
What MiniMax M3 Is and Why It Matters for Coding
MiniMax M3 is a frontier coding AI model with a 1 million token context window and native multimodal support, designed to power code-focused agents that can work across large repositories, long-running tasks, and mixed text-image-video inputs in a single system. That framing places it closer to an all-in-one engineering assistant than a generic chatbot. MiniMax positions the MiniMax M3 model as a direct option for developers who need coding AI models that keep state over long sessions, interact with tools, and recover from failed steps instead of stopping at one-shot answers. Rather than targeting leaderboards alone, M3 is built to sit inside daily developer workflows via MiniMax Code, token plans, and API access. For teams already using GPT-4–class or Claude-based AI coding assistants, M3 represents a new family to test for fit, latency, and integration style.
1 Million Token Context: Power, Limits, and Trade-Offs
The headline feature of MiniMax M3 is its 1 million token context window, with a 512,000-token minimum that teams can plan around when sizing workloads. This gives coding agents space to hold sizeable slices of a codebase, design docs, and long task histories at once. MiniMax says its MiniMax Sparse Attention architecture cuts per-token compute at million-token context to one-twentieth of the prior generation, and reports more than 9x faster prefilling and more than 15x faster decoding at that scale. In a separate description, M3’s use of Grouped-Query Attention with MiniMax Sparse Attention is framed as a way to ease the prefill bottleneck that affects long prompts. For developers, the practical question is whether long-context sessions stay responsive and affordable when scanning large repositories, not merely whether the maximum token number looks impressive on paper.
Multimodal AI Coding and Agent Workflows
M3’s multimodal AI coding story is central to how it competes with GPT-4– and Claude-based tools. The model accepts text, images, and video as input while producing text output, which means coding agents can reason over source files, diagrams, UI screenshots, and recording snippets inside one session instead of juggling multiple services. MiniMax is tying this directly to its MiniMax Code product, which supports multi-stage workflows, producer–verifier loops, and computer use powered by these multimodal capabilities. That structure resembles the harnesses around Anthropic’s Claude Code, OpenAI’s coding agents, and Google’s Gemini developer tools. The difference is that M3 was pitched from the start as a frontier model for coding agents and long-running automation. Teams working on complex bug hunts, refactors, or integration tasks can test whether a multimodal, agent-first model cuts context switching and manual glue work between tools.
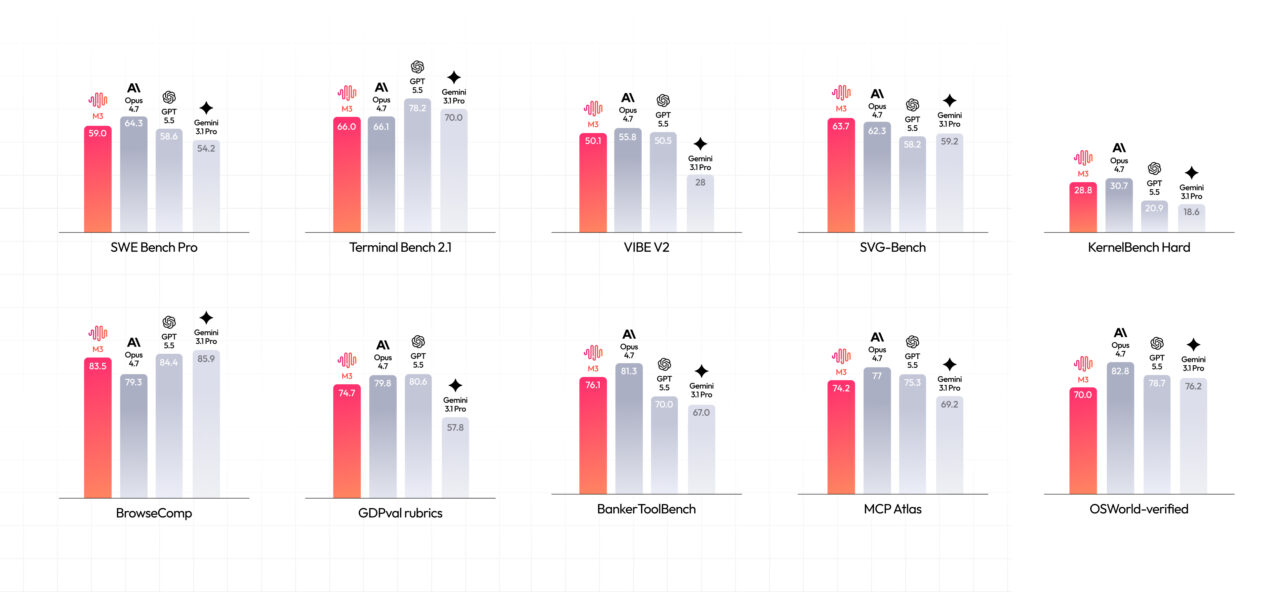
Benchmark Claims Against GPT and Claude
MiniMax backs its claims with a cluster of coding benchmarks, positioning M3 against dominant AI coding assistants. The company reports that M3 scores 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 34.8% on SWE-fficiency, 28.8% on KernelBench Hard, and 74.2% on MCP Atlas, and says M3 beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro while approaching Claude Opus 4.7. It also cites a top score on Claw-Eval, an end-to-end autonomous agent benchmark. However, MiniMax notes that several results were run on its own infrastructure and often with agent scaffolding such as Claude Code, Mini-SWE-Agent, or Terminus. That makes the results informative but not definitive. M3 does not yet appear on DeepSWE’s public board, where GPT-5.5, Claude Opus 4.8, GPT-5.4, and Claude Opus 4.7 currently lead, so a clean comparison on long-horizon software tasks is still pending.
What Developers Should Test Before Adopting MiniMax M3
For developer tool choices, M3’s launch means there is a new contender in a field long defined by OpenAI and Anthropic. API access and an OpenAI-compatible endpoint give teams a way to plug M3 into existing stacks for side-by-side trials with current coding AI models. The coding interface at code.minimax.io and early API availability let teams probe prompt length limits, latency, and tool behavior on real repositories rather than demo snippets. MiniMax has promised to release M3’s weights and a technical report within about ten days, which would unlock more independent evaluation and self-hosting tests. Until those appear, buyers should treat vendor benchmarks as directional. The practical evaluation remains: can a 1 million token context and multimodal pipeline improve review speed, reduce back-and-forth with human maintainers, and fit performance and cost expectations better than incumbent AI coding assistants?





