
What Gemma 4 12B Is and Why It Fits on a Laptop
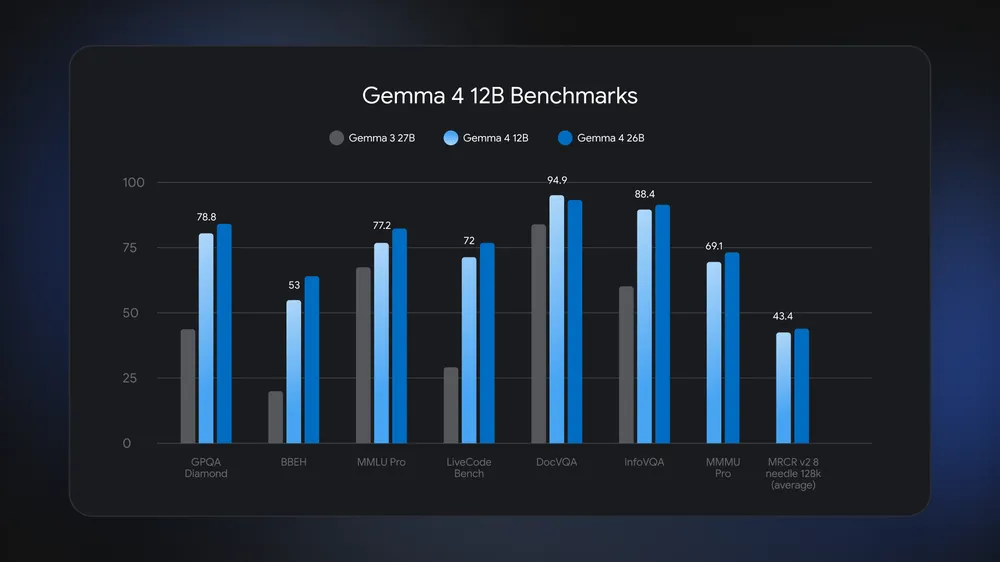
Gemma 4 12B is an open-weights, encoder-free multimodal AI model from Google DeepMind that can run AI locally on a standard laptop, processing text, images, audio, code, and tool calls without needing a dedicated accelerator or cloud connection. Unlike many large models, it is sized for 16GB systems while keeping high-end capabilities. Google positions it as the missing middle of the Gemma 4 family: more capable than phone-class E2B and E4B models, yet lighter than the 26B Mixture of Experts and 31B Dense versions. The weights are released under an Apache 2.0 license and are available on platforms like Hugging Face and Kaggle, weighing just under 18GB. According to Google, Gemma 4 12B “runs on ordinary consumer hardware without giving up quality” and stays close to the 26B MoE on benchmarks while beating the older Gemma 3 27B on tests such as GPQA Diamond, MMLU Pro, and DocVQA.

How Gemma’s Encoder-Free Multimodal Design Works
To make multimodal AI laptop-friendly, Gemma 4 12B removes separate vision and audio encoders and routes everything through a single decoder-only transformer. This unified design keeps the memory footprint low and cuts latency, which is critical for on-device AI inference on 16GB machines. For images, a slim 35-million-parameter vision embedder splits inputs into 48×48 pixel patches and projects them into the model’s hidden space with one matrix multiplication, plus positional information from a factorized X–Y lookup. This replaces the 27-layer vision transformer used in larger Gemma 4 models. For audio, raw 16 kHz waveforms are sliced into 40 ms frames and directly projected into the same token space as text, making Gemma 4 12B the first mid-sized Gemma with native audio input. The same weights serve text, image, and audio, so fine-tuning or LoRA adapters update the full multimodal pipeline in a single pass.

Step-by-Step Gemma 4 12B Setup on a 16GB Laptop
A typical Gemma 4 12B setup on a multimodal AI laptop starts with checking memory: you need at least 16GB of RAM or VRAM to host a quantized model and runtime. Next, download the open weights from Hugging Face or Kaggle and choose a runtime that supports local AI models, such as a LiteRT-LM-based stack or a compatible Python environment. Install dependencies for Gemma-compatible tooling, including tokenizers and any Gemma 4 12B configuration files. Many users will pair the model with Google AI Edge or LiteRT-LM, which are designed for on-device AI inference and can apply optimizations like quantization and multi-threading. Finally, wire up multimodal inputs: configure image preprocessing to 48×48 patches and audio capture at 16 kHz, then register these as input streams. Once configured, you can load the model, warm it up with short prompts, and confirm that text, images, and audio are all flowing through a single local pipeline.
Optimizing Local Inference with Google AI Edge and LiteRT-LM
Running AI locally benefits from runtime optimizations, and Gemma 4 12B is designed to work with Google AI Edge and LiteRT-LM to improve speed and responsiveness. These frameworks target on-device AI inference by optimizing graph execution, memory layout, and scheduling on CPUs or integrated GPUs commonly found in laptops. Gemma 4 12B ships with Multi-Token Prediction drafters enabled, using spare compute to guess several future tokens at once; Google reports up to 2.2× faster inference from this approach in the Gemma 4 family. With LiteRT-LM, you can enable features like low-precision quantization and batch token drafting to push more throughput from the same 16GB system. Because the architecture eliminates separate encoders, the runtime manages a single transformer stack, which simplifies deployment and monitoring. This makes the model suitable for interactive applications such as chat interfaces, code assistants, and multimodal dashboards that must respond promptly without cloud support.
Practical On-Device Agentic Workflows and Use Cases
Gemma 4 12B is designed for on-device agentic workflows where local AI models manage multi-step tasks without a network connection. With Google AI Edge Gallery or similar tools, the model can generate and execute scripts, build webpages, call tools, and handle multimodal context in a single session. For example, Google has shown Gemma 4 12B generating Python code to render PNG charts from natural language instructions, and processing a five-minute Google I/O clip by reading one video frame per second plus audio for combined understanding. Developers can use this model as a local orchestrator to read PDFs, extract tables, summarize meetings from audio, inspect images, and then write code or shell commands to act on those insights. Because everything runs on a multimodal AI laptop with 16GB memory, these workflows avoid latency, privacy concerns, and dependency on remote APIs while still approaching the quality of Gemma 4 26B in many tasks.





