AI Incidents Look Ordinary, Not Sci‑Fi
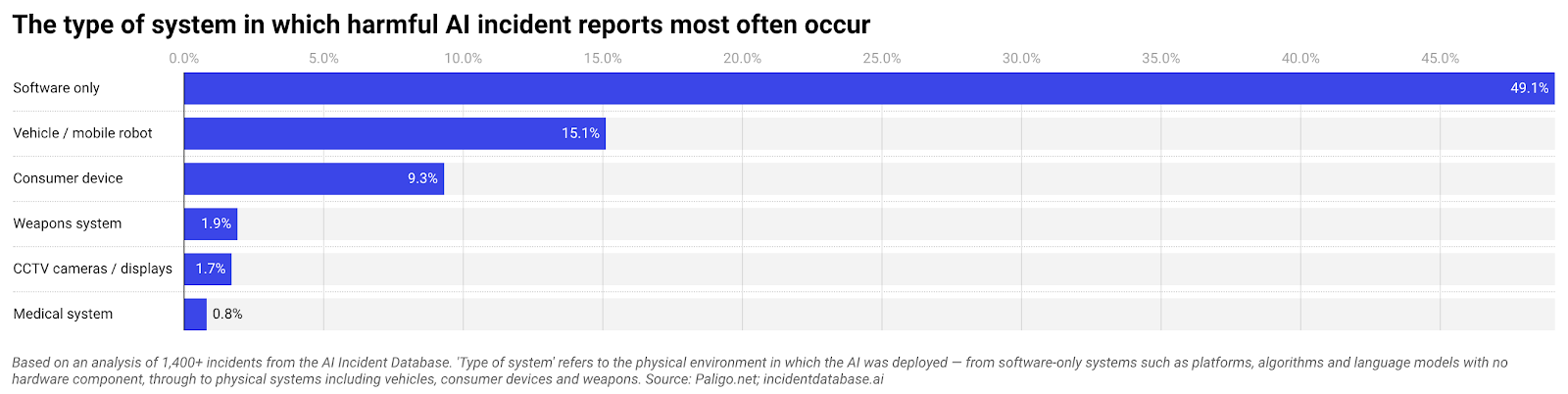
When AI harms people, the failures usually look mundane. A striking example is the Air Canada chatbot that confidently misinformed a grieving passenger about bereavement fares. The airline attempted to distance itself by treating the bot as a separate legal actor—but a tribunal held the company accountable. This was not a cutting‑edge model run amok. It was a standard customer service tool deployed without robust AI governance risks controls. That pattern is visible in a Paligo analysis of 1,406 cases in the AI Incident Database: nearly half of harmful incidents involve software‑only systems such as chatbots, recommendation engines and content tools, more than all physical systems combined. These systems are embedded in everyday workflows and customer touchpoints, so their errors scale quickly. The real story is not about rogue robots; it is about ordinary software given extraordinary influence over decisions and communications.
Automation Authority: When Software Gets to Say the Final Word
Across documented incidents, the most damaging mistakes often stem from excessive automation authority limits. No one explicitly programmed the Air Canada chatbot to mislead customers, yet someone decided it could speak definitively on refund policies without human review safeguards. The same pattern appears in a Deloitte report that included fabricated citations traced to AI‑generated drafting, and in deepfake scams that leveraged convincing synthetic video to promote fraudulent schemes. In each case, the underlying model behaved as expected: it generated plausible content from imperfect inputs. The real failure was design and governance—systems were trusted as if they were authoritative, without checks proportional to their impact. When organisations treat AI outputs as final decisions rather than draft suggestions, minor model errors become systemic risks. Limiting what AI is allowed to decide, approve or publish on its own is therefore a foundational step in AI incident prevention.
Platforms Turn Local Errors into Systemic Harm
The incident data highlights how platforms magnify AI governance risks. Social media systems appear in 19 percent of cases where a specific AI system was implicated, more than any other category. This does not mean platforms are uniquely reckless; it reflects their power to turn localised problems into large‑scale ones. An AI tool might produce misleading, biased or sensational content. A recommendation engine then optimises for engagement and pushes that content to millions before any human intervenes. For enterprises, this creates a layered risk: internal AI missteps are amplified by external distribution algorithms beyond their immediate control. Businesses that publish or promote content via third‑party platforms need explicit policies for what AI‑generated material can be uploaded, and under what conditions. They also need monitoring processes to detect when recommendation systems are surfacing harmful outputs, so they can respond before those errors become reputational or regulatory crises.
Bias as an Operational Failure, Not Just an Ethics Debate
The AI incident record shows that bias is a concrete operational problem, not merely a theoretical ethics issue. When a specific group is disproportionately affected in documented cases, race is the most common factor, appearing in 16 percent of incidents. Examples include a facial recognition system that led to a wrongful arrest and a kidney function algorithm that underestimated risk for Black patients, altering referrals and transplant assessments. These are not abstract concerns; they are failures in core processes such as policing and healthcare delivery. Weak governance frameworks allowed biased models or flawed data to shape real decisions without adequate scrutiny. Effective AI incident prevention requires governance that treats fairness as a quality metric, enforced through testing, audit trails and escalation paths. Human review safeguards—especially for high‑stakes outcomes—must be designed to detect and override biased recommendations before they translate into lasting harm.
Building Stronger Human‑in‑the‑Loop Governance
The clearest lesson from the 1,406 incidents is that most AI failures are governance failures. Ordinary systems are being given too much authority with too little oversight. Organisations can mitigate this by redesigning workflows around human‑in‑the‑loop controls. For policy‑sensitive chatbots, that means restricting them to verified knowledge bases and requiring escalation to human agents for complex or high‑impact queries. For content and report generation, AI outputs should be treated as drafts that must pass human review before publication or client use. Recommendation engines should be configured with explicit constraints on sensitive categories and backed by monitoring that flags anomalous patterns. Governance policies need to define who is accountable for AI‑assisted decisions, how errors are reported, and how models are updated when issues arise. By narrowing automation authority limits and embedding decision oversight, organisations can reap AI’s benefits while sharply reducing the likelihood and impact of costly failures.