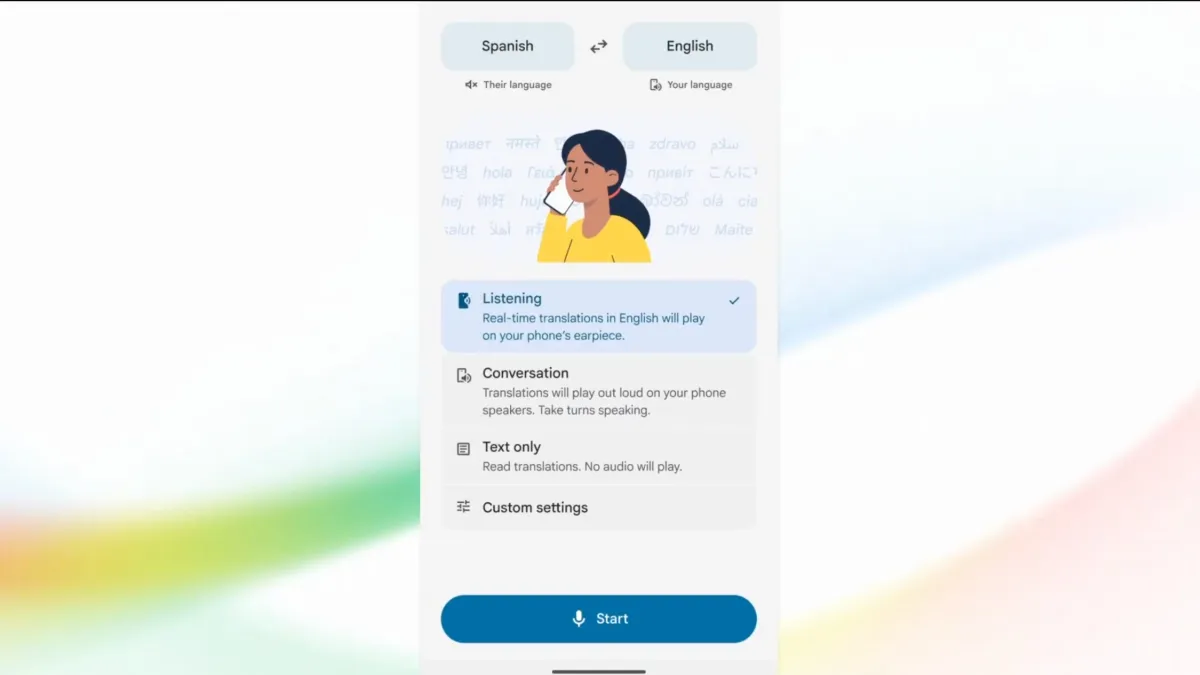
What Gemini 3.5 Live Translate Is and Why It Matters
Gemini 3.5 Live Translate is Google’s new multilingual conversation AI model for real-time speech-to-speech translation that listens, translates, and speaks at the same time, instead of waiting for full sentences, to make cross-language conversations sound natural with only a short delay. This shift from turn-based to continuous processing is the core upgrade over older tools that forced speakers to stop and wait. The model detects spoken language automatically and supports more than 70 languages, creating thousands of language pairings inside a single exchange. It is designed for messy, real-world speech rather than scripted phrases, so it can keep going when people talk over each other or change topics mid-sentence. By shrinking the gap between what is said and what is heard, Gemini 3.5 Live Translate aims to make multilingual communication feel closer to talking in one shared language.
How Continuous Real-Time Speech Translation Works
Earlier translation tools relied on a rigid sequence: one person spoke, the system waited for a pause, then produced a translated block of audio or text. Gemini 3.5 Live Translate replaces that pattern with continuous streaming translation, staying only a few seconds behind the speaker while audio keeps flowing. According to CNET, the model “continuously listens, translates and speaks,” cutting down the awkward pauses that used to break the rhythm of bilingual conversations. It also tries to preserve pacing, intonation, and emotional tone so the translated voice carries cues like emphasis and sentiment, not just literal words. Google says the system is tuned for noisy environments and overlapping voices, meaning it can handle support calls, live tours, or busy classrooms where people interrupt and background sounds never stop.
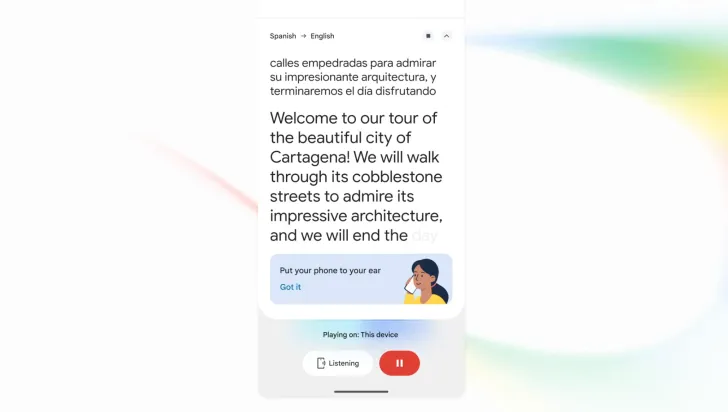
From Google Translate Upgrade to Google Meet and Android
Gemini 3.5 Live Translate arrives as a major Google Translate upgrade and as a new layer inside Google Meet and AI tools. In the Translate app on Android and iOS, users can run speech-to-speech translation in real time with either headphones or a new Android listening mode that routes translated audio through the phone’s earpiece, so it feels like holding a call to your ear. On Google Meet, language coverage jumps from a small set of options to more than 70 languages and over two thousand language pair combinations, vastly widening which teams can use real-time speech translation in meetings. Developers get access through the Gemini Live API and Google AI Studio, letting them build multilingual conversation AI into their own communication platforms, customer support tools, and mobile apps.

Developer Previews, Watermarking, and the Deepfake Question
For builders, Gemini 3.5 Live Translate appears in public preview through the Gemini Live API and Google AI Studio, where they can test latency, speech quality, and behavior in noisy conditions. Spoken output still trails the original speaker by a few seconds, but the goal is a delay short enough that people talk almost without thinking about the system in the middle. To address the growing risk of synthetic audio abuse, Google adds SynthID watermarking to translated speech, marking AI-generated audio so detectors can flag it as synthetic. This watermarking extends earlier SynthID work on other media and positions real-time translation inside a broader safety framework. Together, low-latency speech, developer access, and built-in watermarking show how Google is trying to make fast cross-language conversations practical while still guarding against deepfake-style misuse.





