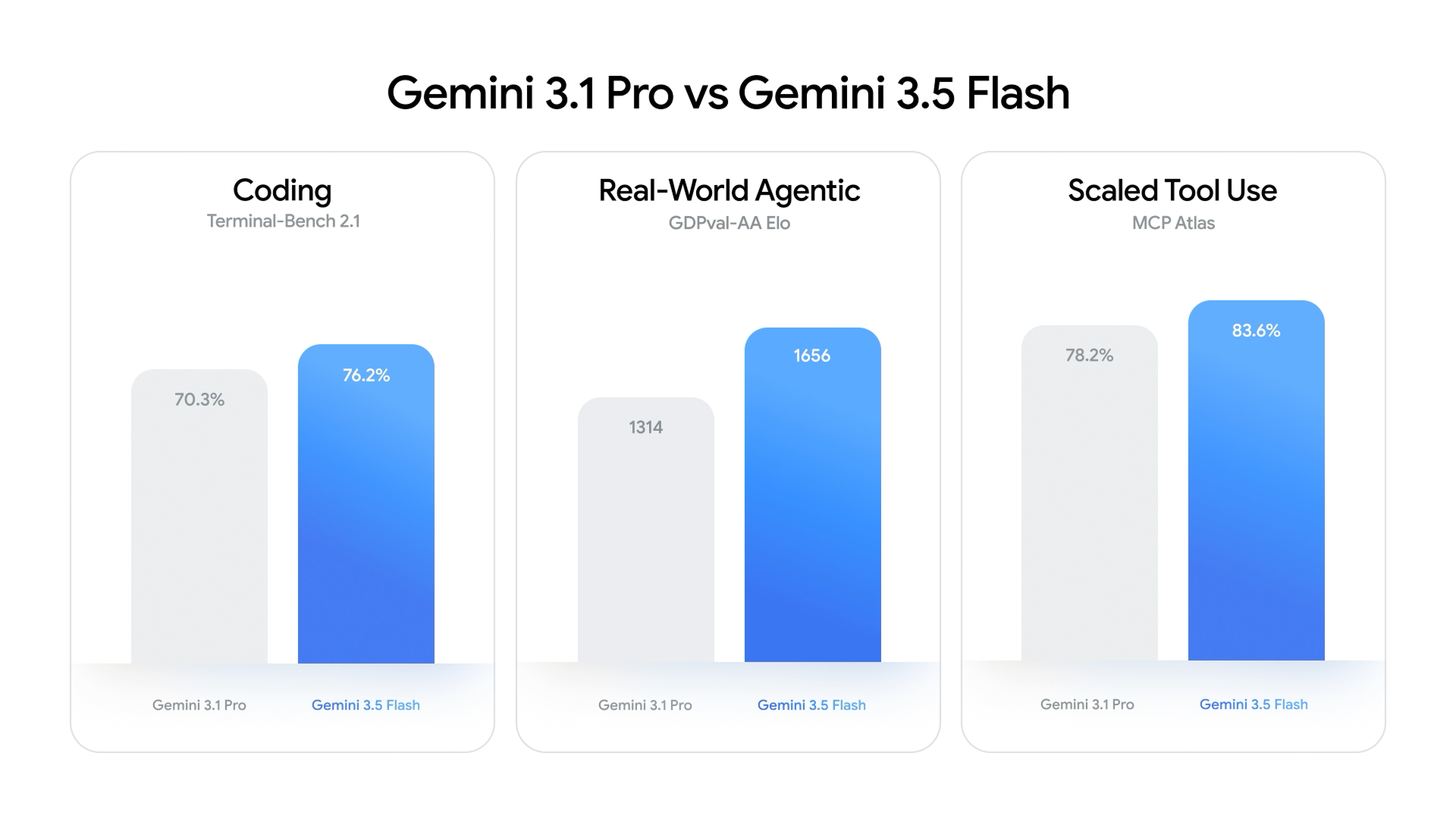
A Flash-Tier Model That Surpasses Pro Benchmarks
Google’s Gemini 3.5 Flash marks a turning point in AI model benchmarks, showing that efficiency-focused models can now rival and even surpass flagship systems. Announced at Google I/O as the default Gemini model, 3.5 Flash is explicitly designed for speed and cost efficiency rather than maximal size. Yet on key tests it beats Gemini 3.1 Pro, which only launched a few months earlier as Google’s flagship. Gemini 3.5 Flash scores 76.2% on the Terminal-Bench 2.1 coding benchmark, compared with 70.3% for 3.1 Pro, and reaches 83.6% on MCP Atlas for scaled tool use, ahead of 3.1 Pro’s 78.2%. On the GDPval-AA Elo metric for real-world agentic tasks, it posts 1,656 versus 3.1 Pro’s 1,314. These results indicate that Pro-grade capability is now arriving in lighter, faster models far sooner than before.
