The Hidden Cost Problem in Agentic AI
Enterprises adopting AI agents are discovering that model quality is only half the story; the other half is cost. Long-running agents repeatedly load the same context, rerun the same reasoning steps, and overuse heavyweight models, all of which inflate token spend and depress GPU utilization. These inefficiencies have traditionally been treated as an unavoidable tax on intelligent automation rather than a design flaw in AI infrastructure. As agents evolve from simple chatbots to multi-step reasoning systems with persistent memory, the underlying runtime and storage layers start to dominate the bill. Token optimization and GPU utilization, once niche concerns for infrastructure teams, are becoming board-level questions. Open-source AI tools such as OpenSquilla and MinIO’s MemKV are emerging to address these structural inefficiencies directly, reframing “agent intelligence” as a systems engineering problem where routing, memory, and context sharing matter as much as the model itself.
OpenSquilla: Smarter Routing for AI Agent Cost Reduction
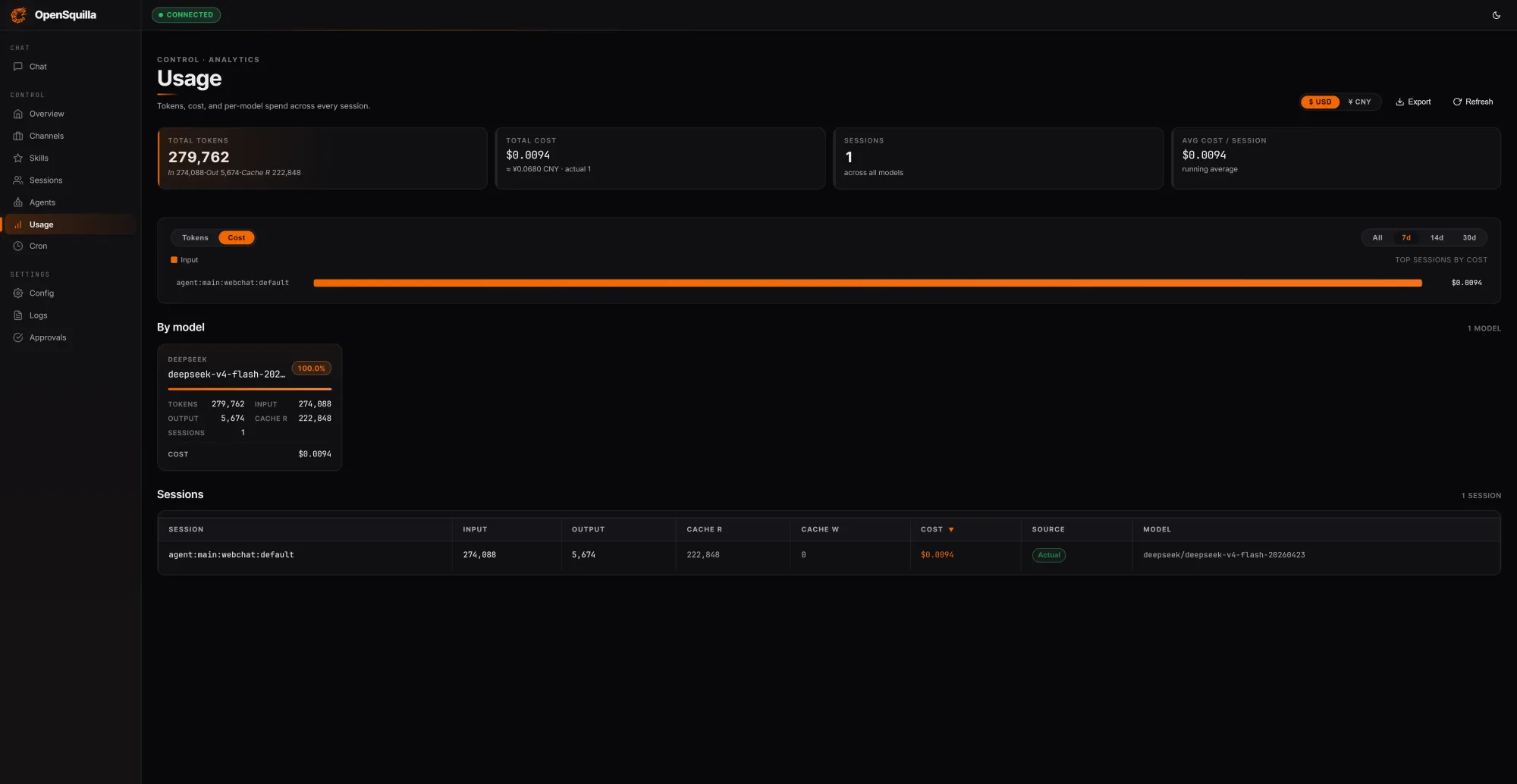
OpenSquilla’s agent runtime takes aim at AI agent cost reduction by treating every request as a routing decision, not just a prompt. An ML classifier blends hand-crafted signals such as message length, presence of code blocks, and keyword patterns with embedding-based semantic features to score complexity. Simple questions are automatically routed to cheaper models, while deep reasoning is explicitly disabled for lightweight tasks, avoiding unnecessary chain-of-thought and excess token usage. Skills are loaded on demand instead of being shoved into every context window, further tightening token optimization. In a local test run, three prompts totaling 279,762 tokens cost USD 