From Coding Risk to Review Risk
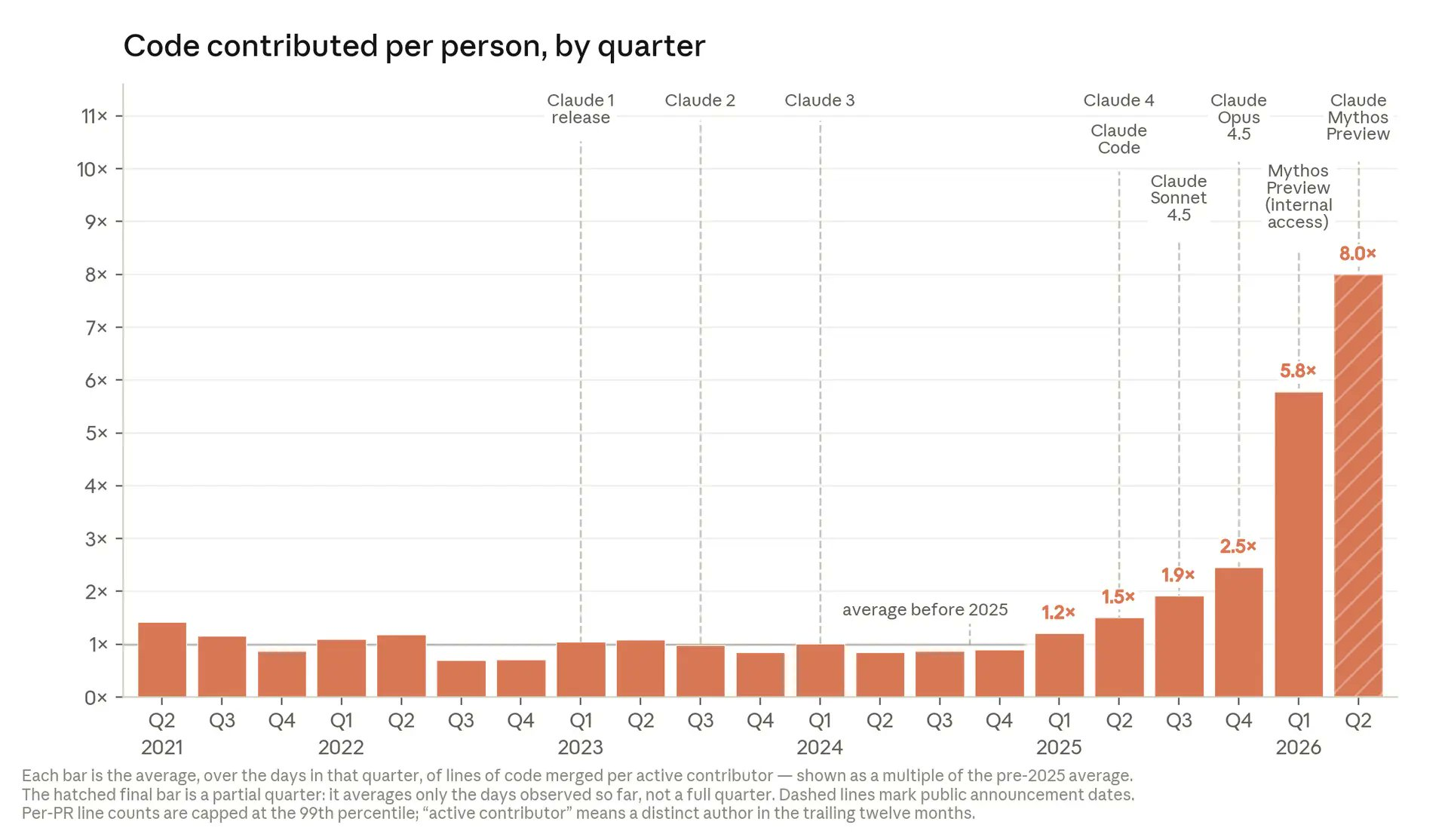
When AI-written production code reaches the majority of a codebase, software risk moves away from human typing mistakes and toward failures in review, testing, and approval workflows that let flawed AI output slip into production. Anthropic says Claude now writes more than 80 percent of the code it merged into production systems in May, which turns its internal stack into a live experiment in AI code generation risks and control gates. Engineers remain “inside the loop”: they choose tasks, inspect diffs, and approve merges, but the volume and speed of change have changed the risk profile. Anthropic also reports that average lines of code shipped per engineer per quarter are now eight times the pre‑2025 baseline, so missed defects can propagate far faster. The central question for teams is no longer whether AI can write code, but whether software quality assurance can keep pace.