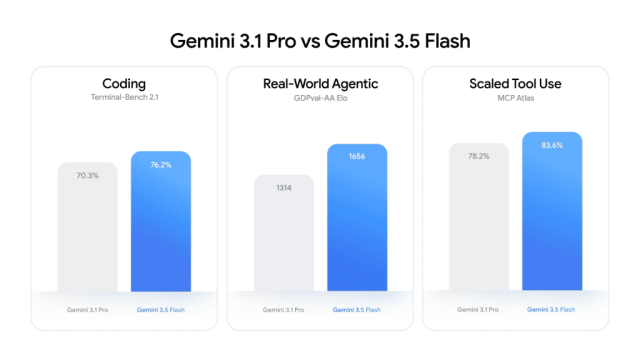
Frontier-Level Coding Performance and Agentic Execution
Gemini 3.5 Flash is purpose-built for coding performance and long-horizon, agentic task execution. It can plan across large codebases, coordinate subagents in parallel, and maintain complex workflows over extended periods. Google highlights its frontier-level intelligence in real-world coding and agent workflows, underscored by its leading scores on Terminal-Bench 2.1 and MCP Atlas. The model also achieves 84.2% on CharXiv Reasoning, reflecting strong multimodal understanding. In practice, partners such as banks and fintechs have used 3.5 Flash to automate multi-week workflows, with the model reliably executing multi-step coding and operational tasks under supervision. This combination of high coding accuracy, sophisticated tool use, and sustained agentic behavior shows that a Flash-tier system can now handle production-grade workloads that previously demanded heavier Pro models, especially for developers whose priorities center on automation and software development speed.
Faster AI Inference Redefines Model Economics
Speed is the defining feature of Gemini 3.5 Flash. According to Google, the model delivers 289 output tokens per second, making it roughly four times faster than other frontier models. That level of faster AI inference changes how developers think about deploying agents at scale. Workflows that once required weeks of continuous processing can now be completed in a fraction of the time, reducing both latency and operational overhead. With 3.5 Flash now set as the default model in the Gemini app and in AI Mode in Search, Google is betting that users will favor responsiveness even when deeper reasoning is available from upcoming Pro variants. For cost-conscious teams, this speed advantage effectively stretches infrastructure budgets, enabling more requests, more experimentation, and more concurrent agents without sacrificing comparable quality on many real-world tasks.
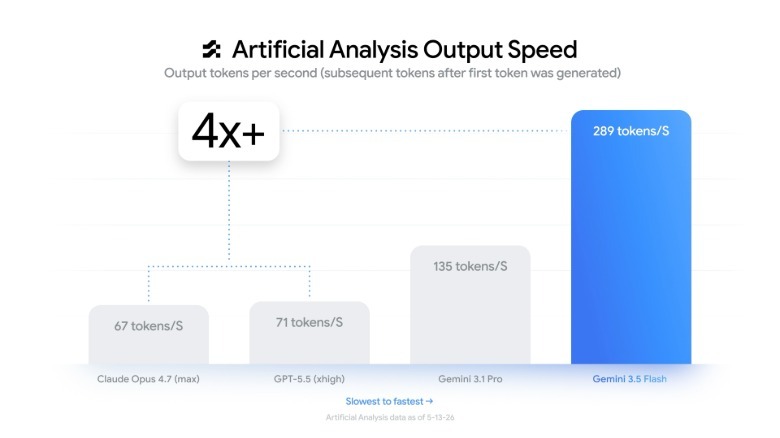
Shrinking Gap Between Flash and Pro Models
The launch of Gemini 3.5 Flash signals a broader shift in how AI capabilities are packaged. Historically, Pro-class models have been synonymous with peak performance, while Flash variants were framed as budget options. Now, the performance gap is narrowing quickly. Gemini 3.1 Pro only recently advanced Google’s standings on major AI model benchmarks. Within roughly three months, a Flash-tier successor is matching and surpassing it on coding and agentic metrics, while also serving as the engine behind Google’s personal AI agent Gemini Spark. Google still positions 3.5 Pro, due soon, as the choice for deep reasoning and high-context tasks. But if this cadence continues, the distinction between “flagship” and “efficient” tiers may keep collapsing. For enterprises, the practical question becomes less about Pro versus Flash branding and more about aligning latency, depth of reasoning, and workload type.
Implications for Developers and Enterprise AI Strategy
For developers and enterprises, Gemini 3.5 Flash reshapes the trade-offs between speed, capability, and cost. Many teams no longer need to choose a slower, heavier model to get strong coding performance or robust agentic behavior. Instead, they can default to a fast, affordable model that already delivers frontier-level intelligence for most day-to-day workloads. This is especially attractive for high-volume applications such as customer support agents, automated code maintenance, and operational workflows that must run continuously. At the same time, Google reports strengthening cyber and CBRN safeguards, aiming to reduce both harmful outputs and unnecessary refusals. With general availability through platforms like Google Antigravity, the Gemini API, and enterprise-oriented services, 3.5 Flash offers an immediate upgrade path. Organizations can start by shifting latency-sensitive workloads to Flash, reserving heavier Pro models for the narrow slice of tasks that genuinely require deeper reasoning.