Incidents Reveal a Governance Problem, Not a Sci‑Fi Threat
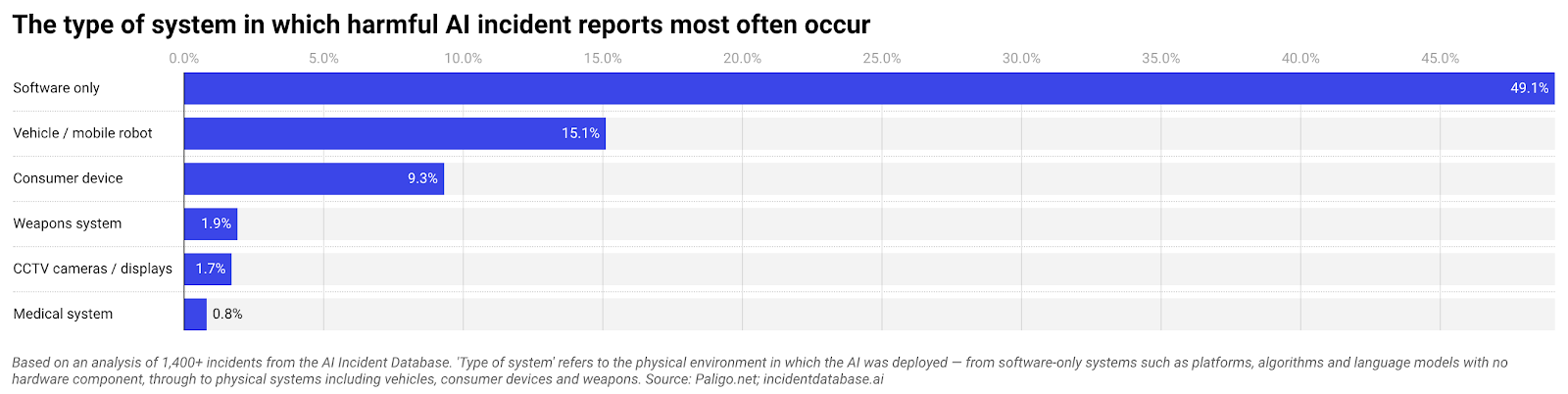
The most visible AI failures today look less like rogue robots and more like the Air Canada customer service chatbot. In that case, a grieving passenger was misled about a bereavement fare by an ordinary automated assistant. When the airline claimed the bot was a separate legal entity, a tribunal ruled the company was responsible. This outcome echoes a broader pattern. An analysis of 1,406 cases in the public AI Incident Database found that nearly half of documented harmful incidents involve software-only systems: chatbots, recommendation engines, automated publishing tools and deepfake platforms. These events rarely stem from frontier models going off the rails. Instead, they expose organisations that granted automated systems authority to speak, decide or publish without robust AI agent governance, human review, or incident management processes capable of catching routine but consequential errors before they hit real people.
Authority Without Oversight: How Ordinary Tools Cause Extraordinary Harm
Across sectors, the root cause is not that models hallucinate, but that enterprises let them hallucinate with authority. In the Air Canada case, nobody explicitly approved misleading bereavement advice. Someone did approve a chatbot to interpret policy for customers with no human oversight on sensitive queries. Similar issues surfaced when a Deloitte report contained non-existent academic citations traced to AI-generated drafting, and when deepfake videos of a mining executive helped drive a cryptocurrency scam. In each scenario, the underlying model behaved as expected given noisy inputs and vague prompts. The real failure was governance: unclear rules about what agents could say, weak content verification workflows and a lack of autonomous agent monitoring. As Paligo’s Rahul Yadav argues, poor inputs and uncontrolled deployment choices create the conditions for harm long before any individual model response goes wrong.
