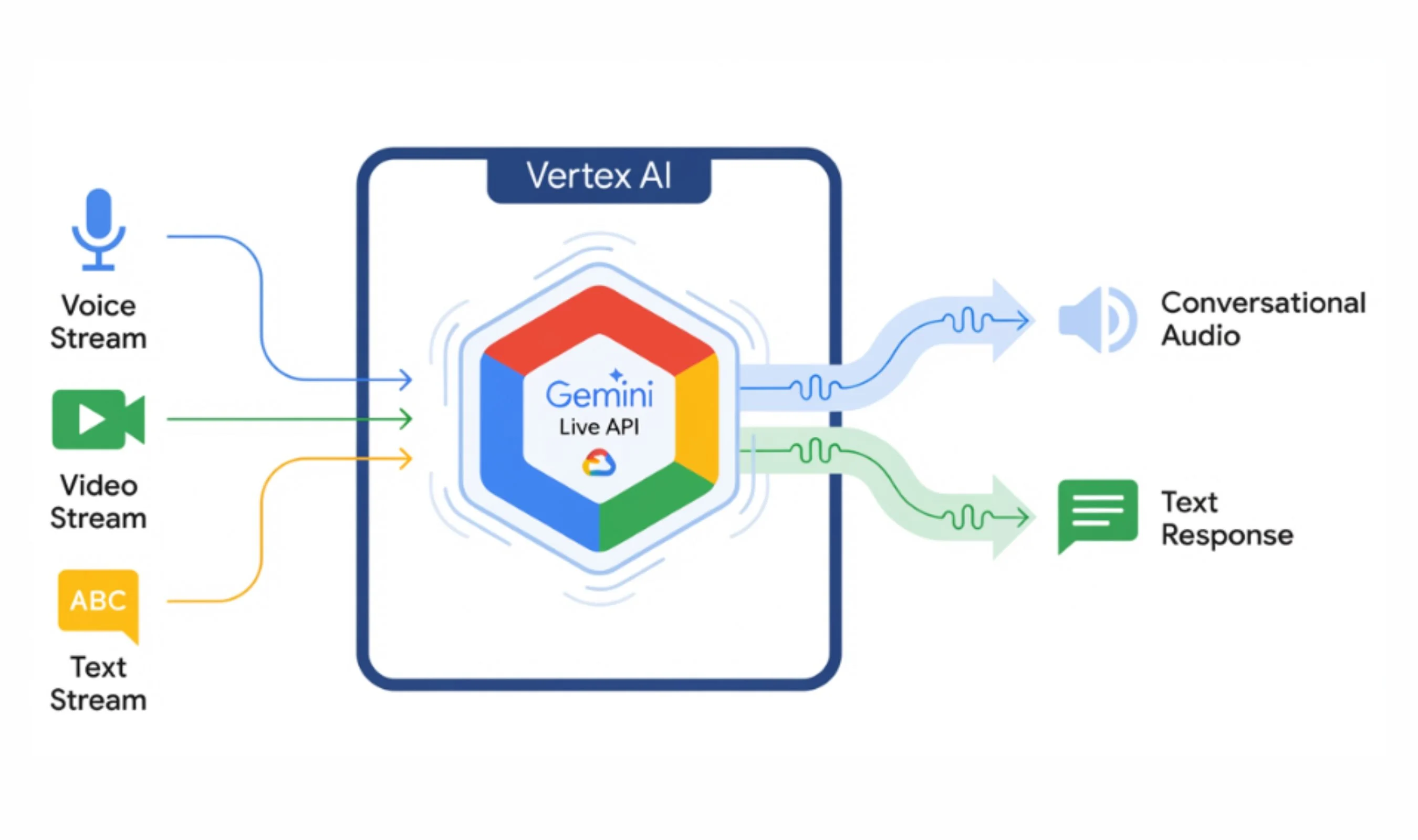
A Hidden Model Selector Reveals Google’s Next Gemini Live Phase
A concealed model selector discovered in Google App version 17.18.22 has quietly exposed the next phase of Gemini Live models. Unlocked behind a server-side flag, the menu lists seven distinct Google AI models for voice conversations: Default, A2A_Rev25_RC2, A2A_Rev25_RC2_Thinking, A2A_Rev23_P13n, A2A_Nitrogen_Rev23, A2A_Capybara, A2A_Capybara_Exp, and A2A_Native_Input. The “A2A” prefix is widely read as Audio-to-Audio, Google’s term for systems that process speech directly instead of routing everything through text. Two models, A2A_Rev25_RC2 and its thinking variant, appeared overnight on May 8, hinting that they are close to public release. Early tests show that each Gemini Live model produces measurably different responses, from how they answer basic queries to whether they can pull live data such as local weather. Together, these clues suggest Google is close to unveiling a more granular, selectable family of Gemini Live models.
