verification is now the bottleneck that decides whether agents are useful. Runtime verification addresses this by shifting checks into the inner loop, before a pull request lands or an action takes effect. Instead of trusting unit tests against mocks that the agent wrote from its own assumptions, runtime verification runs agent outputs against production-like environments, real dependencies, and policy checks. This closes the loop where it matters: at execution time, with realistic context, so AI systems catch boundary failures early instead of bouncing defects downstream to humans.
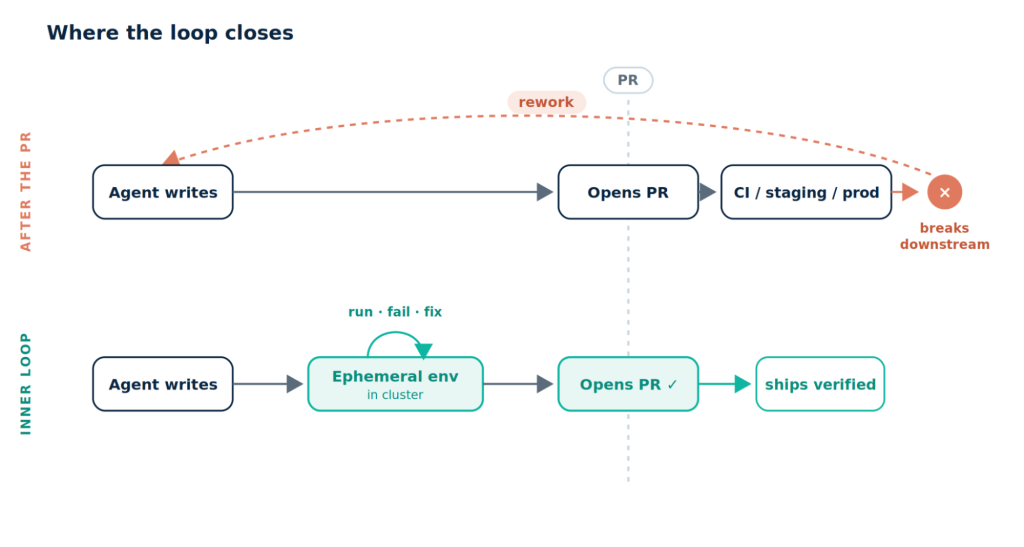
Why Agentic Systems Need Verification Before Execution
Agentic systems that write code or make operational changes are only useful if you can trust what they hand back. An agent that opens a pull request without strong runtime verification is effectively asking another team or tool to grade its work later. The risk is highest in cloud‑native software, where each change interacts with many services, configs, and data paths. Unit tests against stubs prove that the agent’s internal model is self-consistent, not that it behaves correctly in the real system. Runtime verification gives these agents a safe but realistic playground—often ephemeral, production-like environments—where they can run their changes end-to-end, observe failures, and iterate before promotion. When verification becomes part of the agent’s own loop, the system moves from “best-effort suggestions” to trustworthy automation that can merge code or take actions with bounded, observable risk.
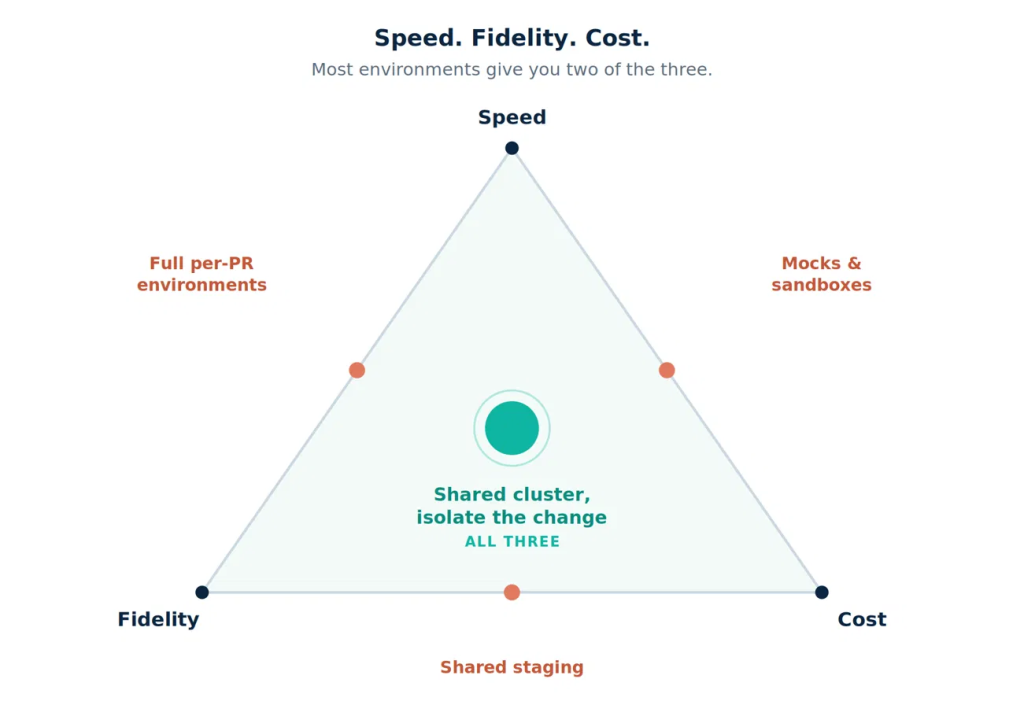
Scaling Cloud‑Native AI with Observability and Checks
To scale cloud‑native AI development, teams need a new debugging and safety stack: prompt tracing for observability and runtime verification for trust. Prompt tracing provides the AI equivalent of a stack trace, making model calls explainable and giving developers a way to reason about non-deterministic AI. Runtime verification grounds agent decisions in real runtime behavior instead of mocks, so autonomous code changes and workflows are proven against the system that will run them. Together, these AI debugging tools create a feedback loop: traces highlight failure patterns, verification environments expose integration gaps, and agents learn to self-correct. This paradigm shift is not optional for agentic systems that operate at scale; without it, each new AI feature multiplies uncertainty. With it, teams can ship more autonomous functionality while keeping their systems observable, predictable, and safe enough for production.





