What the OSS Performance Index Measures—and Why It Matters
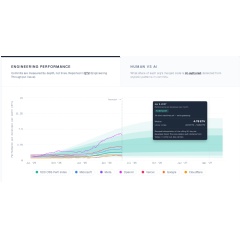
The OSS Performance Index is an open source benchmarking framework that measures engineering productivity metrics by scoring real code changes in public repositories, giving leaders independently verifiable comparisons across major AI vendors instead of relying on vendor-controlled trials or opaque benchmarks. Navigara’s “500 OSS Performance Index” focuses on what engineering teams actually ship by tracking merged commits from Microsoft, Meta, OpenAI, Vercel, Google, and Cloudflare. Each vendor is scored using the same deterministic rules, so an identical code change earns the same score regardless of who wrote it. According to Navigara, average engineering output across the six organizations increased 124.8% over a trailing 90-day series, from 0.86 to 1.94 Engineering Throughput Value (ETV) per developer per month. The index shows a 6x spread between the highest and lowest performers, exposing how uneven engineering output can be even among leading AI players.
From Controlled Trials to Open Source Benchmarking
AI vendors often promote productivity wins based on controlled trials, internal surveys, or custom benchmarks that mirror ideal conditions rather than production reality. Those methods make it hard for engineering leaders to evaluate how tools will perform against their own codebases. Navigara’s OSS performance index responds by grounding AI vendor comparison in public code, where assumptions and scoring rules can be inspected. The methodology is fully documented, and every score is traceable back to a consistent formula. This live benchmark follows actual merged work instead of synthetic tasks, helping teams separate marketing claims from real-world outcomes. By focusing on open repositories and repeatable rules, Navigara offers an independent reference point for leaders deciding where to place AI budgets and which vendors seem to convert investment into meaningful engineering output.
Inside ETV: A Different Take on Engineering Productivity Metrics
Instead of counting lines of code or raw commits, the OSS performance index uses Engineering Throughput Value (ETV) to assess how much meaningful work a change represents. Each merged file change is scored on structural weight, surface area, feature graph position, and whether the change fixes a defect introduced by someone else. This design aims to favor thoughtful, safe changes over noisy activity. Output is split into three non-additive buckets—Growth, Maintenance, and Fixes—so teams cannot hide heavy rework under net-new features. Over the last 90 days, Growth’s share of work increased by 4.4 percentage points, while Maintenance decreased by 7.1 points, signaling a shift toward new capability. Because the scoring engine is deterministic, organizations can apply the same rules to their own repositories and compare their ETV distribution against major AI vendors using the same open source benchmarking approach.
AI Spend, CFO Questions, and Independent Baselines
As AI tools become embedded in engineering workflows, leaders must justify budgets without reliable baselines or shared definitions of productivity. The OSS performance index tackles this by pairing its live benchmark with an AI Spend Calculator (beta) that models how a hypothetical AI budget maps to Growth, Maintenance, and Fixes for each organization in the cohort. This gives CFOs and CTOs a common, repeatable way to talk about cost per ETV delivered, grounded in observed work mixes rather than one-off pilot results. Jirka Bachel, Navigara’s founder and CEO, argues that “the 500 OSS Index measures what actually merged, scored the same way for every org, with a methodology available for anyone to inspect.” Outside organizations can benchmark their teams publicly or privately, using the same framework to see how their engineering output compares with OpenAI, Microsoft, Google, and Meta in real conditions.