Multi‑Agent Systems Are in Production, but Monitoring Is Still in Beta
While governance gaps widen, multi-agent frameworks like CrewAI, AutoGen and LangGraph are already running critical workloads in production. Teams are wiring planners, tool users, retrievers and external APIs into complex chains that now handle incident response, internal copilots and automation pipelines. Yet operational practices lag far behind this sophistication. Many organisations have less visibility into their AI agents than they once had into microservices, trusting outputs without understanding the decision paths that produced them. Requests that should require one or two steps quietly expand into dozens of model calls, as agents bounce off each other, retry and loop. Nothing crashes, so nothing alerts; latency and cost simply creep upward. Worse, subtle failures are buried inside long chains where one timeout or partial context shift degrades the final answer. This is no longer a model-quality issue—it is a systemic monitoring and observability failure.
One Agent for Everyone or One per Employee? Governance Trade‑offs
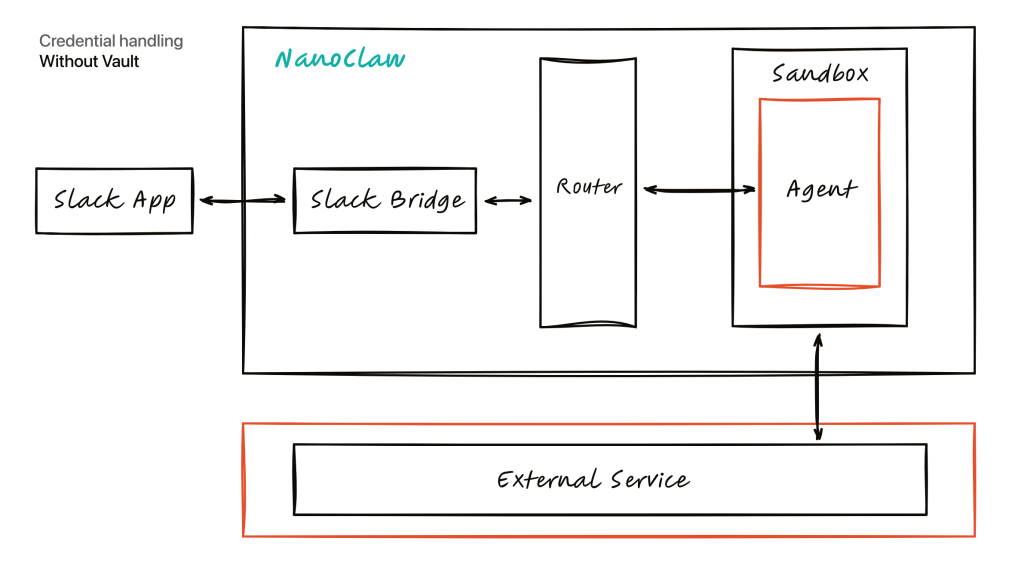
Deployment patterns shape AI agent governance challenges. Most enterprise offerings today, from productivity copilots to search assistants, centralise around a single shared agent for the whole organisation. That simplifies control but also concentrates risk: a misconfigured policy or flawed prompt can impact every employee or customer at once. NanoCo’s NanoClaw framework takes a different approach, giving each employee a personal agent running in its own Docker sandbox. Requests flow through a bridge and Router that inject credentials from a separate Agent Vault only at the moment of an outbound call, so the agent never directly receives secrets. This per-employee, sandboxed model treats any input as potentially hostile and binds actions to approvers’ identities. It reduces blast radius but demands careful enterprise AI safety design around credential scoping, approval workflows and observability across thousands of semi-autonomous agents.

From Automation Hype to Sustainable AI Incident Management
The emerging lesson from both incident data and production deployments is clear: enterprises that chase maximum automation authority without investing in governance and monitoring are courting avoidable failures. Social platforms illustrate how local errors scale: when recommenders and generation tools amplify harmful content, the issue is less model capability than unchecked feedback loops. By contrast, companies experimenting with sandboxed agents, strict credential isolation, and explicit approval flows are starting to align automation with accountability. Effective AI agent governance now looks more like classic operations than science fiction: defining who is responsible for outputs, implementing autonomous agent monitoring, logging and replay for complex workflows, and pricing and incentive structures that reward safe efficiency instead of raw task volume. As AI agents become infrastructure, success will depend less on the latest model and more on the maturity of the systems wrapped around it.