The ‘Thinking’ Variant and Capybara Point to Deeper Reasoning
Among the hidden Gemini Live models, one label stands out: A2A_Rev25_RC2_Thinking. While Google has not described it publicly, the name strongly implies enhanced reasoning or deliberation capabilities compared with the standard Audio-to-Audio model. In testing, the models’ behavior backed up that idea, with some showing a more nuanced handling of context and follow-up questions. The Capybara family is equally notable. One Capybara model identified itself as “Gemini 3.1 Pro,” rather than the Flash Live model currently associated with Gemini Live, hinting that Google is already wiring its more advanced stack into live voice. These differences indicate more than simple tuning; they point to a tiered system where a thinking variant AI can be invoked for tougher, multi-step tasks while lighter models handle everyday chat, all under the Gemini Live umbrella.
Personalization, Permissions, and the Architecture Behind Multi-Model Gemini Live
The P13n (personalization) variant of the Gemini Live models shows how far Google is pushing adaptive behavior. When asked for the current time, this model requested the user’s time zone instead of guessing, and it remembered personal details shared earlier, naturally reusing them later in the chat. That stands in contrast to the current default Gemini Live model, which declines to retain such information. Tests also revealed subtle but important capability splits: four of the hidden AI models accessed the user’s location to provide live weather data, while three could not. Crucially, the entire Gemini Live model list is delivered from Google’s servers rather than bundled in the app. That server-side architecture means Google can swap, add, or remove models instantly, making it ideal for live demos, staged rollouts, and rapid experimentation without forcing users to update their apps.
Gemini Omni and Video Push: The Other Half of Google’s AI Bet
In parallel with its Gemini Live experiments, Google is preparing Gemini Omni, a new AI video model surfaced to an early tester via a “create with Gemini Omni” prompt. Metadata links Omni to Google’s Veo foundation, and early experiments show it tackling complex reasoning prompts in video form, such as a professor deriving a trigonometric proof on a chalkboard. The results can look impressively lifelike, though familiar generative glitches still appear, as in a dinner scene where spaghetti materializes on empty plates. Guardrails are clearly tightening: an attempt to recreate the notorious “Will Smith eating spaghetti” test was blocked. The model is resource-intensive; just two video generation requests reportedly consumed 86% of a Google AI Pro plan’s daily usage limit, aligning with Google’s recent move to add explicit Gemini usage caps. Together, Omni and Gemini Live’s hidden models suggest a coordinated push across voice and video.
What to Expect from Google’s I/O 2026 Announcements
The timing of these discoveries strongly hints at major I/O 2026 announcements. Google I/O begins on May 19, and the appearance of RC2-labelled Gemini Live models in early May suggests they are approaching production readiness, not just lab experiments. With a server-driven model list already in place, Google is technically ready to showcase a multi-model Gemini Live experience—perhaps letting users or apps switch between default, thinking, personalization, and specialist modes on demand. At the same time, Gemini Omni points to a future where video generation joins voice as a first-class interface, even if its current costs and usage limits keep it constrained at launch. Layered on top is Gemini Intelligence, recently announced as a system for automating tasks across apps and the web, with Chrome auto-browse arriving in June. All signs point to an AI strategy built on specialized, interchangeable models rather than a single monolithic system.