0.0094 (approx. RM0.04), with 222,848 tokens—around 80% of the input—served from cache by reusing context across turns. OpenSquilla reports that this coordinated stack of strategies cuts token spend by 60 to 80 percent compared to a flat, single-model setup, while built-in quota hooks and per-call cost tracking help teams detect and throttle overspend.
Rethinking Memory: From Human-Inspired Tiers to Durable Context
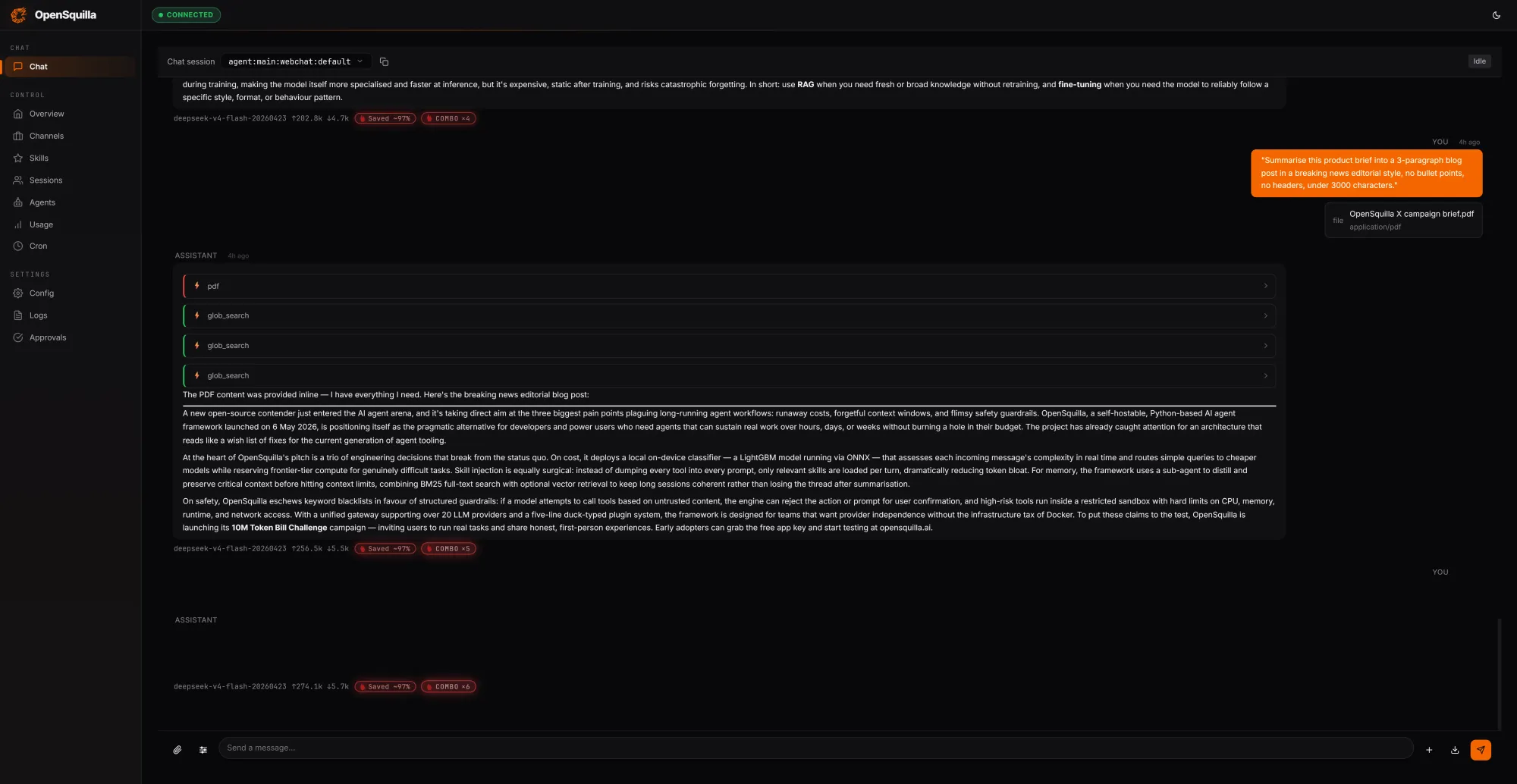
Cost control for AI agents increasingly hinges on how memory is modeled and managed. OpenSquilla introduces a four-tier cognitive architecture inspired by human memory: working memory for the current task, episodic memory for cross-session experiences and causal links, semantic memory for persistent facts and rules, and raw memory as an audit and retraining base. Retrieval combines vector-semantic search with BM25 full-text search in parallel, using local ONNX-based embeddings to keep data on-device and avoid external providers. Frequently accessed entries are automatically promoted, while temporal decay lets stale items fade unless marked as evergreen. A daily consolidation pass restructures scattered memories into denser knowledge, shrinking future context windows. This layered approach reduces redundant tokens by ensuring agents recall what matters instead of reloading everything from scratch, directly reinforcing token optimization while also improving answer quality as agents build structured, reusable internal knowledge over time.
MemKV: Eliminating GPU Recomputation and Boosting Utilization