Dynamic Workflows: Parallel Agents, Parallel Failure Modes
Anthropic’s new Dynamic Workflows feature for Claude Code pushes this shift further by coordinating many AI agents inside a single coding workflow. Claude can generate orchestration scripts on demand, split work into subtasks, run them in parallel, and validate results before presenting a final answer. This makes it suitable for sprawling tasks such as large-scale migrations, architecture reviews, or security audits that once demanded weeks of human coordination. However, every extra agent and branch of logic increases the complexity of code review automation and human oversight. When AI decomposes and reassembles work autonomously, reviewers must reason about not only the final patch but also the assumptions baked into each subtask. Progress persistence and ultracode settings add convenience, yet they also encourage longer-running, more autonomous sessions where subtle AI errors can compound before any human sees the output.

The rsync Backup Failure: A Cautionary Tale
The recent rsync incident shows what happens when AI-written production code meets critical infrastructure without enough scrutiny. After the 3.4.3 security release, some users found incremental backups failing and falling back to full backups instead, disrupting routine workflows. In the project’s commit history, many changes since 3.4.1 were attributed to “tridge and claude”, meaning rsync creator Andrew Tridgell and Anthropic’s AI assistant Claude. A frustrated GitHub post titled “Please Do Not Vibe Fuck Up This Software” turned a specific bug report into a broader debate over AI-generated code in widely used utilities. Tridgell defended how AI tools were used, but the episode underlined a key point: when a quiet, foundational tool adopts AI-assisted development, the margin for review mistakes shrinks. Failures are not theoretical—they show up as broken backups in production environments.

Speed vs. Software Quality Assurance
Anthropic’s internal metrics highlight both the attraction and the danger of AI-written production code. The company reports that “the average lines of code merged per active contributor has reached 8x the pre‑2025 baseline,” closely tracking Claude model releases. Some engineers even stopped opening traditional code editors and instead rely on Claude Code to draft changes they then edit, showing how deeply AI has entered daily workflows. These gains tempt teams to push for more automation in coding, testing, and code review automation. But more code merged faster means more surface area for hidden defects, security regressions, and subtle behavioral changes. Traditional software quality assurance processes—manual reviews, unit tests, integration suites—were designed for human-scale throughput. Organizations now need to rethink test coverage, prioritize regression scenarios, and treat AI-authored changes as high-velocity input that demands stronger, not weaker, release gates.
Redefining Accountability in AI-Written Code Pipelines
As AI code generation risks grow with tools that can coordinate multiple agents and ship eight times more code, accountability must move from authorship to approval. Anthropic stresses that Claude has not reached full recursive self‑improvement; humans still set tasks and approve production merges. Yet when 80 percent of the code is drafted by a model, “who wrote this bug?” is less important than “who designed the guardrails that failed to catch it?”. Teams need clear audit trails for AI suggestions, mandatory security checks, and straightforward rollback paths for AI-written production code that misbehaves. Ownership should attach to review stages: reviewers, test maintainers, and release engineers become the primary risk managers. The organizations that succeed will be those that treat AI as a high-speed junior engineer whose work is always checked, never auto‑trusted, before it reaches users.