While OpenSquilla optimizes tokens at the model edge, MinIO’s MemKV attacks waste inside the GPU pipeline. Modern multi-step inference often loses context because the memory closest to the GPU cannot hold enough of it, forcing models to recompute prior work. MinIO brands this the “recompute tax,” a drag on time, energy, and GPU utilization. MemKV provides a native flash-based context memory tier, accessed end-to-end over 800 GbE RDMA, designed to deliver microsecond retrieval at petabyte scale. Benchmarks published by MinIO show 95%+ better GPU utilization and around 50% lower cost per token when MemKV is used to persist and share context across GPU clusters. By turning context into a durable, addressable state—closer to a database row than a cache entry—MemKV enables stateless serving layers where any replica can resume a conversation mid-flight, eliminating sticky sessions and reducing idle GPU time due to repeated setup work.

Open-Source Tokenomics: Democratizing AI Infrastructure Efficiency
Taken together, OpenSquilla and MemKV signal a shift from model-centric bragging rights to token economics and infrastructure efficiency. Both emphasize that AI agent cost reduction is not just about cheaper models, but about smarter orchestration and memory. Open-source AI tools play a key role here: self-hostable runtimes and context stores reduce vendor lock-in, letting enterprises mix and match models, storage tiers, and routing logic without being tied to a single proprietary stack. Developers can deploy MemKV per GPU cluster, treat geographic placement as a performance choice rather than a correctness constraint, and rely on explicit retention policies instead of opaque cache eviction. Meanwhile, OpenSquilla’s built-in quotas, cost tracking, and local embedding pipelines provide transparent levers for token optimization. As analyst voices call for a focus on the cost of operating AI at scale, these open-source foundations are turning “context-as-a-service” into a shared, composable layer rather than a closed, premium feature.